Q&A
本手册列出数据流3.0组件,在使用中的常见问题和对应自查步骤。
如何进行自查
当节点运行失败,或没有得到期望结果时,需要用户先自行排查,并确定该问题可稳定复现。
在自己无法解决的情况下,可提交工单至产研团队,产研团队会根据工单优先级和提交时间先后,对工单依次处理。
不论是自行排查问题,还是提交到产研,都需要用户提供尽量详尽和完备的信息,这些信息通常可以在curl中获得。
cURL-后端接口(例如debug)
以【调试】为例,后端会触发名为debug的接口。如果您在调试时出现报错,请按照以下步骤复制出curl,提供工单时作为说明信息。
其他调后端接口出现报错的场景,同样可以用这种方法得到对应接口的curl信息。例如保存数据流元素时,会调用update接口,发布时会调用deploy接口等,用户可以举一反三,作为通用的问题排查手段,推荐用户自行了解更多关于浏览器开发者工具的其他知识。
参考步骤:
-
按F12打开检查工具;
-
切到【NetWork】页签,该页签会记录所有后端接口信息;
-
回到系统,复现问题;
-
点击最新的名为【debug】的请求(通常最新的请求在最下面,各浏览器各不相同),切到【Payload】和【Response】页签,截图,工单上附上截图;
-
右键【debug】请求,复制->复制cURL(bash),将得到的cURL粘贴到本地记事本或其他文本处理工具中,在工单中上附上该附件;
参考动图:
cURL-节点日志
若您使用的组件服务节点出现报错或者数据有误(与预期不符),需要排查提交给组件服务的详细数据。
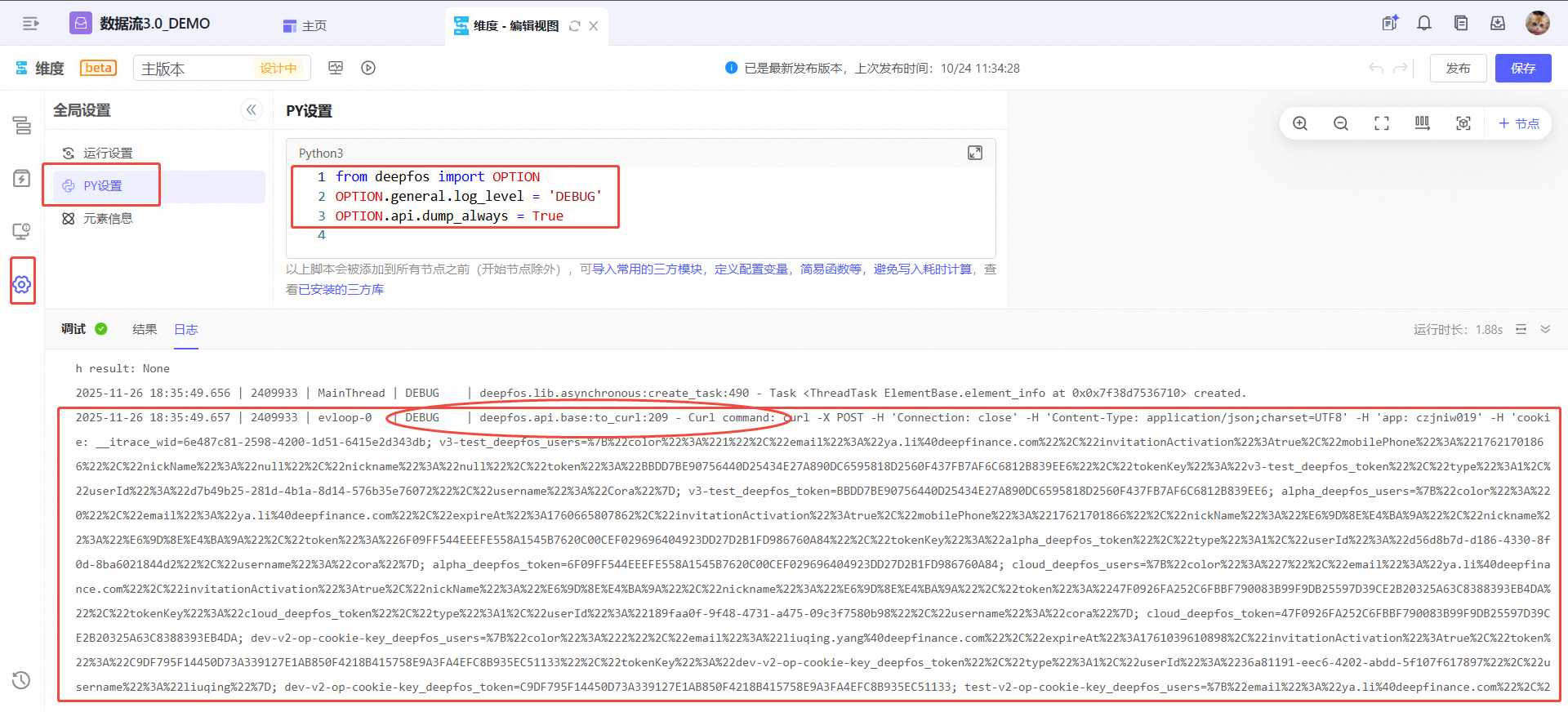
这些数据仅通过debug接口的请求也无法完全获得,需要您在公共脚本中添加一段PY代码,以在该节点的日志中获得调用组件服务的debug级别的日志,包含详细的cURL,包含提交给组件服务的详细数据,您可以排查提交的这些数据是否有误。
代码:
from deepfos.options import OPTION
OPTION.api.dump_always = True
OPTION.general.log_level = 'DEBUG'
详见章节:全局设置 — 使用手册 | DeepFOS Docs
添加公共脚本后,再重新运行节点,节点日志中会包含debug级别的日志,有调用其他组件服务的cURL,复制此节点的所有日志,将其附在工单上。
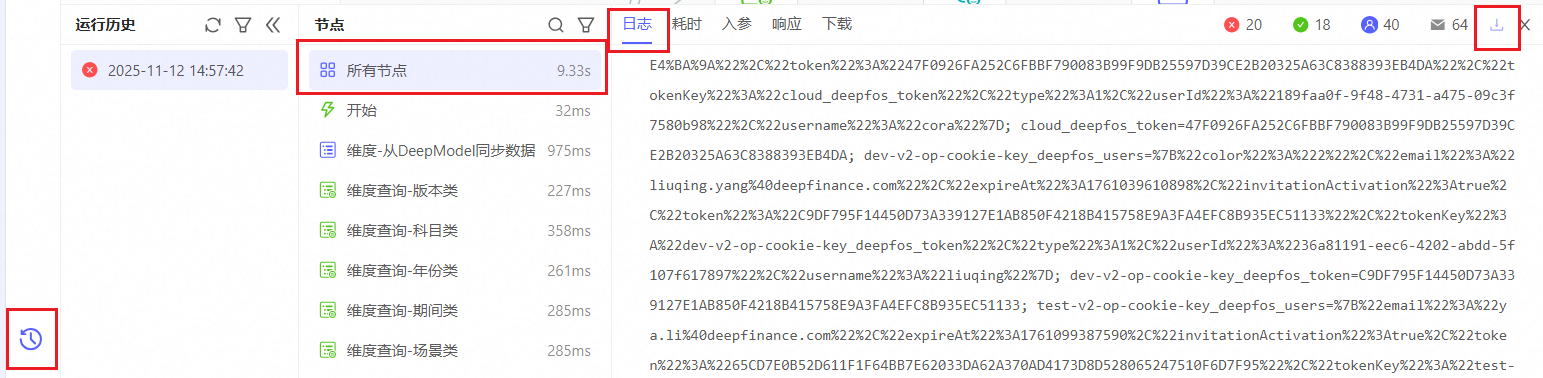
或者重新运行整个数据流,在运行历史中,下载所有日志(txt文件)。
获得版本号
技术排查问题同时需要您提供数据流服务的版本号,多数问题是已知bug,并且已在最新版本中修复,解决这类问题只需要您进行版本升级即可。
您的环境部署的所有服务的版本号,可以通过您的运维人员获取。
也可以通过以下办法,自行快速获得当前服务的版本号(当然也可能由于项目环境的限制,导致以下办法不可行,此时请向您的运维人员获得版本号)。
后端版本号:
详见:https://docs.deepfos.com/operation/method#git-version
-
打开数据流元素;
-
去掉url中第一个问号后面的所有内容(包括问号),这通常是一些查询参数,例如元素编码、文件夹id等信息;
-
在url最后加上
/git-version; -
回车后,浏览器会直接显示版本信息,或者可能是下载一个文件,打开文件后,也可以显示该服务的版本信息。

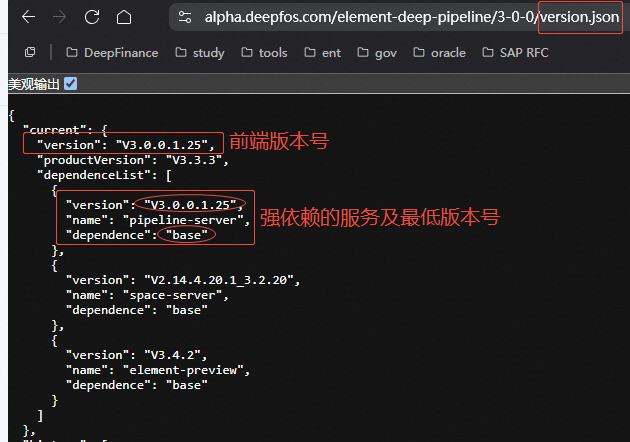
前端版本号:
-
打开数据流元素;
-
去掉url中第一个问号后面的所有内容(包括问号),这通常是一些查询参数,例如元素编码、文件夹id等信息;
-
在url最后加上
version.json; -
回车后,浏览器会直接显示版本信息。
deepfos版本号:
数据流组件用python语言开发,天然集成了deepfos,多数组件服务类型的节点都直接依赖deepfos来实现,若运行出现错误,极有可能是后端组件服务依赖的deepfos版本未更新,因此也需要检查数据流服务的deepfos版本。
-
打开数据流元素;
-
添加
PY代码节点; -
输入以下代码;
import deepfos
return(deepfos.__version__)
-
调试该节点,结果即为deepfos的版本号;
-
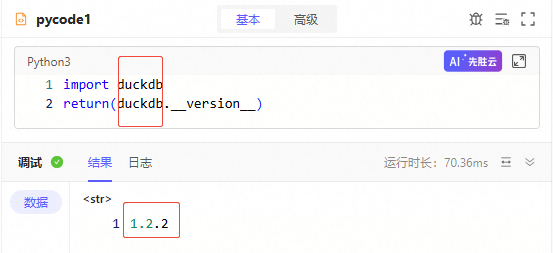
其他依赖的python三方包,也可以用上述步骤检查,例如
duckdb。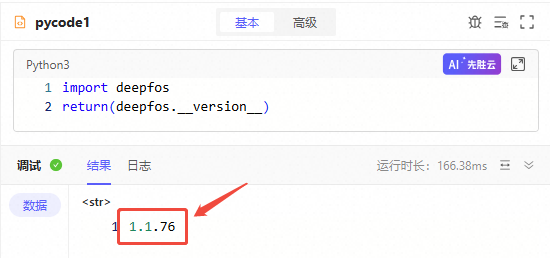
异常类
校验报错
元素保存或者发布时,会进行校验,校验不通过的内容会以表格样式展示在底部,点击每一行可以定位至具体配置处。
用户可以根据校验提示的内容进行修改,修改后再保存或发布。
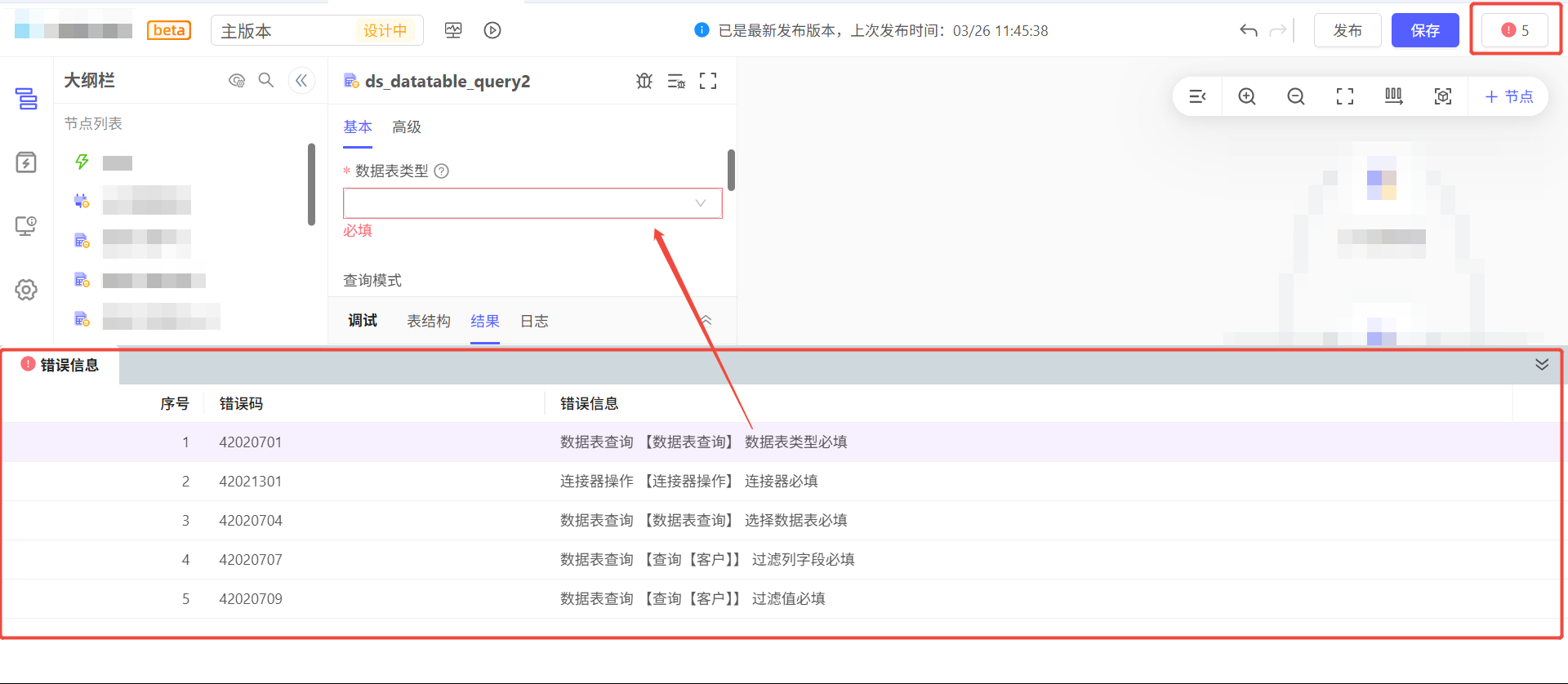
如需查看完整的校验文档(仅供先胜内部成员查看),请联系您的商务人员。
调试/运行报错
|
节点分类 |
节点 |
报错 |
原因 |
方案 |
替代方案 |
|---|---|---|---|---|---|
|
所有 |
This run has been marked as failed from outside the execution context |
grpc服务监听的unix-socket临时文件被操作系统清理了 |
bugfix,升级至3.0.0.1.13之后版本 |
重启服务 | |
|
This run has been marked as failed from outside the execution context |
内存溢出,检查内存使用情况,当内存使用率突然飙升或过大,则会出现此情况,参考工单:issue_05425 |
减少本次操作的数据量,以排查是否数据量级的问题。 | |||
|
数据集查询 |
连接器查询 |
sqlalchemy.exc.OperationalError:(pymysql.err.OperationalError)(1142,”SHOW VIEW command denied to user ‘user_XXX’@’10,20.164.91’for table ‘table_XXX’ |
table_XXX是个视图,用户user_XXX没有 show view的权限。 |
给用户加show view权限 |
用SQL模式查询,此模式不需要查询表结构,不需要执行show create table命令。 |
|
数据表查询 |
polars.exceptions.ShapeError: data does not match the number of columns |
返回的列有重名,数据库(例如MYSQL)没有处理同名字段(例如加后缀) |
需要修改SQL语句,使返回的列不重名,例如不返回重名字段、使用别名 | ||
|
sqlalchemy.exc.ProgrammingError:(psycopg2.errors.UndefinedColumn) column 实际表名.vcic does not exist |
1、检查这张表的列vcic是否存在 |
bugfix,升级至3.0.0.1.25之后版本: |
1、用SQL模式查询,不要用UI模式 | ||
|
DeepModel查询 |
RuntimeError: BindingsError: “Decimal is too large to fit in Decimal128” |
查询结果中有字段的小数位数过大 |
1、添加PY代码节点,用python sdk的 python from deepfos.element.deepmodel import DeepModel dm = DeepModel() dm.execute('''select YourObject{*} limit 1''') 2、定位到是哪个字段的小数位数过大,需要先修复数据&并且以后注意在存数前先确定好小数精度,将DOUBLE类型的数据转DECIMAL | ||
|
财务模型查询 |
截取部分报错内容:nested exception is java.sql.SQLException: Thread stack overrun: 246160 bytes used of a 262144 byte stack, and 16000 bytes needed. Use mysqld –thread_stack=# to specify a bigger stack. |
按配置的维度范围,拼出来的查询SQL超长,以本例的报错内容为例,需要262144 byte,但目前的配置只有246160 bytes |
方案一:缩小维度范围,尽量精确 | ||
|
数据集转换 |
数据转换 |
Parser Error: syntax error at or near “RENAME” |
duckdb版本太低,不支持数据转换底层逻辑 |
duckdb升级到1.2.2: | |
|
LINE 1: select * from (SELECT COLUMNS(c -> c not in (‘_cvrrrkzs’,’_gpzetans’,’_lhcoletu… |
1、检查是否包含了【重命名】步骤; |
bugfix,升级至3.0.0.1.27之后版本: |
使用两个【重命名】步骤,避免在一个步骤中重命名所有的列 | ||
|
duckdb.duckdb.ConversionExceptlon: Conversion Error: Could not convert string ‘XXX’ to TNT32 |
1、检查是否包含了【聚合】等有汇总逻辑的步骤; |
1、检查抛出的’XXX’这个值属于哪一列; | |||
|
获取调试节点【public.节点编码】结果数据失败,报错信息:OutOfRangeException(‘Out of Range Error: STDDEV_SAMP is out of range!”) |
调试结果的【数据】正常显示,但【统计】暂无数据。 |
检查前序步骤(尤其是【列计算】步骤),是否有除以0的情况,建议将被除数=0的情况过滤掉 | |||
|
数据转换-连接 |
SyntaxError:Error:this. |
连接步骤中,选择的数据集的节点编码(其实就是表名),和连接条件中的此表的字段名相同。 |
修改节点编码,使其和连接条件的字段名不相同 | ||
|
PY转换 |
dagster._core.errors.DagsterInvariantViolationError: Unexpected ‘None’ output value. If a ‘None’ value is intentional, set the output type to None by adding return type annotation ‘-> None’. |
python代码没有return |
在代码中加上要return的结果 | ||
|
主键生成 |
pyo3_runtime.PanicException: Arrow datatype Map(Field { name: “entries”, data_type: Struct([Field { name: “key”, data_type: Int32, is_nullable: false, metadata: {} }, Field { name: “value”, data_type: Int32, is_nullable: true, metadata: {} }]), is_nullable: false, metadata: {} }, false) not supported by Polars. You probably need to activate that data-type feature. |
主键生成是走polars处理,本次处理的来源数据中有map类型的数据,polars不支持。 |
检查来源数据集中map类型的数据(可能是STRUCT内套了map,不要漏掉),是否存在取值错误的情况。 | ||
|
单据转换 |
duckdb.duckdb.InvalidInputException: Invalid Input Error: Provided table/dataframe must have at least one column |
提供的【源单据范围】在来源模型中未找到数据,或直接提供了空数组。 |
后端升级:adapter-engine-3-0≥V3.0.0.0.10,升级后可以兼容来源数据为空的情况,不会报错,只返回带目标结构的空数据 |
1、在单据转换前排条件分支,若没有需要进行转换的来源单据,就不执行单据转换节点 | |
|
组件服务 |
组件服务类型的节点(例如财务模型、变量等) |
deepfos.exceptions.APIResponseError: [code: 401] ErrMsg from server: {“code”:500,”message”:”UNAUTHORIZED”,”status”:false} |
被调用服务鉴权失败 |
如果是定时调用,检查定时中配置的流程发起人,确保该用户有对应被调用元素的权限 | |
|
数据保存失败: 获取是否是管理员失败:判断用户是否拥有空间及应用权限:当前admin账号无操作元素权限 |
定时调用,无流程发起人,数据流提供了固定的user_id=1,该user在对应的服务接口中鉴权失败。 |
功能升级,升级至3.0.0.1.24之后版本: | |||
|
deepfos.exceptions.APIRequestError… |
该类节点复用deepfos的逻辑来实现,节点的运行时间超出deepfos设置的api超时时间,导致超时。 python from deepfos.options import OPTION OPTION.api.timeout
|
在全局py中自定义deepfos的超时时间,单位为秒,参考代码: python from deepfos.options import OPTION OPTION.api.timeout = 60000
| |||
|
PY脚本 |
定时调用,报错类似:deepfos.exceptions.APIResponseError: [code: 401] ErrMsg from server: {“code”:500,”message”:”UNAUTHORIZED”,”status”:false} |
在PY脚本中调用了先胜云其他组件的服务,这些服务需要鉴权。 |
在被调用的PY脚本中添加绕过鉴权的代码,详见【启动-定时】章节,或者deepfos文档:异常排查 — DeepFOS | ||
|
定时调用,报错类似:deepfos.api.base:do_request:452 - Call API: http://XX/api/enterprise/list failed because status code is not 2XX. Detail: {“msg”:”拒绝访问”,”path”:”/api/enterprise/list”,”code”:401,”error”:””,”timestamp”:XX}. |
如果是调用PY脚本,尝试手动执行PY脚本是否报错,若不报错,尝试手动执行数据流是否报错,如果也不报错,仅定时调用报错,应该是由于对应服务需要指定用户,但定时调用未指定用户导致 |
功能升级,升级至3.0.0.1.24之后版本: |
1、如果是调用PY脚本,可在python脚本中通过添加OPTION.api.header[‘user’] = ‘xxx_user_id’ 手动指定用户; | ||
|
DeepModel操作 |
TypeError: AsyncDeepModel._collect_bulk_qls() got an unexpected keyword argument ‘error_on_empty_link’ |
数据流组件升级到了3.0.0.1.24之后版本,有【链接字段值不存在时,抛出异常】配置项,但调用的底层deepfos版本未更新,老版本的AsyncDeepModel._collect_bulk_qls()方法没有这个配置项对应的参数,即error_on_empty_link |
更新deepfos到最新版本(≥1.1.76) | ||
|
‘NoneType’ object has no attribute ‘transaction’ |
缺失环境变量EDGEDB_DSN |
联系运维检查环境变量EDGEDB_DSN,确保配置无误 | |||
|
财务模型(提交数据) |
TypeError: argument of type ‘int’ is not iterable |
维度列的数据类型必须是文本,检查是否有列的数据类型是int |
使用【数据转换-列类型转换】或其他方式,将此列的类型转为STRING | ||
|
deepfos.exceptions.APIResponseError: 数据保存失败: 批量查询维度成员失败: 表达式错误,无法识别字符:第1行,第8个字符,extraneous input ‘;’ expecting {‘[’, ANDFILTER, NANDFILTER, ORFILTER, NORFILTER, REMOVE, LEVEL, ILEVEL, CHILDREN, ICHILDREN, DESCENDANT, IDESCENDANT, BASE, IBASE, CODE} |
提交的维度数据中有空值,维度不允许为空 |
检查并修改数据 | |||
|
财务模型(删除数据) |
TypeError: AsyncFinancialcube.delete() got an unexpected keyword argument ‘data_audit’ |
数据流组件服务的前后端已升级,有【记录到数据审计】配置选项,但调用的底层deepfos版本未更新,老版本的deepfos中的AsyncFinancialcube.delete()方法没有这个配置项对应的参数,即data_audit |
更新deepfos到最新版本(≥1.1.76) | ||
|
维度 |
deepfos.exceptions.APIResponseError: 服务异常 |
1、先通过curl检查传给dimension-server1-2/refactor/dimension/member/save这个接口的数据,是否有数据的值是NaN或nan。如何获得调用其他组件服务的curl,请查看章节:获得curl(使用日志) |
在维度提交前,处理来源数据集,确保每列的数值都不为空。 | ||
|
|
deepfos.exceptions.APIResponseError: 接口[http://data-table-deepmode1-server1-0/datatable/execute-sql]调用异常:I/O error on POST request for “http://data-table-deepmodel-server1-0/datatable/execute-sql”: Read timed out |
1、到维度元素页面,新增一条数据,点击保存,看是否同样是转圈后出现超时报错 |
对实际物理表执行ANALYZE命令。 | ||
|
流程服务 |
导出 |
ValueError: Excel does not support datetimes with timezones. Please ensure that datetimes are timezone unaware before writing to Excel. |
导出结果中有带时区的时间类型字段,当前组件暂不支持。 |
升级: |
1、去掉该列; |
|
··· |
··· |
··· |
··· |
调试/运行结果有误
|
节点 |
异常 |
原因 |
方案 |
|---|---|---|---|
|
数据表查询 |
时间类型字段的查询结果,与数据表中的实际数据,有时差。 |
丢时区信息 |
bugfix,升级至3.0.0.1.15之后版本 |
|
导出 |
导出数据丢失一行 |
bugfix,升级至3.0.0.1.25之后版本 | |
|
··· |
··· |
··· |
其他时机报错
保存、发布、导入、点击某些功能时出现的报错。
|
时机 |
报错内容 |
原因 |
方案 |
|---|---|---|---|
|
保存、发布、导入、点击运行历史等 |
调用外部接口返回不符合接口定义,详细:Expect model: ‘typing.List[deep_pipeline.models.flow.FlowElementInfoResp]’, Got ‘··· |
【批量发布】功能的bug,若数据流用了【批量发布】,又在数据转换节点中包含了步骤【列计算-条件(case)】,就会触发此bug。 |
bugfix,升级后端版本: |
|
下载调试结果时 |
服务器内部错误,无法完成请求 |
添加【导出】节点,导出对应数据集,调试【导出】节点,查看对应报错,再去对应节点的异常处理中查找解决方案。 | |
|
点击【财务模型查询】节点时 |
抱歉,页面无法访问··· |
若此节点是跨应用查询,为已知bug |
bugfix,前端升级至3.0.0.1.26之后版本(注意后端依赖),建议直接升级到最新版本 |
|
【连接器查询】节点选择连接器后 |
数据集所需模块未安装,详细错误:No module named ‘cx Oracle’ |
Oracle类型的连接器依赖三方库【cx Oracle】,由于这个库不好装而且只有Oracle类型才需要,因此不在我们标准依赖里。 |
若需要使用Oracle类型的连接器,联系运维人员安装三方库【cx Oracle】 |
|
添加【DeepModel操作】节点后 |
获取数据源信息异常:获取平台数据集信息信息失败, 404 on GET request for “https://os-space-tenant/apis/v3/spaces/nbjoip/actions/datasets/getDefaultBound”:”{“key”:”os.spacetenant.api.datasvc.DatasetNotBound”,”message”:”在Space[xx]下,未绑定符合[services/DeepModel/biz-types/Business]的数据集”}” |
空间中没有DeepModel类型的数据源 |
联系空间管理员添加DeepModel类型的数据源 |
|
··· |
服务异常
服务异常通常为未定位到具体问题的模糊报错,不同使用情况下报的服务异常通常对应不同问题。
|
节点 |
场景 |
页面报错 |
接口报错 |
方案 |
替代方案 |
|---|---|---|---|---|---|
|
数据表查询 |
配置数据源,选择数据表类型 |
服务器拒绝处理当前请求 |
对不起您暂未被授予`Internal Datasource’的操作权限,请联系管理员解决 |
bugfix,升级至V3.0.0.0.1之后版本 |
为当前用户配置【空间管理员】权限 |
|
··· |
··· |
··· |
··· |
··· |
··· |
功能类
多表联查
Q:数据表查询节点能否实现多表联查?
A:可以,使用SQL模式,可以在SQL语句中自行拼接多表进行查询。其他数据集查询类型的节点,例如连接器查询、DeepModel查询同理。
数据库类型
Q:目前支持哪些类型的数据库?
A:对于【数据表查询】、【数据表操作】、【连接器查询】、【连接器操作】等直连数据库的节点,我们对于数据库的支持规划如下。
除了GreenPlun和DB2目前技术上暂未支持外,其余的数据库类型都已经支持,但SapHana、Oracle和SqlServer由于缺乏测试环境或资源,暂未充分测试,可能会出现bug,需谨慎使用,一旦出现bug请联系产品经理处理。
-
SapHana(支持&暂无环境可测试)
-
Oracle(支持&暂无环境可测试),需要安装三方库cx_Oracle
-
SqlServer(支持,数据表查询/操作未测试,连接器查询/操作测试通过)
-
MySQL(支持&测试通过)
-
PostgreSQL(支持&测试通过)
-
Clickhouse(支持&测试通过)
-
KingBase(支持&测试通过)
-
DAMENG(支持&测试通过)
-
GreenPlun(暂不支持)
-
DB2(暂不支持)
deep_pipeline.event_logs表清理
此表用于记录流程实例的日志,若配置的流程日志级别为【详细】,且数据流3.0使用率高,则很容易导致该表占用的磁盘内存过大。
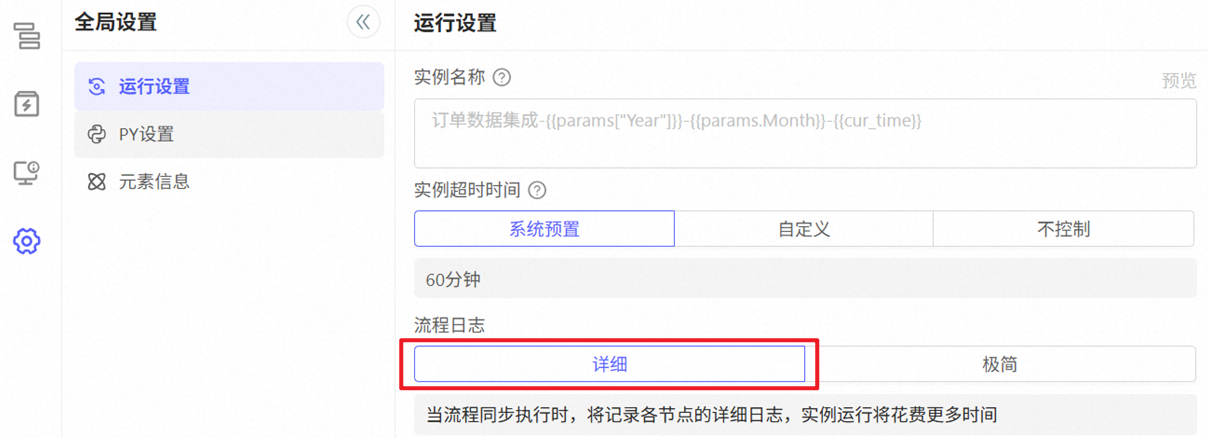
建议:
1、对于使用率高,且不关注日志的流程,流程日志级别改为【极简】(例如只进行数据处理的流程,可以只关注数据结果,无需日志);
2、定时清理event_logs表,建议只清理【成功】状态的实例的日志,例如清理【七天以前】的【成功】实例的日志,可以参考如下SQL。
DELETE FROM event_logs el
USING runs r
WHERE el.run_id = r.run_id
AND r.status = 'SUCCESS'
AND r.create_timestamp < NOW() - INTERVAL '7 days';
数据流间需要传递大数据量的明细数据
入参绝对不要直接使用明细数据!
一个合理的请求体大小是<1MB的,如果强行使用明细数据,请求体一定大于1MB,甚至大于100MB。这将导致带宽占用巨大、超时高概率发生、内存溢出(OOM)、CPU飙升、接口响应极慢或完全无响应等众多致命后果!这是每一位开发人员都应该了解的常识。
错误示例:工单issue_05271
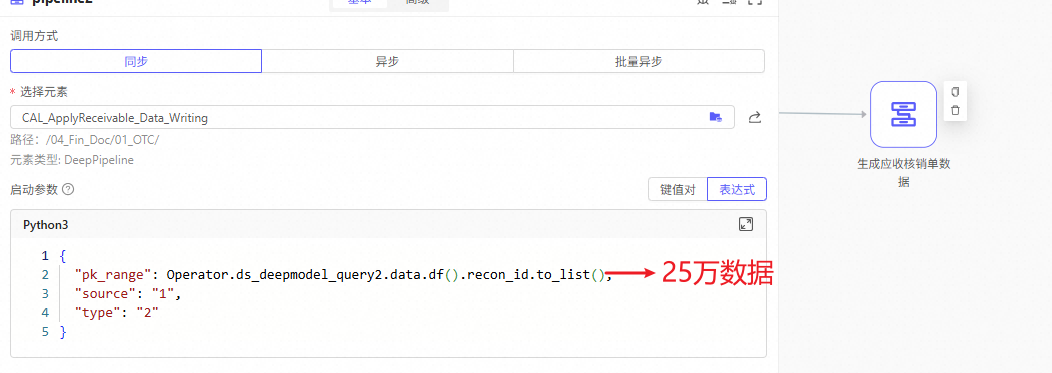
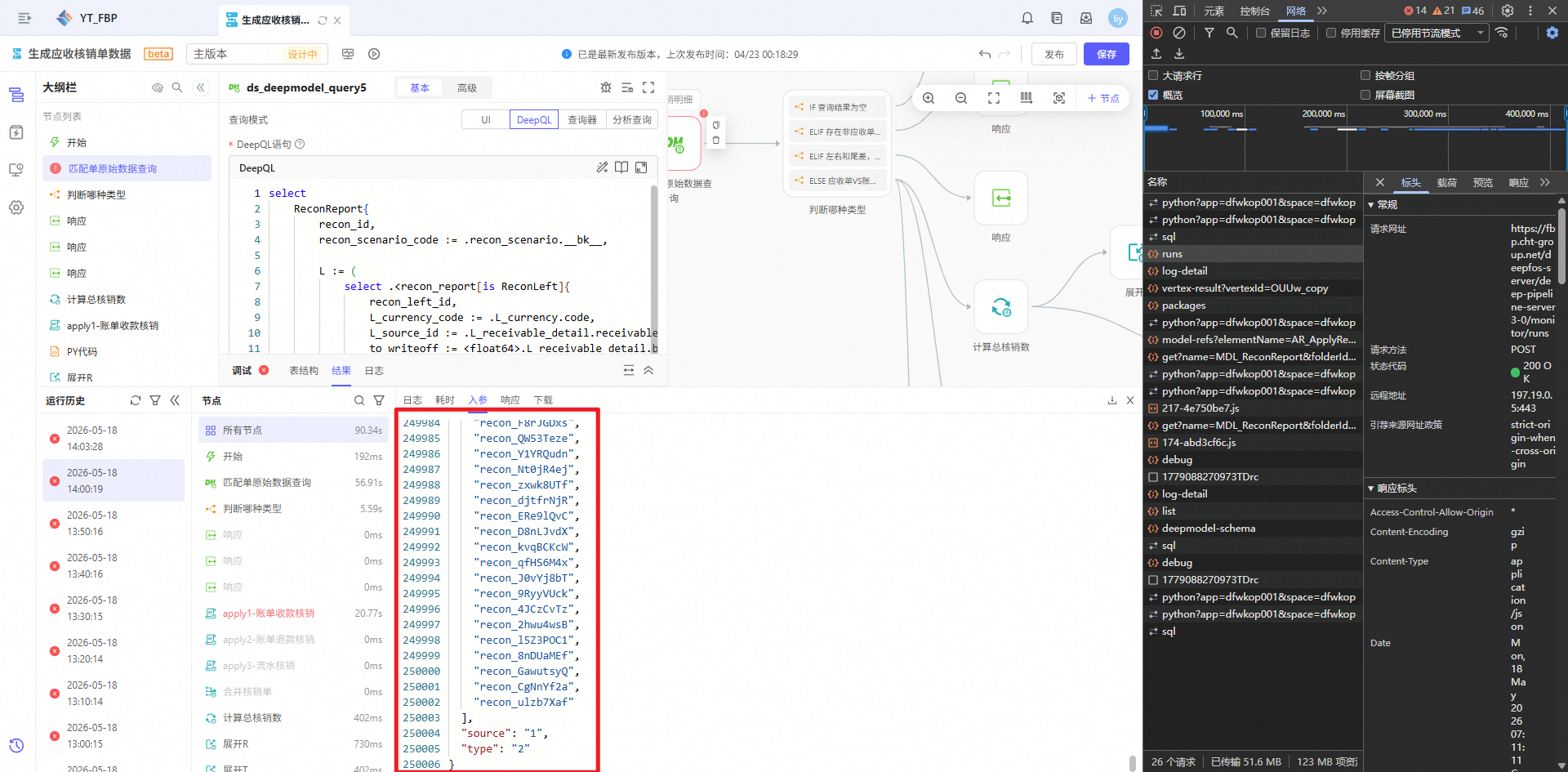
如果你已经使用错误示例中的方式,运行了实例,建议删除这些实例,若流程监控页面已崩溃,请直接用API接口先查询后删除,参考DEMO:demo0505-删除单个数据流元素的实例
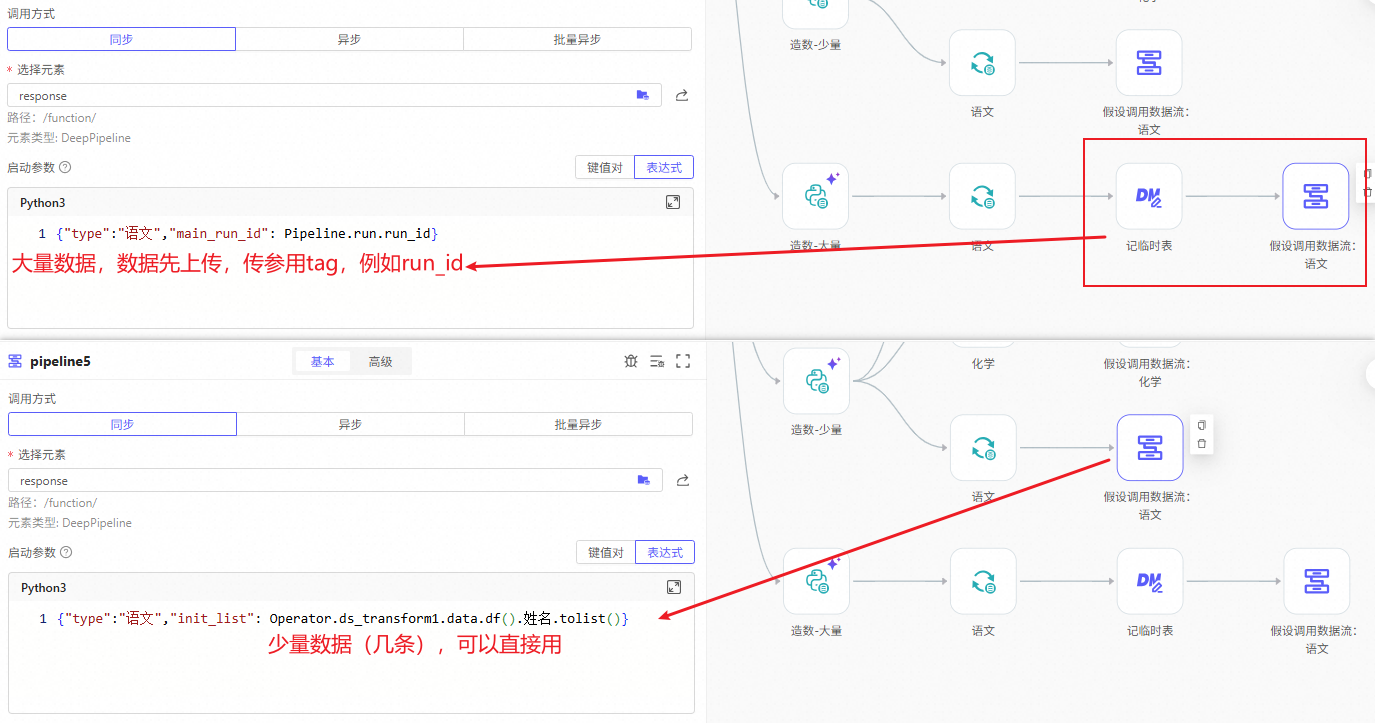
合理的调用方式:
-
分块上传:设计成一次接收1000~5000行(仅供参考),循环调用
-
数据上传:主流程上传数据到临时存储,或永久储存都可以,子流程启动后解析数据
以数据流的特性,我们更推荐数据上传的方式,例如:
-
建一个对象或数据表元素,用来存储要传递的明细数据,可以用主流程的流程实例ID来做标记
-
主流程在调用子流程的前一步,将数据存储到其中
-
被调用的子流程,启动后,根据变量
Pipeline.run.parent_run_id(父流程实例ID),从其中查询出需要的明细数据
参考DEMO:调用数据流
回到顶部
咨询热线
400-821-9199
