常见问题及解答
基本操作
推荐浏览器
请安装较新版本的Chrome64位浏览器,以免一些较新的功能在过老版本的浏览器不能使用

想要在动态表后面还要再插入列,要怎么操作呀
拉到最下面,设置画布大小
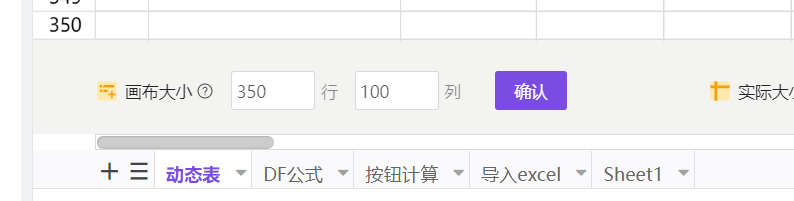
动态表隐藏无数据后,为什么还有这么多空白区域?
电子表格可以设置画布大小,使用态实际大小=max(画布大小,数据区域大小)。如果画布设置的比较大,动态表隐藏无数据后,就会渲染剩余的画布。
解决方案:可以将画布设的小点。
查询按钮的颜色可以换吗?
通过空间主题进行更换:
怎么添加针对每个Sheet的填报说明
电子表格2.0不再提供基于Sheet的说明配置,只提供基于工作簿的说明配置。
若觉得工作簿说明不明显,可自行在Sheet的第一行,添加说明文字。实施建议如下:

动态表
动态表样式配置好后,想要快速复用
大纲树,点动态表脚本,这个部分copy出来后,粘贴进想要复用的动态表脚本
动态表的默认主题可以修改吗?
默认主题界面上不可以随意修改,需要在服务端进行统一配置。
deep-table-server 后端服务增加启动环境变量 EXPORT_DEEP_TABLE_DEFAULT_THEME
配置信息为一个通过“&”分隔的字符串,分隔的每一项为具体的一条配置规则
每一项配置格式如下:区域类型-生效位置-属性名称
区域类型说明:d(动态表区域),f(浮动表区域)
生效位置说明:r(行头),c(列头),d(数据),t(浮动区域边框)
属性名称说明:
-
font 字体
-
0 Times New Roman
-
1 Arial
-
2 Tahoma
-
3 Verdana
-
4 微软雅黑
-
5 宋体(Song)
-
6 黑体(ST Heiti)
-
7 楷体(ST Kaiti)
-
8 仿宋(ST FangSong)
-
12 华文隶书
-
13 PingFangSC-Regular
-
-
fontSize 字体大小 如:12
-
fontWeight 字体加粗(0:不加粗,1:加粗)
-
fontColor 字体颜色 16进制值颜色:如 #FF00FF
-
parentFillColor 父级节点填充色(应用在行头、列头) 16进制颜色
-
baseFillColor 末级节点填充色(应用在行头、列头) 16进制颜色
-
readonlyColor 只读填充色(应用在数据块区域) 16进制颜色
-
editableColor 可编辑填充色(应用在数据块区域) 16进制颜色
-
borderColor 边框颜色 16进制颜色
-
borderLine 边框类型(0:实线,1:虚线)
-
borderType 边框位置(0:上下,1:左右,2:所有,3:上下+粗下框)
例如:
-
动态区域,列,字体颜色配置为“#262626”,那么此项配置为“d-c-fontColor=#262626” 动态区域,数据,只读填充配置为“#007bff”,那么此项配置为“d-d-readonlyColor=#007bff”
支持范围(超出范围,配置无效):
-
动态表支持:行头d-r、列头d-c、数据区域d-d(没有d-t)
-
浮动表支持:列头f-c、数据区域f-d、边框f-t (没有f-r)
支持范围一览表
|
d(动态区域) |
f(浮动区域) | ||||
|---|---|---|---|---|---|
|
r(行头) |
c(列头) |
d(数据) |
t(边框) |
r(行头) | |
|
font |
√ |
√ |
√ |
X |
X |
|
fontSize |
√ |
√ |
√ |
X |
X |
|
fontWeight |
√ |
√ |
√ |
X |
X |
|
fontColor |
√ |
√ |
√ |
X |
X |
|
parentFillColor |
√ |
√ |
X |
X |
X |
|
baseFillColor |
√ |
√ |
X |
X |
X |
|
readonlyColor |
X |
X |
√ |
X |
X |
|
editableColor |
X |
X |
√ |
X |
X |
|
borderColor |
√ |
√ |
√ |
X |
X |
|
borderLine |
√ |
√ |
√ |
X |
X |
|
borderType |
√ |
√ |
√ |
X |
X |
注意:
主题的具体参数可以只配置局部,只需要将想要覆盖的默认主题配置用“&”拼接即可。配置好后,记得重启所有节点服务
例:EXPORT_DEEP_TABLE_DEFAULT_THEME: d-d-readonlyColor=#f2f3f5&f-d-readonlyColor=#f2f3f5 (动态表和浮动行表的数据区域只读颜色修改为较早版本颜色)
若是临时需要仅针对某些表修改局部的话,可以选择一个自定义主题,并修改至同样的配置
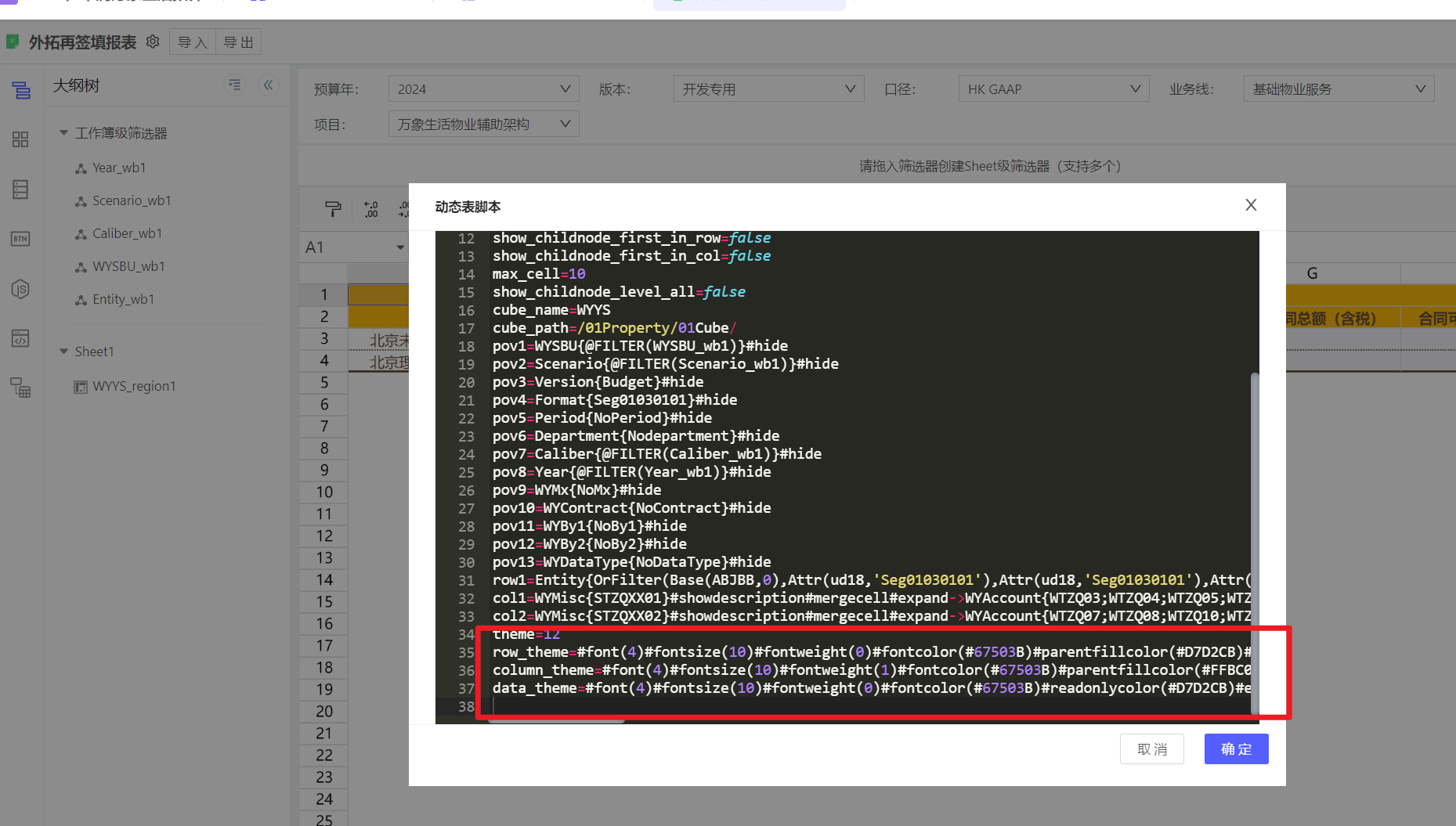
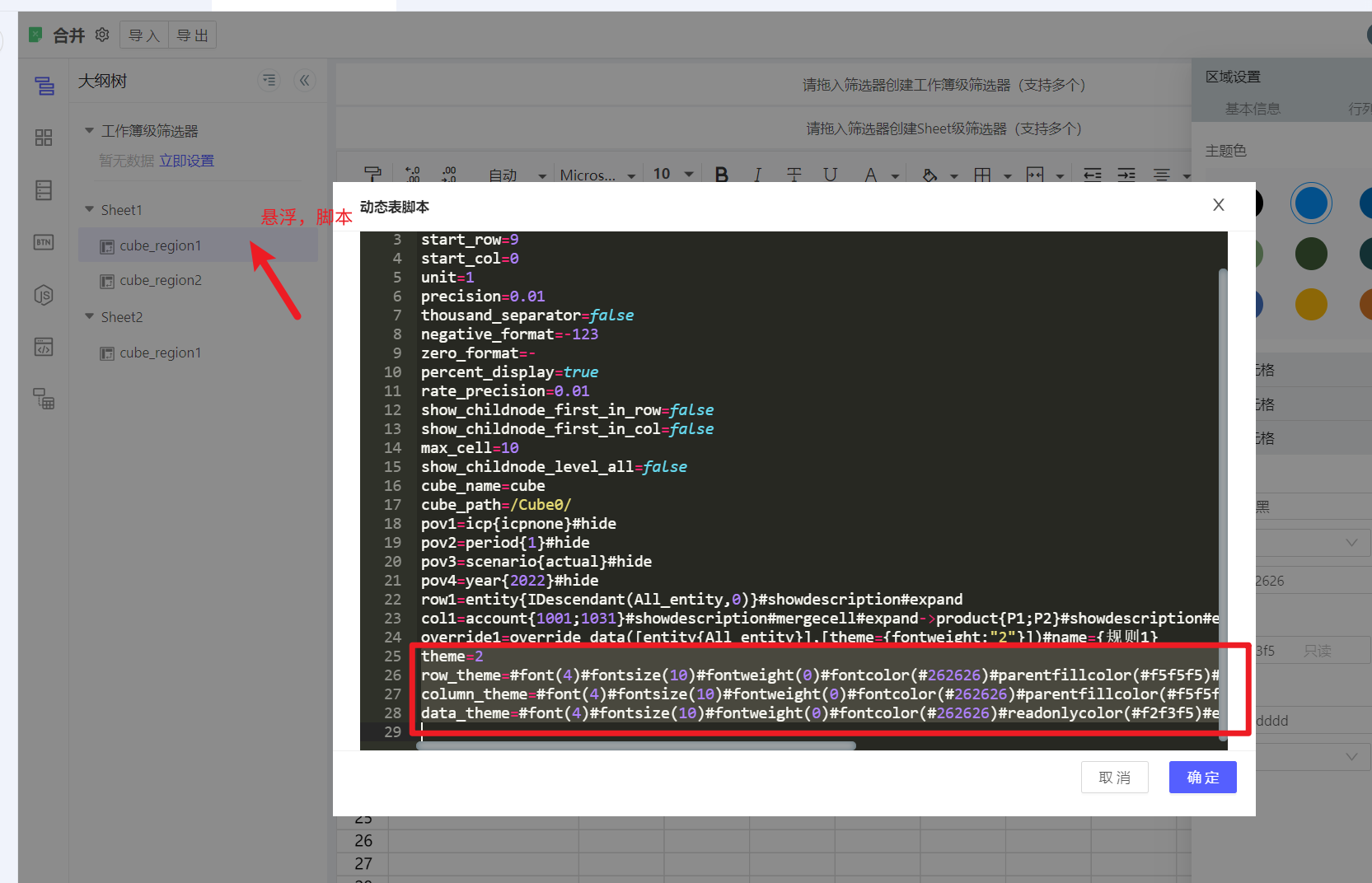
快速操作指南:将下述编码贴进动态表脚本的最后部分,然后点“确定”,再进入到动态表主题配置Tab,按需修改即可。
theme=2
row_theme=#font(4)#fontsize(10)#fontweight(0)#fontcolor(#262626)#parentfillcolor(#f5f5f5)#basefillcolor(#f5f5f5)#bordercolor(#dddddd)#borderline(0)#bordertype(2)
column_theme=#font(4)#fontsize(10)#fontweight(0)#fontcolor(#262626)#parentfillcolor(#f5f5f5)#basefillcolor(#f5f5f5)#bordercolor(#dddddd)#borderline(0)#bordertype(1)
data_theme=#font(4)#fontsize(10)#fontweight(0)#fontcolor(#262626)#readonlycolor(#e8e8e8)#editablecolor(#FFFFFF)#bordercolor(#dddddd)#borderline(0)#bordertype(2)
动态表设置为万元单位,导出的excel没有千分符,且变成了1位小数
Excel本身对于数据单位的处理如下:
|
显示效果 |
Excel数据格式 |
Excel格式释义 |
无千分符格式 | |
|---|---|---|---|---|
|
元+千分符 |
12,345,678,901,234.50 |
#,##0.00 | ||
|
千+千分符 |
12,345,678,901.23 |
#,##0.00, |
末尾1个逗号代表省略3位 | |
|
万+千分符 |
12,345,678,90.1 |
##,#0!.0, |
省去3位后,在1位数字前加小数点 |
0!.0, |
|
百万+千分符 |
12,345,678.90 |
#,##0.00,, |
百万=6位,末尾2个逗号 | |
|
万万+千分符 |
12,345,6.79 |
##,#0!.00,, |
省去6位后,在2位数字前加小数点 |
0!.00,, |
|
十亿+千分符 |
12,345.68 |
#,##0.00,,, |
十亿=9位,3个逗号 | |
|
万亿+千分符 |
12.35 |
#,##0.00,,,, |
万亿=12位,4个逗号 |
因此,尽管在网页上,我们能正常看到万元+千分符+2位小数,但是,由于Excel没有万元和万万元的比较合理的格式支持,表格导出时采用无千分符的格式,最终导出的效果与网页不同。
如果用户对万元表有比较强烈的格式需求,建议将数据直接处理成/10000,报表按元单位进行设置。处理数据的方法有:
2、动态表计算:override成原始数据/10000
3、静态表计算:取出来的数/10000 隐藏原始数据列
4、添加一个通用维度,成员“万元”=成员“元”* 比重0.0001
怎么实现不同维度的成员每列单独隐藏。比如第一/二列只展示Year,第三列只展示Scenario,第四列只展示Misc
电子表格2.0不支持维度标题在不同的行/列上错位隐藏,只能整体隐藏或不隐藏
但是,可以使用excel公式做一个假的表头,具体见下图操作
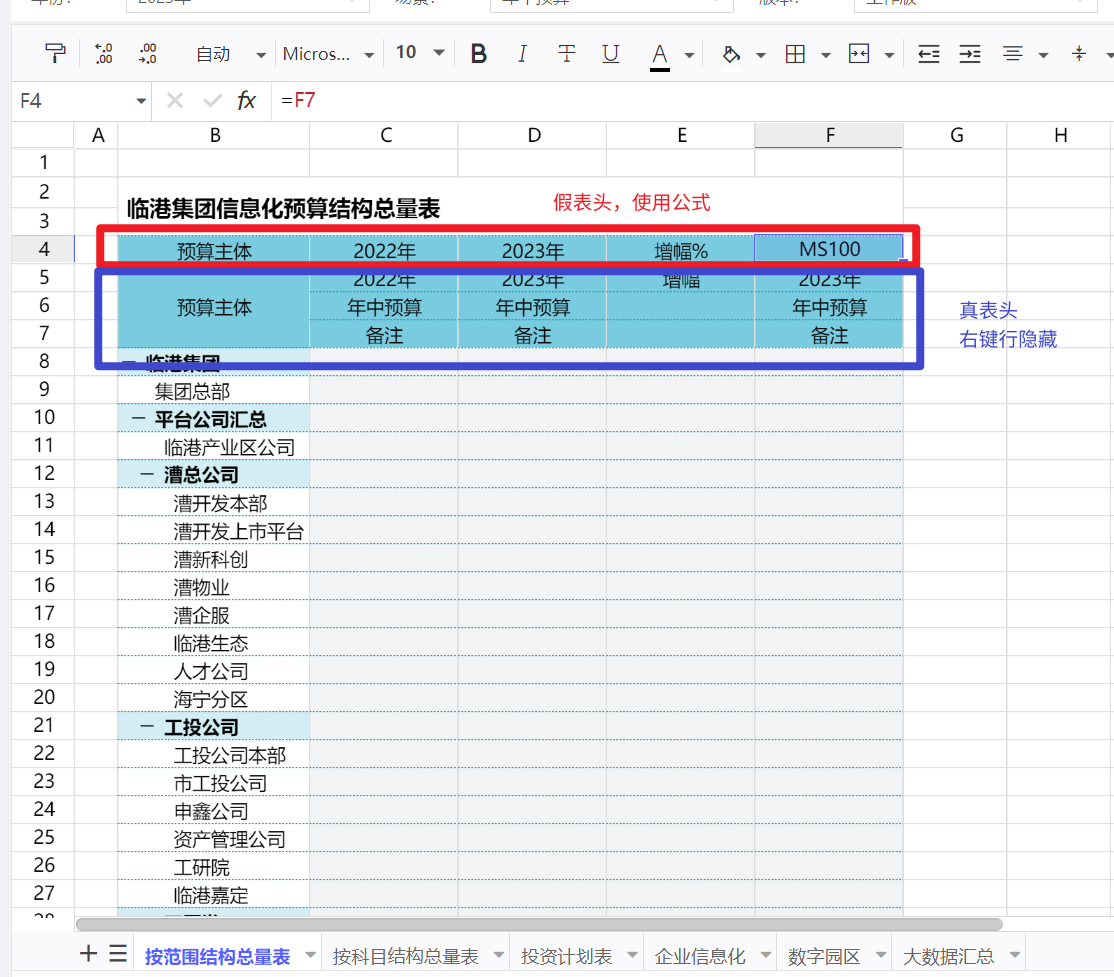
也可以隐藏场景和Misc维度后,用override_header([c4:c4],header=”备注”)
ck cube多个字段关联相同的维度,左上角表头怎么展示不同的描述?

电子表格2.0中,左上角描述显示优先级为:优先使用财务模型字段描述,其次使用维度描述,都没有,使用财务模型字段编码。
因此,如果多个字段用相同维度,只要补上字段描述就可以了。
【查询】按钮 和 【刷新】按钮有什么区别
|
查询 |
刷新当前/全部 | |
|---|---|---|
|
位置 |
查询是跟着筛选器区域出来的,当无筛选器时,也无查询按钮。 |
刷新是跟着标题区域出来的,当标题区域隐藏时,无刷新按钮 |
|
提示 |
随着筛选器的切换动作,查询按钮会高亮提示筛选器值的变化。 | |
|
查询范围 |
当筛选器有变化时,刷新范围为当前表及与变化的筛选器相关的表。 |
刷新当前为当前表 |
用户可根据 筛选区域 和 标题区域的 显隐情况决定使用哪组按钮。
在 筛选区域 和 标题区域 均显示的情况下,也可以自行配置按钮隐藏。
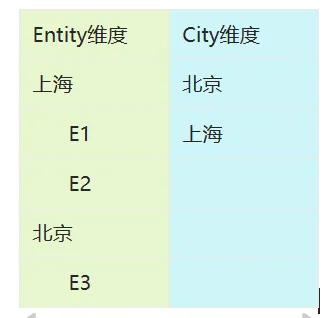
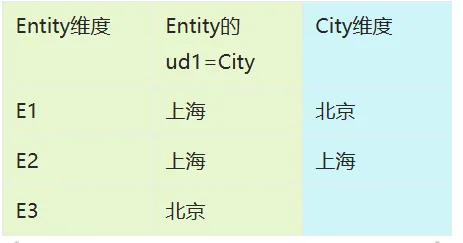
维度表达式
动态表行中,按照维度的ud过滤成员
可使用高级维度表达式
删除方法
从方法1获取的列表数据中去除方法2或者单独某个维度成员,去除的方法2和维度成员可为多个 Remove(方法1,方法2,维度成员名…)
eg: 获取Entity维度#root节点的所有不是末级节点的后代节点,TotalEntity不包含在内
Entity{Remove(IDescendant(#root,0),Base(#root,0),TotalEntity)}
条件过滤
从方法1中获取的列表数据中维度成员的字段属性需要满足某些具体的条件
AndFilter/OrFilter/NAndFilter/NOrFilter(方法1,Attr(属性名,值))
Attr(属性名,属性值)中属性值是否需要单引号要根据当前属性数据库设置的类型来设置,
如ud5为varchar,则Attr(ud5,’1’);若ud5为int,则Attr(ud5,1)
条件过滤有四种情况
1、条件且
满足方法结果并且满足字段属性的值的设定,字段属性可设置多个
eg: 获取Entity维度#root节点下的所有ud5等于1的后代节点
Entity{AndFilter(Descendant(#root,0),Attr(ud5,’1’))}
2、条件或
满足方法结果并且符合字段属性值设定的至少一个条件,字段属性可设置多个
eg: 获取Entity维度#root节点下的所有ud5等于1或者是末级节点的后代节点
Entity{OrFilter(IDescendant(#root,0),Attr(ud5,’1’),Attr(is_base,1))}
3、条件非
满足方法结果不满足字段的值的设定,字段属性可设置多个
eg: 获取Entity维度#root节点下的所有ud5不等于1并且不是末级节点的后代节点
Entity{NAndFilter(IDescendant(#root,0),Attr(ud5,’1’),Attr(is_base,1))}
4、条件非或
满足方法结果并且不符合字段属性值设定的至少一个条件,字段属性可设置多个
eg: 获取Entity维度#root节点下的所有ud5不等于1或者不是末级节点的后代节点
Entity{NOrFilter(IDescendant(#root,0),Attr(ud5,’1’),Attr(is_base,1))}
附:attr属性名相同情况示例
条件且:
-
Entity{AndFilter(IDescendant(#root,0),Attr(ud5,’1’),Attr(ud5,’2’))}:取ud5=1且ud5=2的成员–无成员;
-
Entity{AndFilter(IDescendant(#root,0),Attr(ud5,’1’,’2’))}:取ud5的值在 1和2 范围的成员–ud5=1和ud5=2全包含;
条件或:
-
Entity{OrFilter(IDescendant(#root,0),Attr(ud5,’1’),Attr(ud5,’2’))}:取ud5=1或ud5=2的成员–ud5=1和ud5=2全包含;
-
Entity{OrFilter(IDescendant(#root,0),Attr(ud5,’1’,’2’))}:取ud5的值在 1和2 范围的成员–ud5=1和ud5=2全包含;
条件非:
-
Entity{NAndFilter(IDescendant(#root,0),Attr(ud5,’1’),Attr(ud5,’2’))}:取ud5≠1且ud5≠2的成员–ud5=1和ud5=2全剔除;
-
Entity{NAndFilter(IDescendant(#root,0),Attr(ud5,’1’,’2’))}:取ud5的值不在 1和2 范围的成员–ud5=1和ud5=2全剔除;
条件非或:
-
Entity{NOrFilter(IDescendant(#root,0),Attr(ud5,’1’),Attr(ud5,’2’))}:取ud5≠1或ud5≠2的成员–全部成员;
-
Entity{NOrFilter(IDescendant(#root,0),Attr(ud5,’1’,’2’))}:取ud5的值不在 1和2 范围的成员–ud5=1和ud5=2全剔除;
各控件与筛选器联动的情况(使用维度表达式建立关联关系)
注意,表中@Entity指 源筛选器编码
|
控件 |
功能 |
目标支持:单个值/多个值 |
等于筛选器 |
筛选器+位移 |
筛选器+常规表达式 |
筛选器+高级表达式 |
用筛选器替代Attr成员 |
支持获取源筛选器的UD |
|---|---|---|---|---|---|---|---|---|
|
举例 |
@Entity |
@Entity(+1) |
Base(@Entity,0) |
OrFilter(Base(@Entity,0),Attr(ud1,’A’)) |
OrFilter(Base(@Entity,0),Attr(ud1,’@Year’)) | |||
|
筛选器间联动 |
可选范围 |
多个 |
✅ |
✅ |
✅ |
✅ |
✅ |
Y |
|
默认值 |
多个 |
✅ |
✅ |
✅ |
✅ |
✅ |
Y | |
|
动态表 |
背景维度 |
限定单个 |
✅ |
✅ |
⛔ |
⛔ |
⛔ |
Y |
|
行维度 |
多个 |
✅ |
✅ |
✅ |
✅ |
✅ |
Y | |
|
列维度 |
多个 |
✅ |
✅ |
✅ |
✅ |
✅ |
Y | |
|
UD维度 |
多个 |
✅ |
✅ |
✅ |
✅ |
Y | ||
|
行/列fx公式 |
限定单个 |
✅ |
✅ |
⛔ |
⛔ |
⛔ |
N | |
|
override命中(左边) |
多个 |
✅ |
✅ |
✅ |
✅ |
⛔ |
Y | |
|
override_member覆盖成员 |
限定单个 |
✅ |
✅ |
⛔ |
⛔ |
⛔ |
N | |
|
override_fx覆盖公式 |
限定单个 |
✅ |
✅ |
⛔ |
⛔ |
⛔ |
N | |
|
|
DFdata |
限定单个 |
✅ |
✅ |
⛔ |
⛔ |
⛔ |
N |
|
DFdatafx |
限定单个 |
✅ |
✅ |
⛔ |
⛔ |
⛔ |
N | |
|
DFfilter |
限定单个 |
✅ |
✅ |
⛔ |
⛔ |
⛔ |
N | |
|
|
筛选条件 |
多个 |
✅ |
⛔ |
✅ |
⛔ |
⛔ |
Y |
|
逻辑属性_维度 |
多个 |
✅ |
✅ |
✅ |
✅ |
✅ |
Y | |
|
字段的默认值 |
限定单个 |
✅ |
⛔ |
⛔ |
⛔ |
⛔ |
N |
上述表达式的具体使用业务场景举例,见下一问。
当筛选器传递过来多个值时怎么解析?
1、大多数情况下,电子表格使用复制整个表达式的方式进行解析
-
比如Base(@筛选器,0),筛选器的值等于A1,A2,解析后的结果为:
-
Base(A1,0);
-
Base(A2,0)
-
-
如果筛选器出现在Attr函数中,OrFilter(Base(@筛选器1,0),Attr(ud1,’@筛选器2’)),@筛选器1=A1,A2 @筛选器2=B1,B2 解析后为:
-
OrFilter(Base(A1,0),Attr(ud1,’B1’));
-
OrFilter(Base(A1,0),Attr(ud1,’B2’));
-
OrFilter(Base(A2,0),Attr(ud1,’B1’));
-
OrFilter(Base(A2,0),Attr(ud1,’B2’));
-
—–多个筛选器计算笛卡尔积
-
2、仅有Remove表达式的第2+个参数存在例外:
-
remove第1个参数是筛选器,remove整体复制;第2+个参数是筛选器,不做remove复制,仅参数内部复制
-
比如 remove(idesendent(@筛选器1,0),base(@筛选器2,0),@筛选器3) @筛选器1=A1,A2 @筛选器2=B1,B2 @筛选器3=C1,C2 结果是:
-
remove(idesendent(A1,0),base(B1,0),base(B2,0),C1,C2);
-
remove(idesendent(A2,0),base(B1,0),base(B2,0),C1,C2)
-
筛选器间联动功能说明
筛选器联动存在两种情况:
-
筛选器间联动:也就是使用筛选器值的是另一个筛选器(关于筛选器间联动的注意事项见下表)
-
其他控件(比如动态表,浮动行表)引用筛选器的值:支持范围见上表,在可支持的前提下,表达式基本上与筛选器间联动一样。
注意事项:
1、筛选器间联动范围:
-
工作簿级:可选其他工作簿级筛选器
-
Sheet级:可选工作簿级筛选器 及 本Sheet的 其他Sheet级筛选器(不可选其他Sheet的Sheet级筛选器)
-
筛选器之间的联动关系不可以成循环。
2、引用筛选器不要求源和目标是同一个维度,只要传过来的值及表达式,在目标控件对应的维度内可存在即可
3、筛选器的默认值:
-
普通模式下,筛选器的可选范围是不变的,默认值仅在首次开表时生效
-
联动模式下,可选范围是变的,默认值在每次可选范围变动后都要重算 。
-
默认值本身算法保持不变:本身可配置表达式,但是需要符合:在可选范围内,不超过多选数量的成员。若未配默认值,则为第一个。
4、支持源筛选器多选,但是引用筛选器的控件若只能接受单一值,则取源筛选器返回值的第一个值
场景举例及具体表达式写法
|
编号 |
维度结构 |
场景描述 |
目标控件的维度表达式 |
备注 |
|---|---|---|---|---|
|
1 |
|
通过选择City,返回Entity的下级成员 |
Entity_wb1: Base(@City_wb1,0) |
假设源筛选器是City维度,目标控件是Entity筛选器(实际也可以是动态表Entity维度等),下同 |
|
2 |
|
通过选择City,作为Entity维度的过滤条件 |
Entity_wb1: OrFilter(Base(#root,0),Attr(ud1,’@City_wb1’)) | |
|
3 |
|
通过选择Region,作为Entity维度的过滤条件 |
需要增加City筛选器作为中转 |
筛选器多级联动 |
|
4 |
|
通过选择Entity,返回City成员 |
City_wb1: @Entity_wb1.ud1 |
需开启源维度的返回UD功能 |
|
5 |
|
通过选择Entity,返回City成员,并继续计算City的各类表达式 |
City_wb1: Base(@Entity.ud1,0) |
其他表达式不一一举例了 |
|
6 |
|
通过选择City,获得Region,并作为Entity的过滤条件 |
Entity_wb1: OrFilter(Base(#root,0),Attr(ud2,’@City_wb1.ud1’)) |
与Case3的区别是需要返回City的UD值 |
|
7 |
|
返回Entity的父级 |
Entity_wb2: @Entity_wb1.parent_name |
新增隐藏功能:即使在筛选器返回UD中未勾选,也可以使用 |
|
8 |
|
返回Entity的本位币 |
Currency_wb1: @Entity_wb1.local_currency |
可使用任意标准属性:可通过维度的td表查看属性名 |
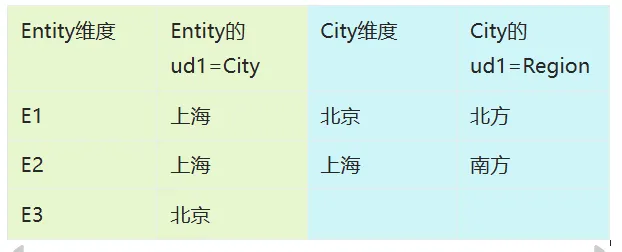
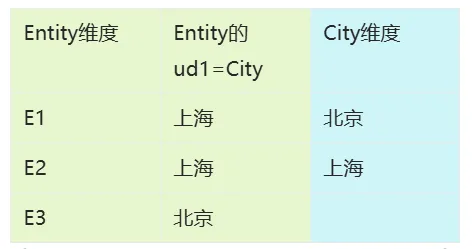
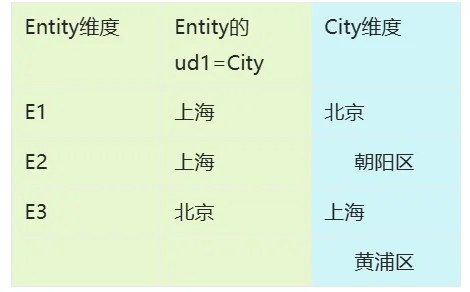
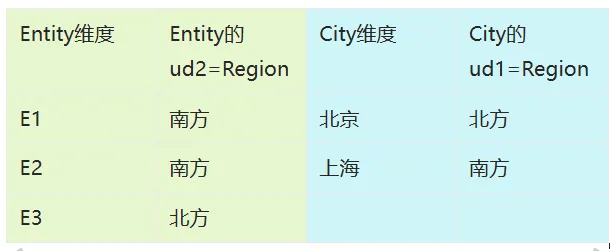
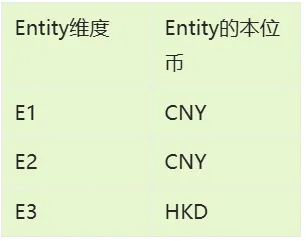
注:需要提供UD的源筛选器需开启
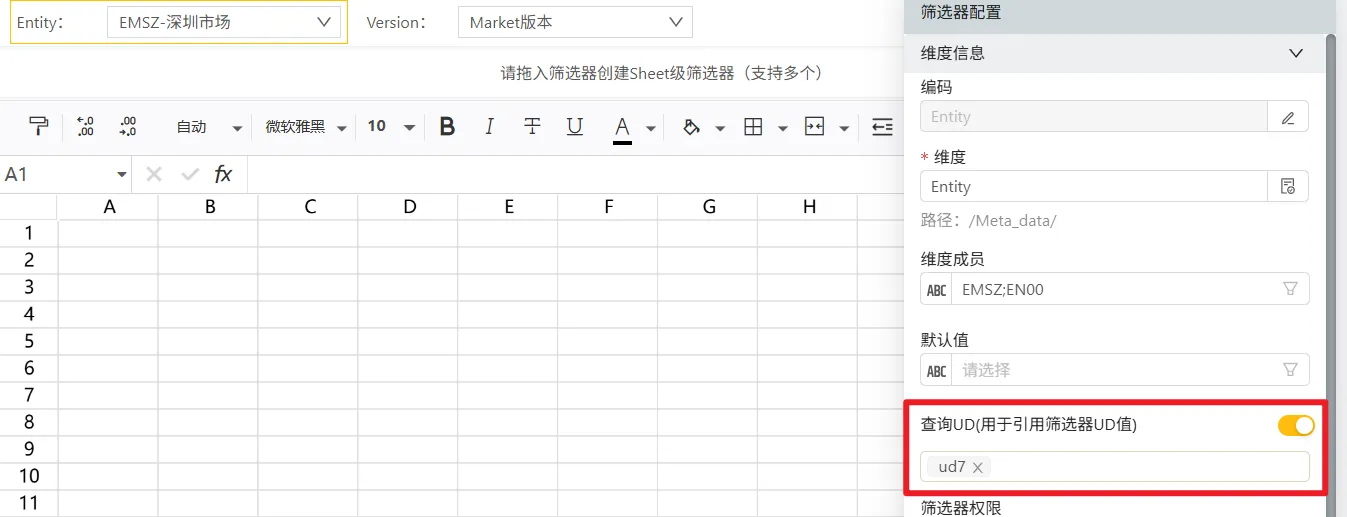
注:若筛选器之间的关系无法通过维度表达式来表达,可通过自定义JS实现
增加了加载筛选器后/开表前JS执行时间点,可通过JS对筛选器的可选范围和值进行修改,避免报表需要二次查询的问题
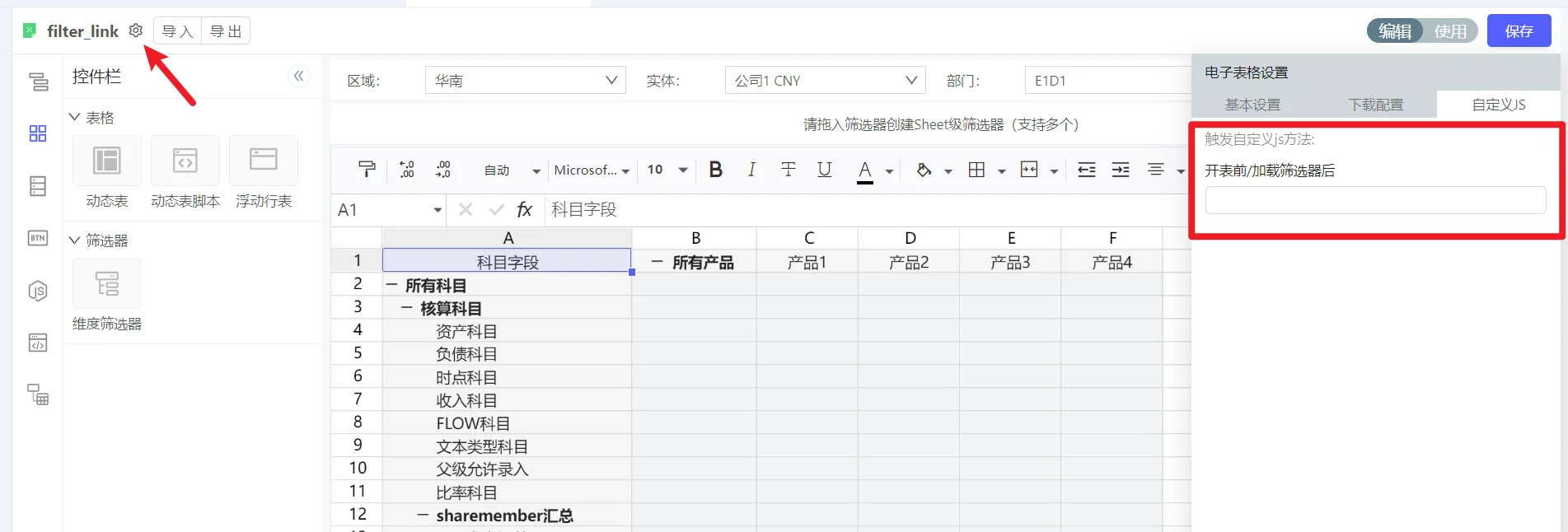
关联了筛选器后,能在对应动态表列上展示@Cur-1吗
动态表成员引用筛选器时叠加位移-1就相当于@Cur(-1) ,在2.0中的表现方式为@Year_wb1(-1)
1.0中的 @Cur 全都用 @筛选器 功能替代
动态表中,滚动预测时,是否可以根据变量期间(举例3月),显示1-3月为实际场景数,(4-12月)显示预测数。
可以通过增加Period层级结构,以实现此需求。
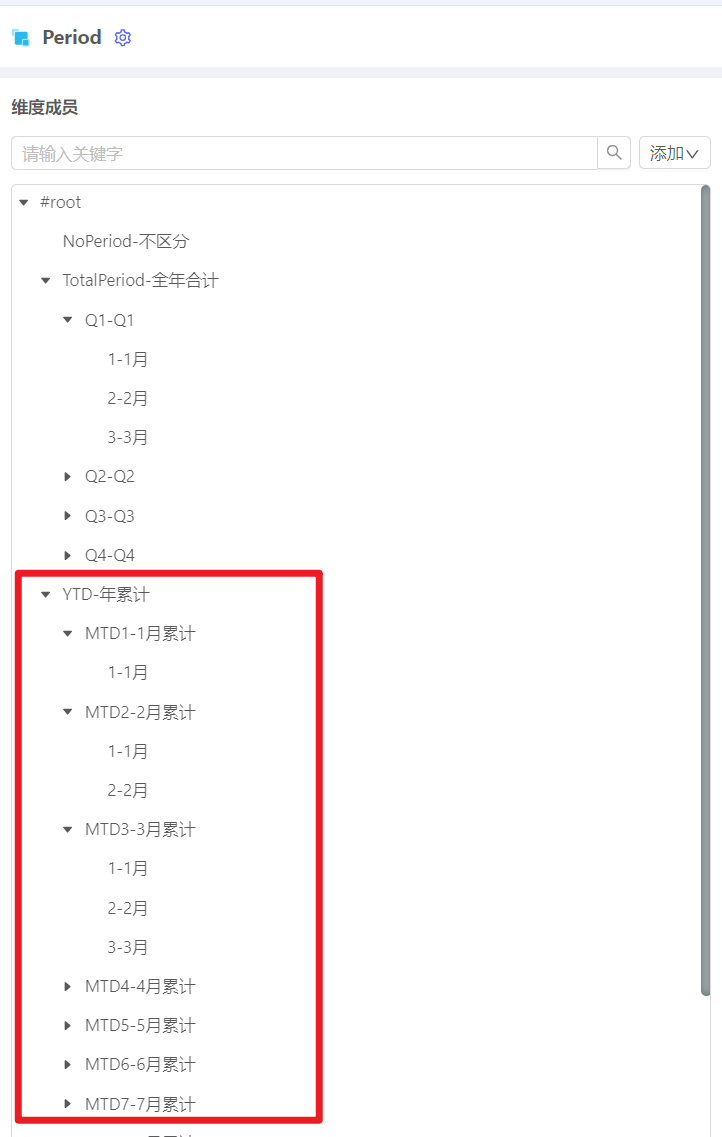
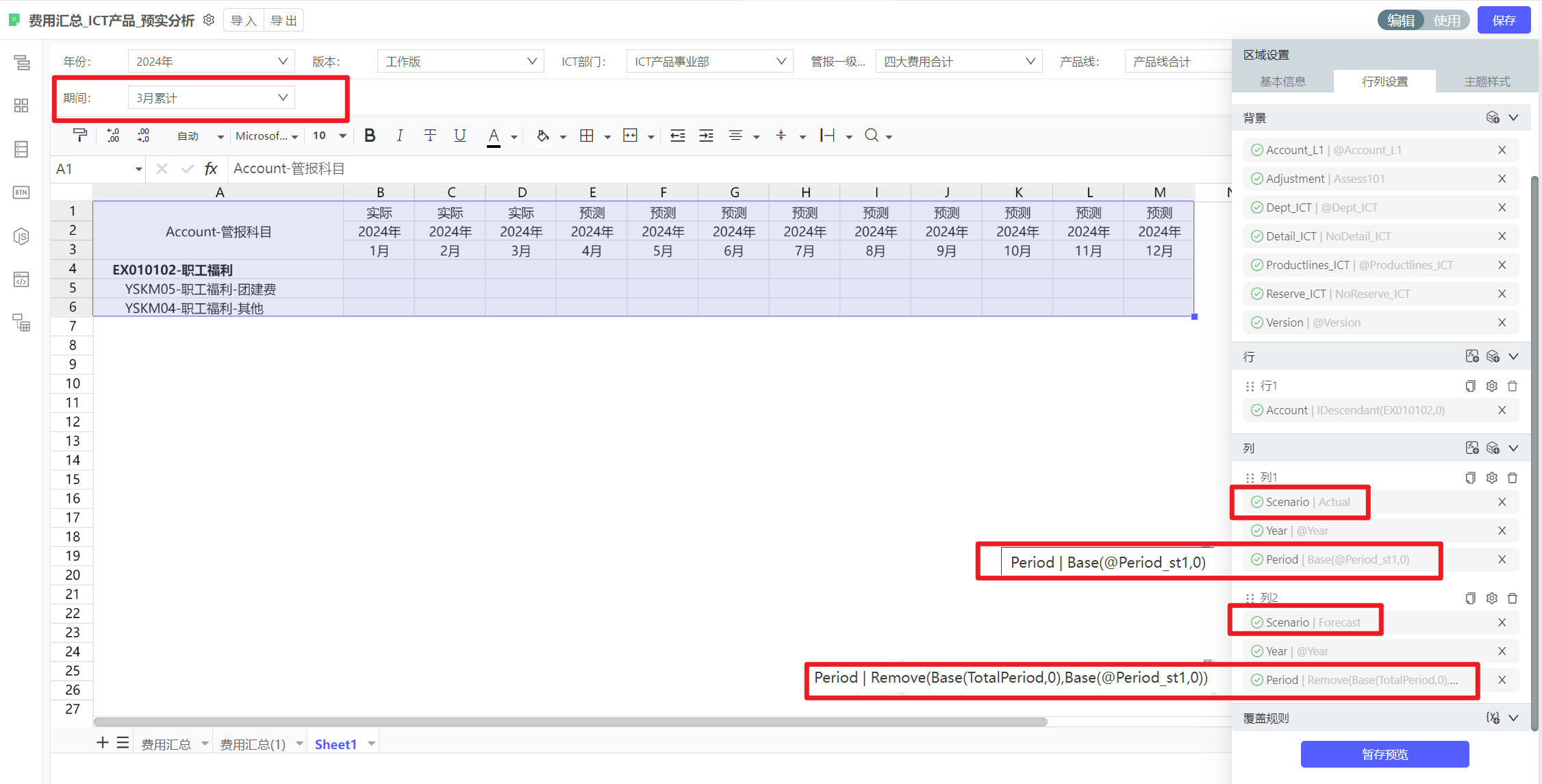
当场景为实际时,Period为所选月份的Base成员;
当场景与预测时,Period为所有期间-所选月份的Base成员
PS:若为静态表,可以直接将场景维度成员放在单元格上,使用Excel公式计算某个期间对应的场景是实际还是预测,然后DF函数直接引用单元格值作为维度成员。
动态表中,维度表达式配置了倒序,区域配置了汇总节点在下方,倒序没有效果
在维度表达式中,可以修改第二个参数,以达到正序或倒序的效果
比如:Descendant(维度成员名,排序方式(0/1))
但是,如果此时表格同时启用,汇总位置向下或向右,倒序就没有效果。
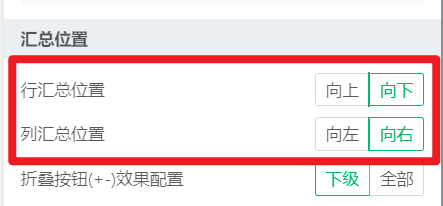
倒序算法:所有成员倒着排;汇总位置算法:子成员正排汇总节点在下。
这两种算法是冲突的,维度侧后处理汇总位置,因此,就体现为倒排没有效果。
编制报表时,从通用的科目树形下,挑出了个别科目(不同的表有不同组合),怎么实现+-和缩进效果。
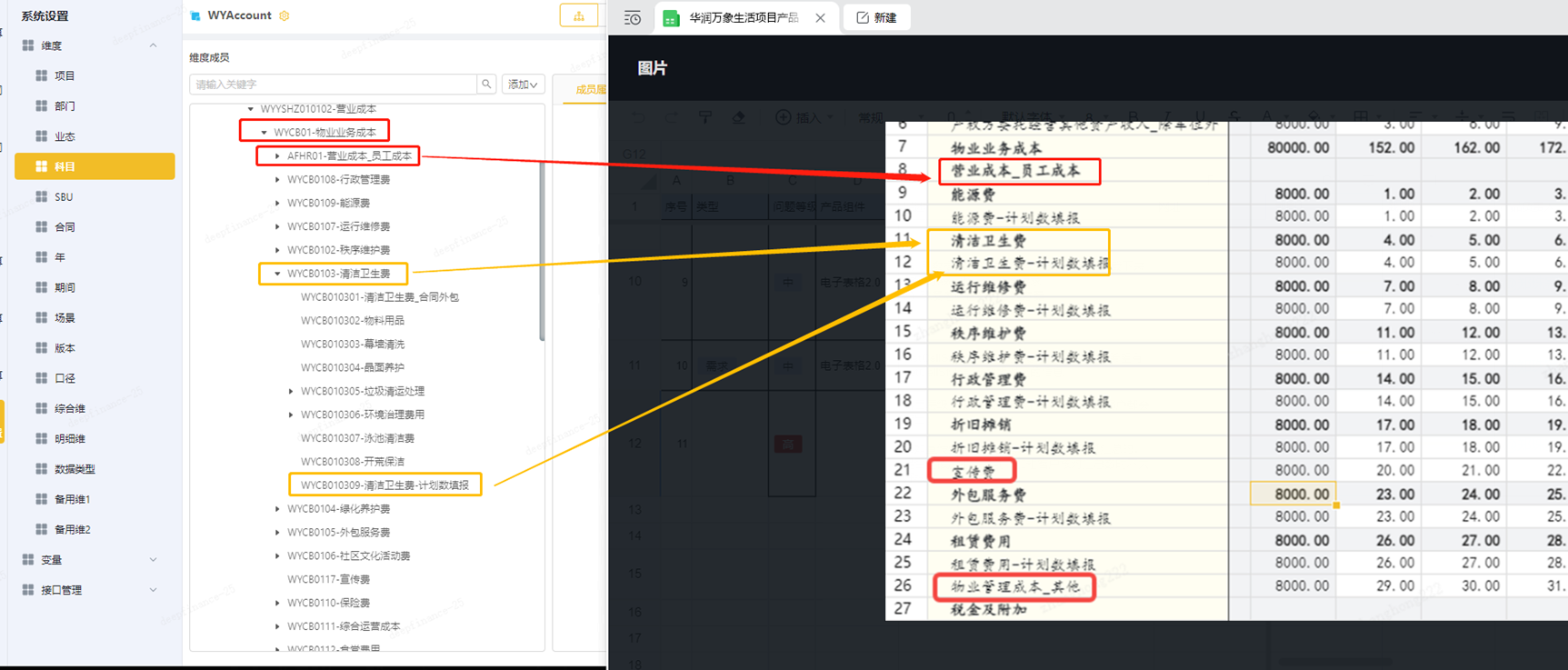
正常情况下,动态表会对Ibase、Ichildren、Idescend维度表达式有+-和缩进效果,如果编制报表时,科目是一个个挑出来的,比如 COA;1001;1003;1101;110101,动态表只会平铺展示这些科目。
但由于这些科目都在同一个大的成员COA下,层级有一定的关系可寻,要实现按层级缩进,可采用以下方法曲线救国。
首先,给维度添加一个UD1,并且ud的值设置成和维度编码一样
接着,将动态表中的表达式 1001;1003;1101;110101 替换为 OrFilter(IDescendant(COA,0),Attr(ud3,’1001’,’1003’,’1101’,’110101’))
这样,就将原先通过科目编码挑个别科目的过程,转换成了通过UD过滤某个大科目下的小科目。并且,两个表达式有相似之处,可以快速转换。
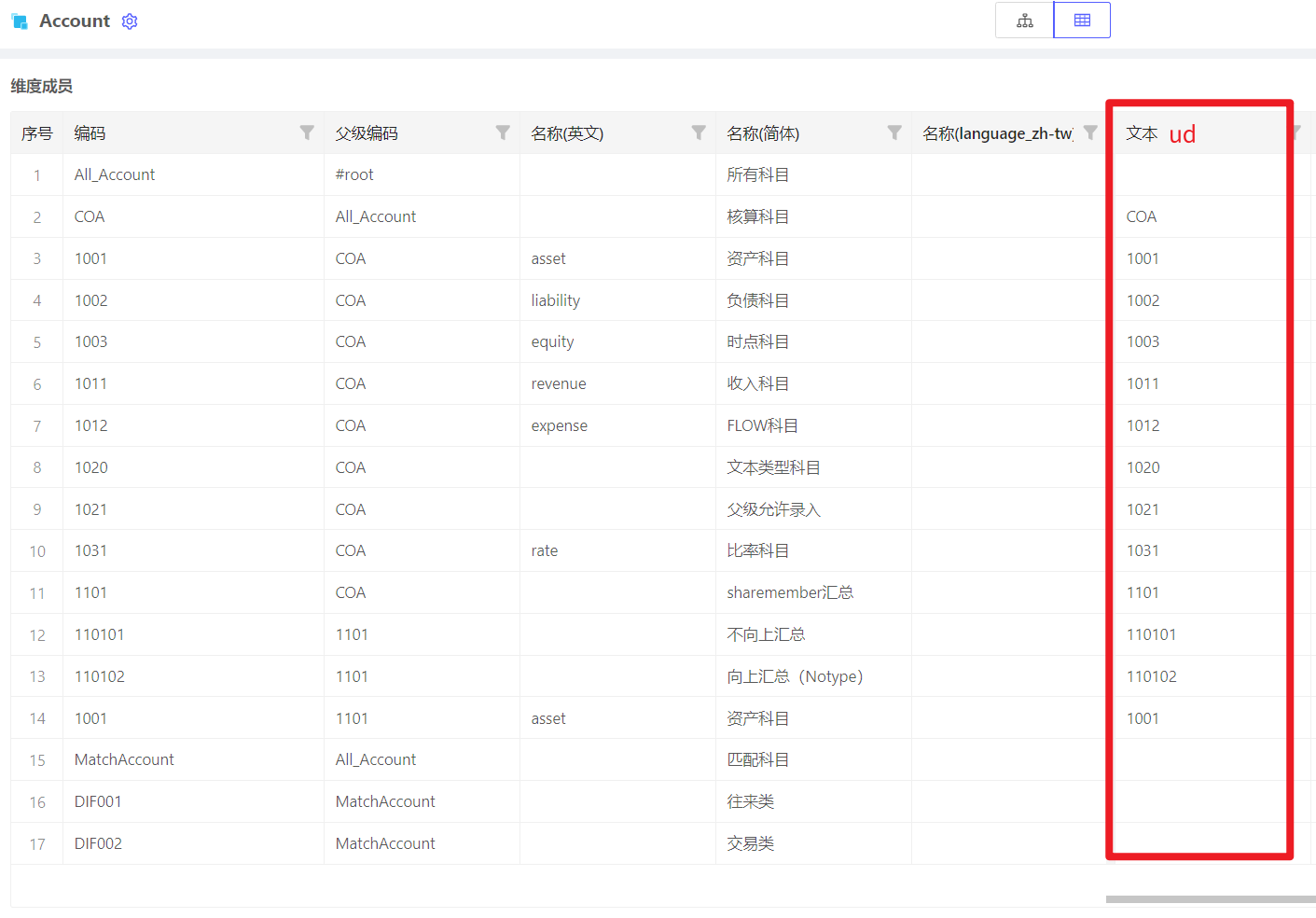
多版本实体维,开启了过滤未激活实体,但是没有效果
注意:目前维度表达式函数第三个参数有0,1,2三个枚举值
关于维度表达式中第三个参数的说明如下:
|
维度类型 |
是否需要过滤(传入版本控制维度) |
第三个参数值 |
过滤效果 |
返回的成员结构 | |
|---|---|---|---|---|---|
|
多版本实体维 |
|
0 |
—> |
否 |
纯子 |
|
1 |
否 |
父子 | |||
|
2 |
否 |
纯子 | |||
|
|
0 |
否(即使开启过滤,也没有过滤效果) |
纯子 | ||
|
1 |
是 |
父子 | |||
|
2 |
是 |
纯子 | |||
|
其他维度类型 |
不支持 |
0 |
否 |
纯子 | |
|
1 |
否 |
父子 | |||
|
2 |
否 |
纯子 |
电子表格中,与多版本实体相关的功能总结
|
功能点 |
作用 |
场景举例 | |
|---|---|---|---|
|
1 |
筛选器上开启“过滤实体有效性” |
筛选器配置[多版本实体]维度表达式后,开启[过滤],则筛选器可选列表中,仅出现激活的实体。 |
使用多版本实体功能的大部分报表,公司仅用于筛选,不体现在行列中的。 |
|
2 |
动态表行/列上开启“过滤实体有效性” |
从财务模型查询动态表数据时,行列上的实体按照维度表达式返回激活的实体。 |
比如合并工作底稿,需要在列上展示所有激活的下级公司,可开启此功能。 |
|
3 |
浮动行表筛选字段-自定义模式开启“过滤实体有效性” |
根据筛选器+自定义维度表达式+过滤激活实体,对浮动行表的数据行进行筛选 |
比如查询合并层面的浮动行表,可直接传入合并节点,并以该合并节点下激活的Base实体为筛选条件。 |
|
4 |
浮动行表展示列-逻辑属性开启“过滤实体有效性” |
浮动行表某个展示列,可供选择的下拉成员列表是多版本实体过滤激活 |
比如填报浮动行表中的关联方列时,可关联实体维度并开启激活。 |
Override
列1实际场景,列2预算场景,期间维是IDESCENDANTS(TotalPeriod,0)或者用户多选的,想要看所有期间的预实差异,但是不想写12个月的公式。
可以先建一个预实对比的dummy成员,然后构建动态表结构,再在dummy成员上使用override fx功能,计算出结果

注意:该方案下,动态表不要启用隐藏无数据,因为override是动态表所有配置中最后执行的,如果隐藏了无数据,dummy成员也会被隐藏,就无法计算了。
隐藏无数据的曲线救国之路:第三列直接使用actual作为动态表被覆盖前的数据,然后将actual覆盖成fx公式,这样,就按照actual是否有数据来进行隐藏。
怎么设置一个Idescendent表达式的其中一个成员只读

不需要人为拆分成三列,使用override特定科目只读即可
override_data([account{费率}],[readonly=1,theme={editablecolor:”#f2f3f5”}])
问题2:如果拆分三列后,还能合并单元格吗?
电子表格2.0可以跨动态表列合并(不care动态表分多少列,都可以合并)
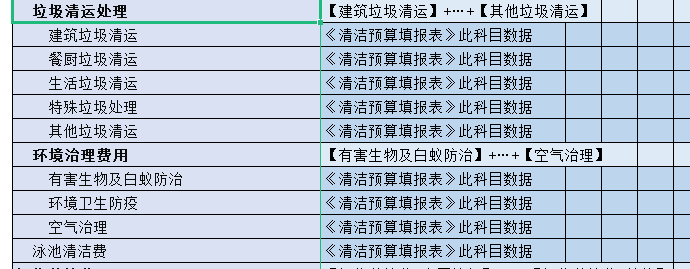
科目在维度成员里面是平级的,想通过override展现出层次感?
用一个全角空格“ ”来实现标题人为缩进
📢如果需要设置的单元格比较多的话,可以直接使用自定义JS API:setCellIndent
如何让某一科目的数据展示为相反数
使用override计算
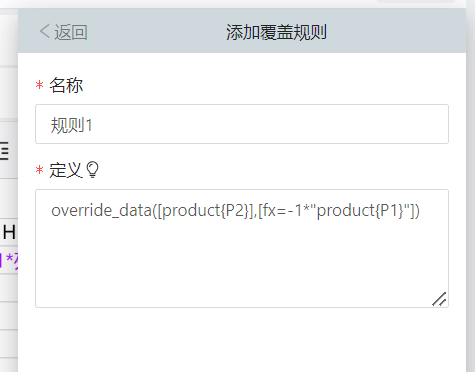
行上设置了只读,override成员之后,还是可写
override是最末的处理,也就是说override member成员之后,会以新成员的模型权限重新渲染只读。
解决:
override之后,再叠加只读就好了
override_data([r2:r2],[member=”period{NoPeriod}”,readonly=1,theme={editablecolor:”#e8e8e8”}])
注意,这里editablecolor是指override之前,可编辑的单元格的背景色,editablecell’s color的意思, readonlycolor是指override之前,只读的单元格的背景色,readonlycell’s color的意思,
如果不管单元格权限本身只读和可写,都想改颜色,可以都加上theme={editablecolor:”#e8e8e8”,readonlycolor:”#e8e8e8”}
override theme参数对照表
—通用
•font: 字体,0-Times NewRoman,1-Arial,2-Tahoma,3-Verdana,4-微软雅黑,5-宋体,6-黑体,7-楷体,8-仿宋,9-华文隶书,13-Pingfang
•fontsize: 字号,9-72
•fontweight: 字体粗细,0-默认(汇总加粗,非汇总不加粗),1-加粗,2-不加粗
•fontcolor: 字体颜色,任意16进制颜色值
•bordercolor: 边框颜色,任意16进制颜色值
•borderline : 边框线型,0-实线,1-虚线,2-粗实线
•bordertype: 边框位置,0-上下,1-左右,2-所有,3-上下+粗底,4-上方,5-下方,6-左侧,7-右侧
—仅数据区域
•readonlycolor: 只读单元格的填充色,16进制颜色(注意是财务模型提供的权限属性,不受override+readonly影响)
•editablecolor: 可填单元格的填充色,16进制颜色(注意是财务模型提供的权限属性,不受override+readonly影响)
—仅标题区域
•parentfillcolor: 汇总节点填充色
•basefillcolor: 非汇总节点填充色
动态表左上角表头可以调整吗?通用维想要在不同的表展示不同的名称
可通过Override_header([r0:r0],[header=”字段1;字段2;字段3”])
r0:r0 专门代表左上角表头
条件格式和数据验证
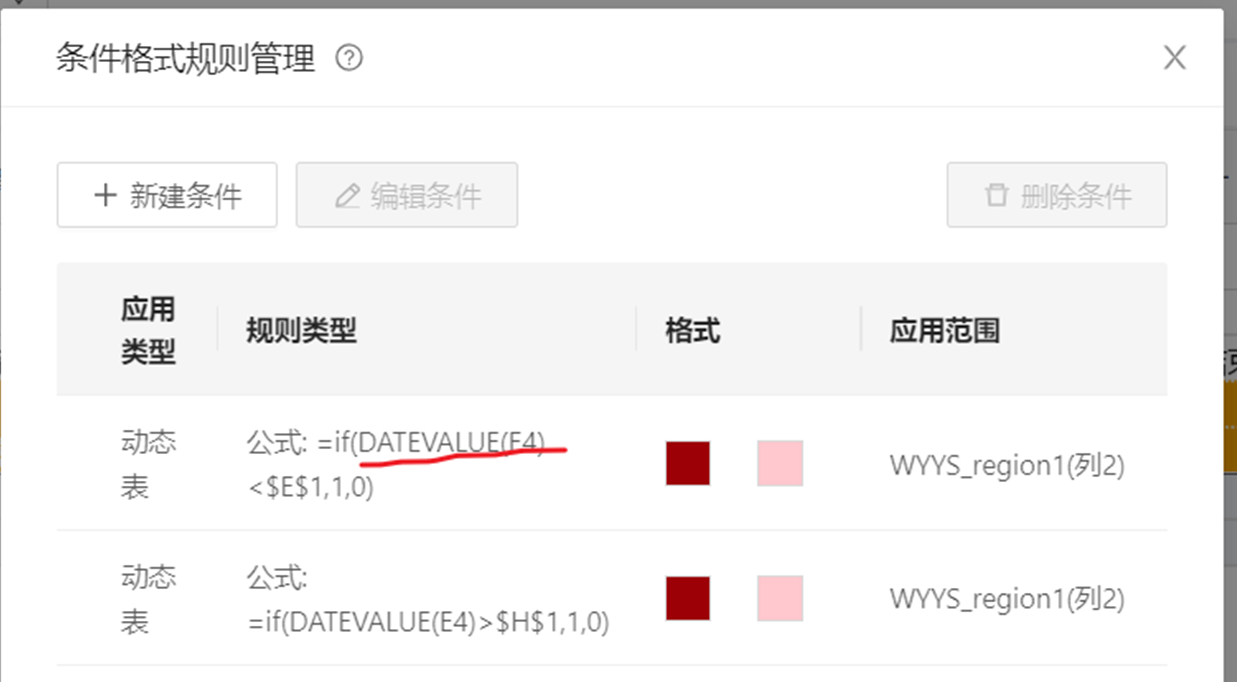
条件格式可以写公式么?比如,动态表列1=列2,标红
可以的,但是注意,公式只能用excel公式,需将动态表起点位置转换为具体的单元格。具体见图示例子
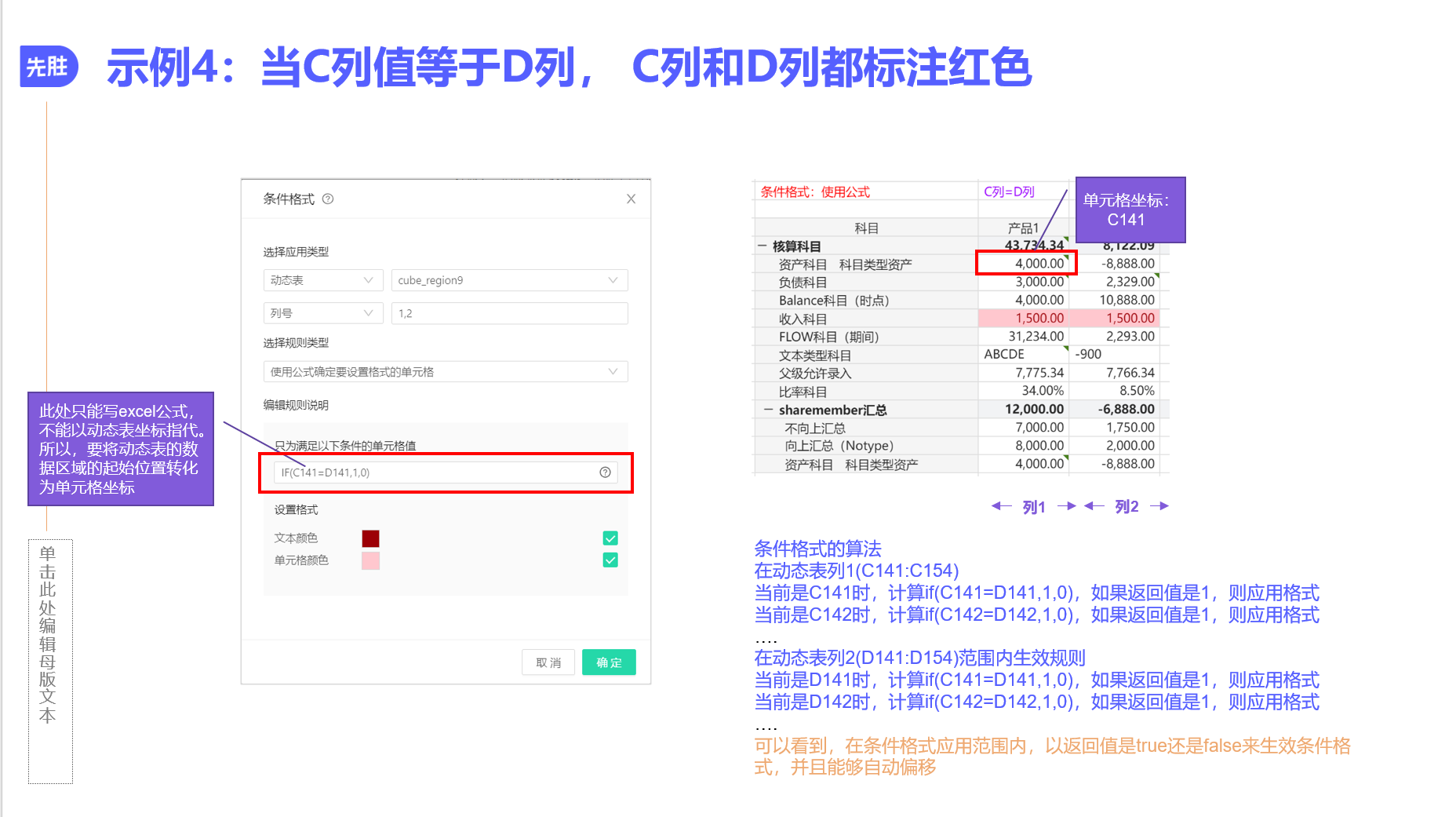
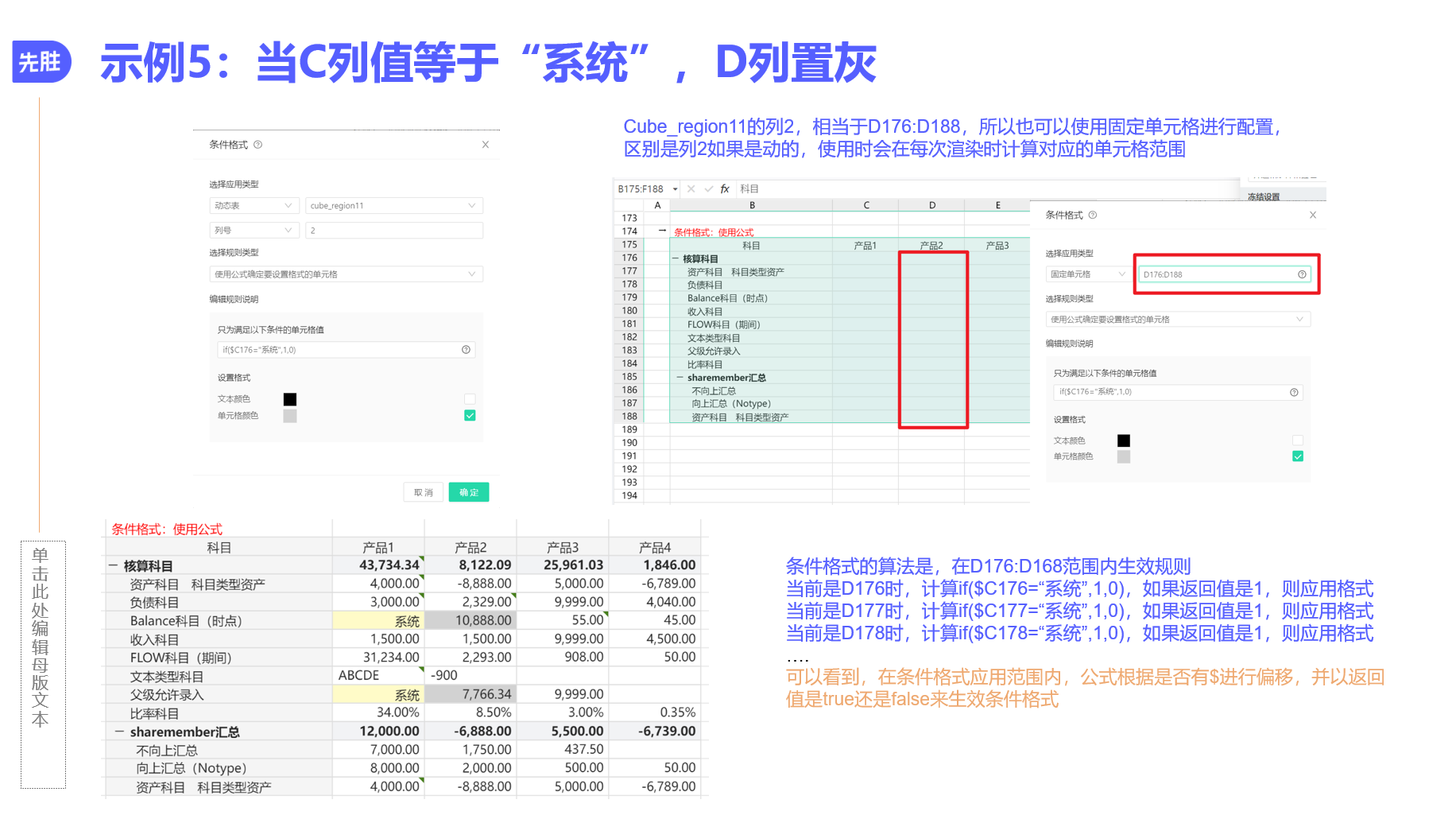
有多个判断依据的话,还可以用AND OR逻辑运算

根据有无$,判断公式会随着应用范围进行偏移
具体逻辑同excel
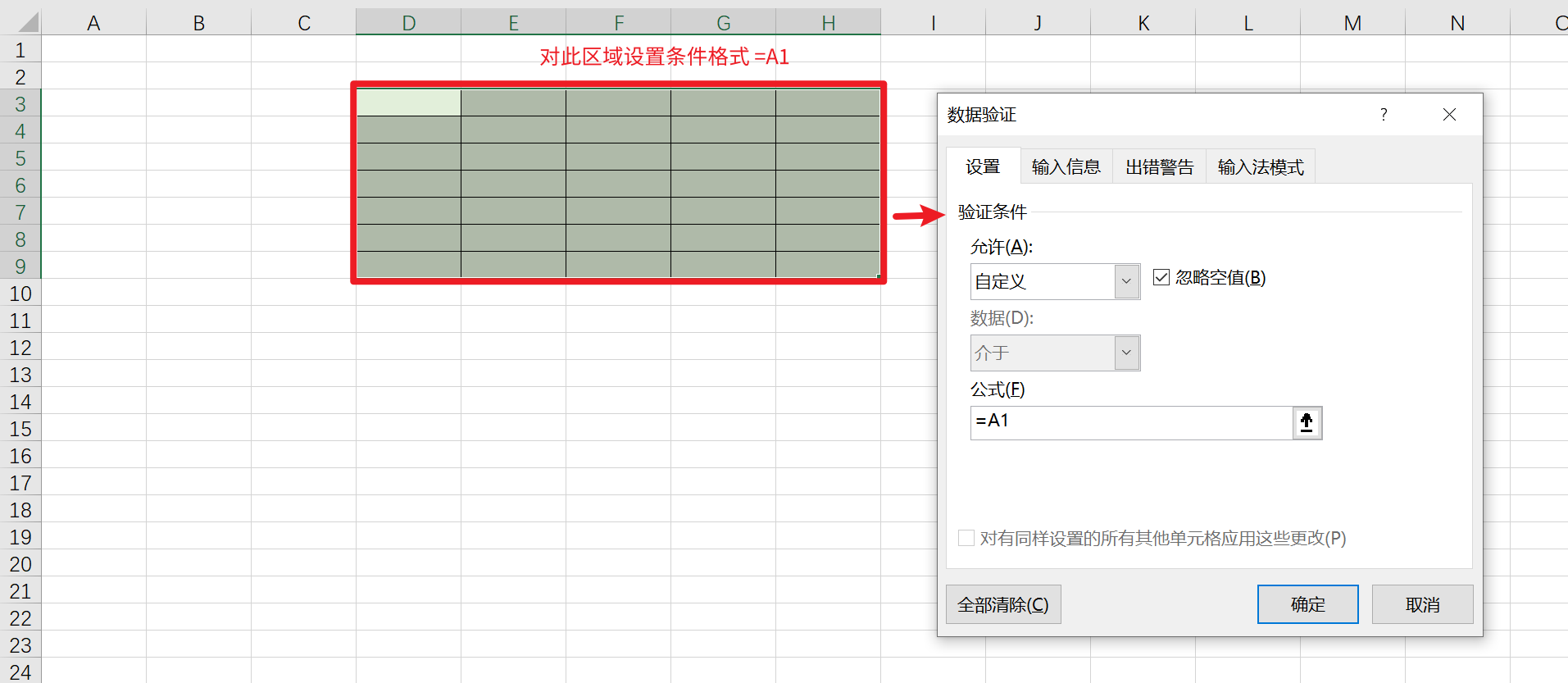
查看E3的数据验证公式=B1

查看E5的数据验证公式=B2
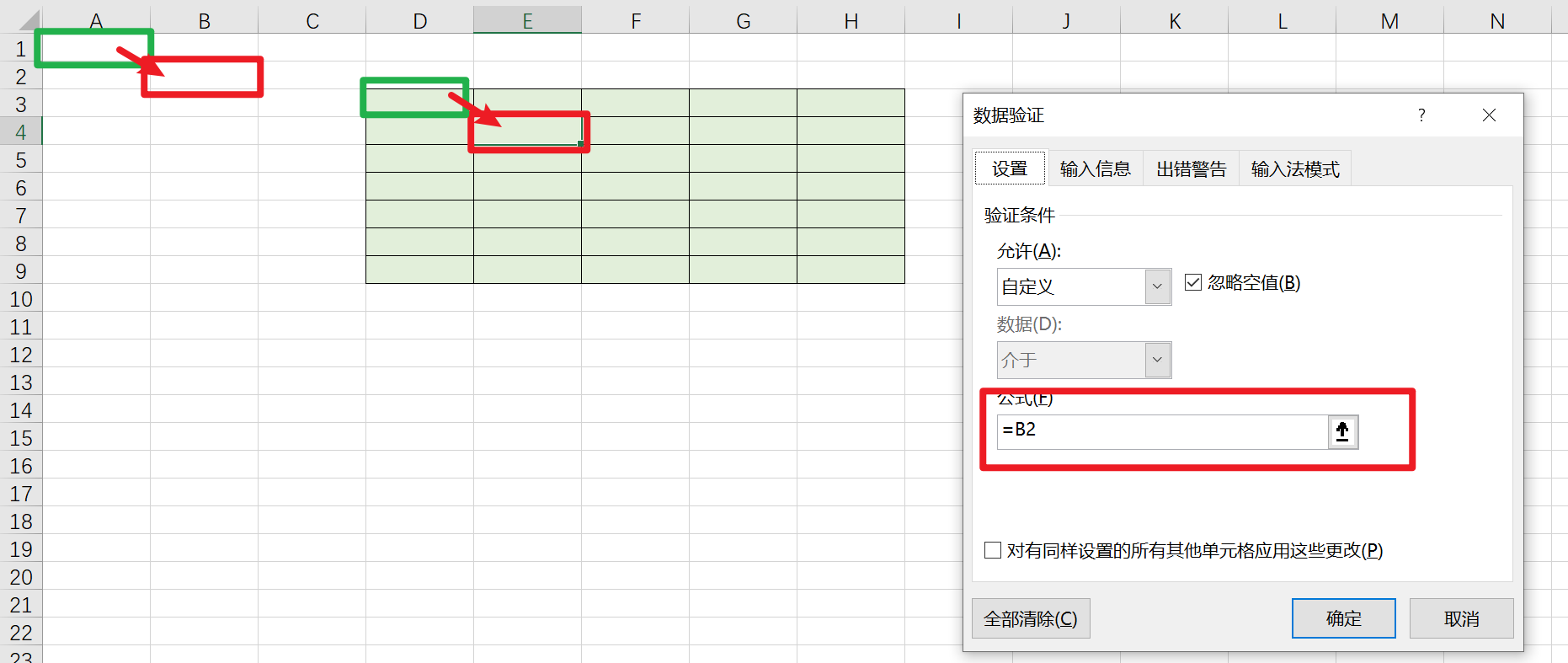
结论:不管是条件格式还是数据验证中使用公式的,如果公式中的单元格没有加时,下拉公式)

通过条件格式或数据验证,实现限制录入日期的格式和范围
📢注意,动态表已支持科目类型为“维度数据”和“日期数据”,浮动行表本身支持逻辑属性为“维度”或“日期”,使用标准功能已经能够限制日期格式,若还需对日期的范围进行控制,才考虑本案例实现方案。
📢注意,日期数据是文本格式还是日期格式,对可使用的方案细节有很大影响。在动态表(科目数据类型选择文本)和浮动行表(逻辑属性配日期)中,都是文本格式(Excel中的日期格式是距离1900年1月1日的天数)。
因此,应当将数据本身的格式与校验的目标匹配起来:
当数据是文本(动态表和浮动行表都是这种情况)
数据验证:使用公式判断,将文本通过datevalue函数转换后再比较日期范围

条件格式:与数据验证写法类似,唯一的区别,一个是返回false呈现效果(数据验证),一个是返回true呈现效果(条件格式)。
效果的区别:错误提示方式不同,一个是用角标和悬浮文本并且可在错误的情况下禁止录入(数据验证),一个是用背景色和字体颜色(条件格式)。
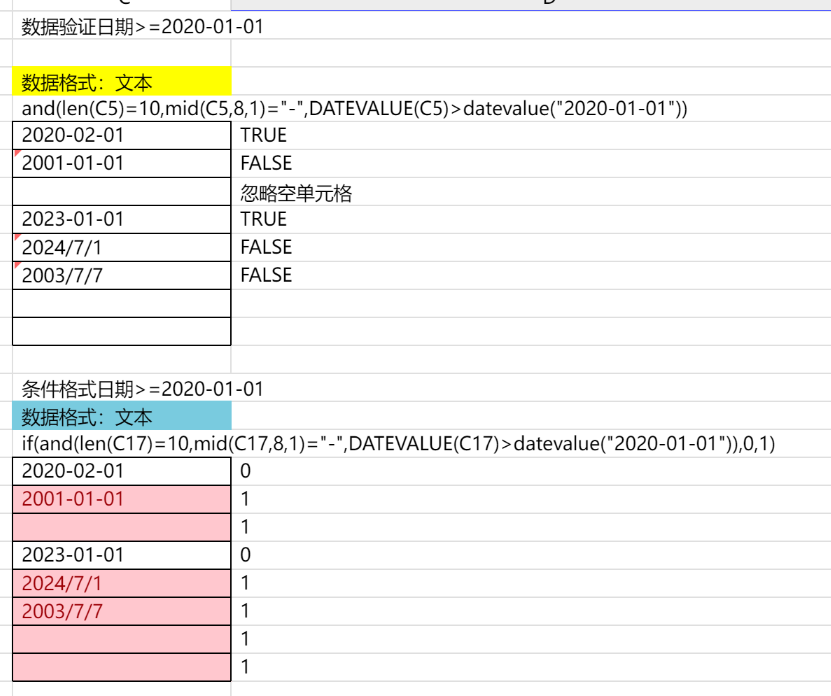
例子中的公式,通过长度、符号、日期值综合来认定填报的正确性,如需其他条件,可自行叠加公式。
如果需要限制的日期范围与筛选器值相关:比如页面维1月1日~页面维12月31日 之间
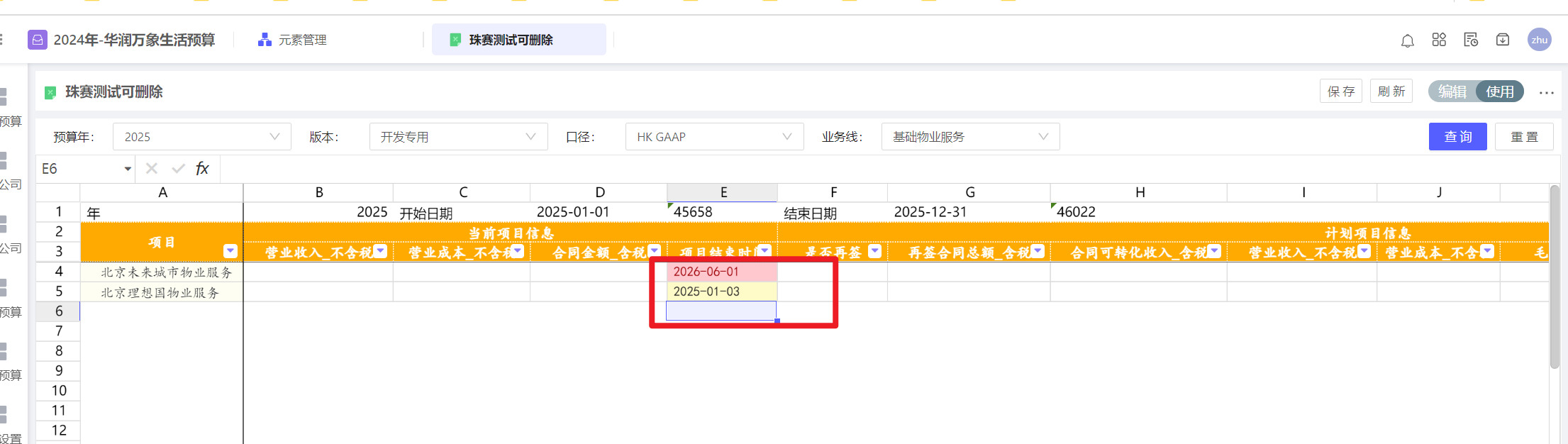
可通过DFfilter将筛选器值,引到单元格上,然后,通过拼字符串的方式,得到2025-01-01和2025-12-31两个文本。接着,再依据上例使用条件格式或数据验证。
能否根据左侧的实时选择,不同的选项出来不同的下拉列表
warning 如果下拉选项比较复杂(比如需要通过mapping表才能找到),可以使用自定义JS来实现。本例是不借助自定义JS的简单实现
比如下图, 若【专业条线】选择秩序,则【岗位】下拉选择则可选择秩序领班、保安主管、保安队长、保安;若【专业条线】选择绿化,则【岗位】下拉选择则可选择绿化领班、绿化主管、绿化工
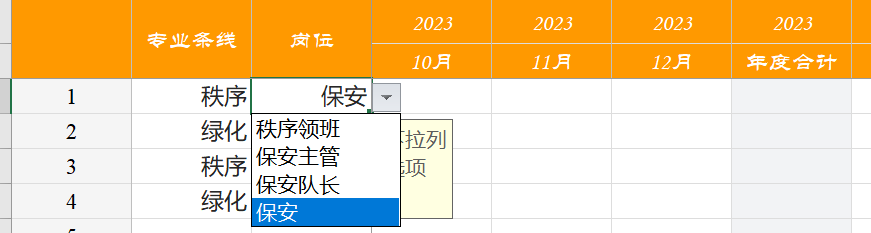
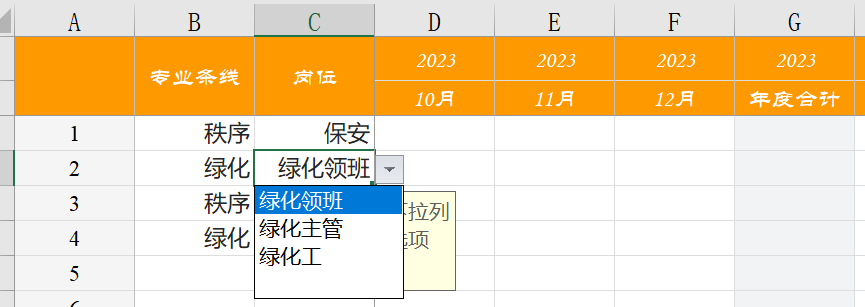
第一步,通过excel公式,计算出每行的下拉列表的值

第二步,通过数据验证功能,实现下拉
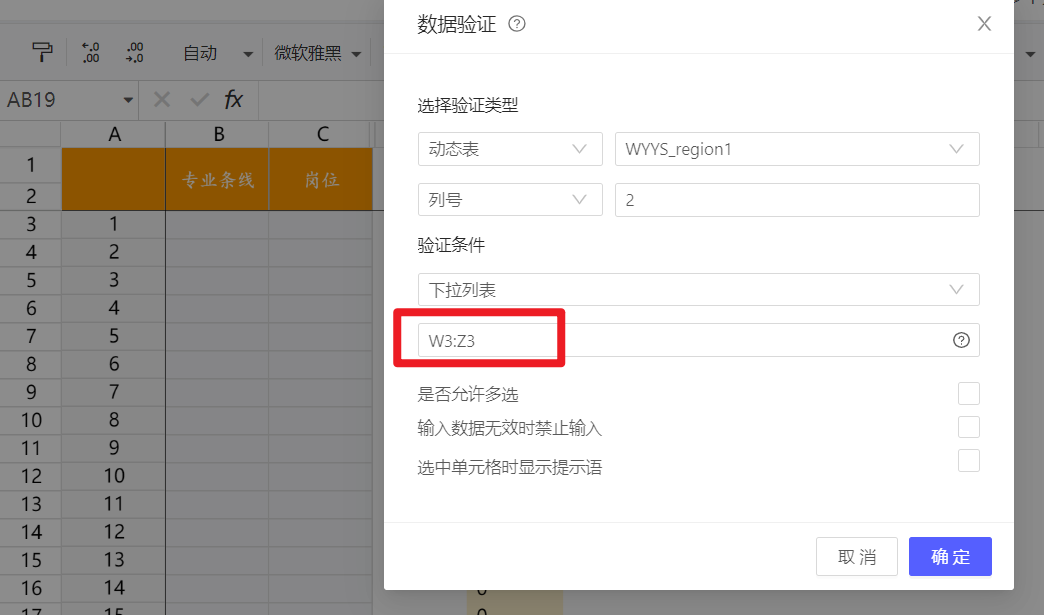
在动态表列2应用条件格式时,由于W3:Z3没有加$锁定,下拉列表的引用区域会跟随列2的单元格进行偏移计算。比如:
-
列2的第一个单元格C3,引用区域为:W3:Z3
-
列2的第二个单元格C4,引用区域为:W4:Z4
-
…
至此,综合实现,当填报不同的内容时,出现不同的下拉列表。
数据验证下拉列表添加了一个超长列表(字符长度大于255),下载到excel后,没有下拉列表了
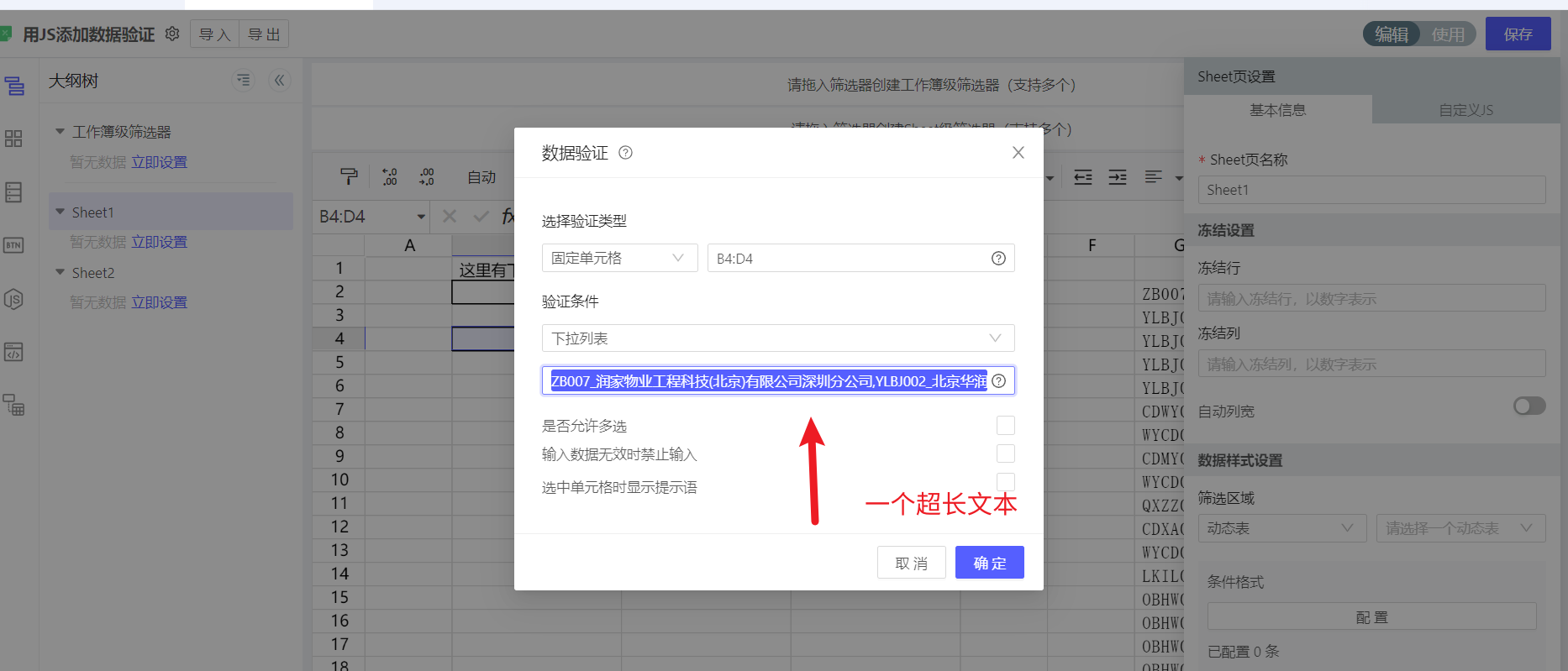
Excel的数据验证功能,不支持超过255个字符,但是luckysheet是支持的,因此,尽管网页上能够正常使用,但是下载到excel文件后,会被excel当成错误数据,自动删除,导致excel没有下拉功能。
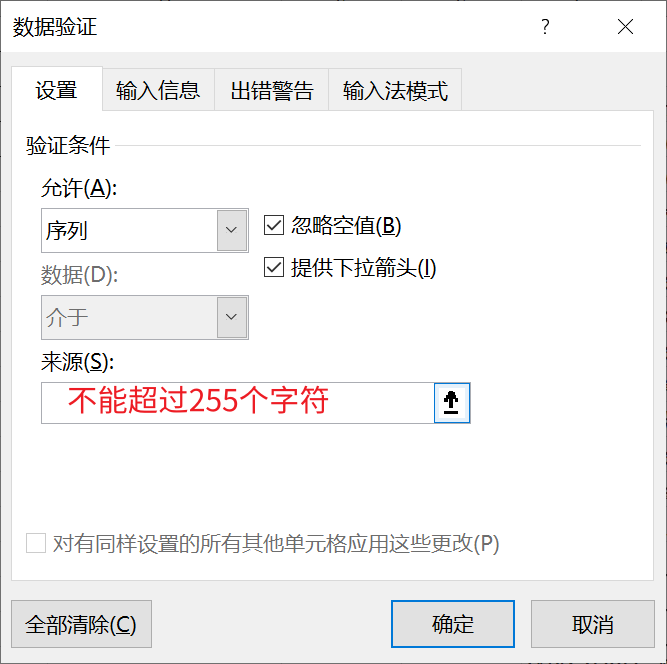
替代方案,将下拉选项放在Sheet上,配置数据验证的下拉列表时,引用单元格作为下拉值来源。
在动态表列固定行不固定,添加条件格式/数据验证时,其中某行不需要校验,但是由于动态表行是动的,也不好使用固定范围
样例如下:
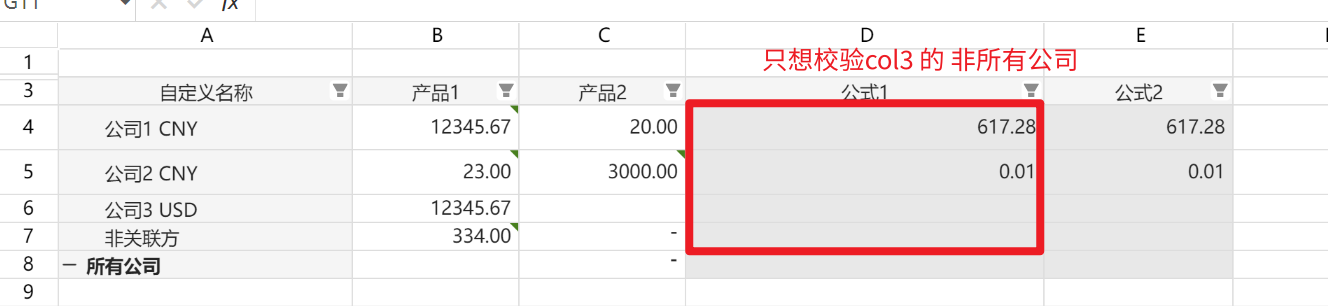
配置条件格式或数据验证时,可选择应用范围为动态表的列3(注意是动态表坐标),然后使用公式计算条件格式/数据验证结果

条件格式案例分享:不同的月份有不同的指标值,根据指标值对进度列未达标进行样式突出显示
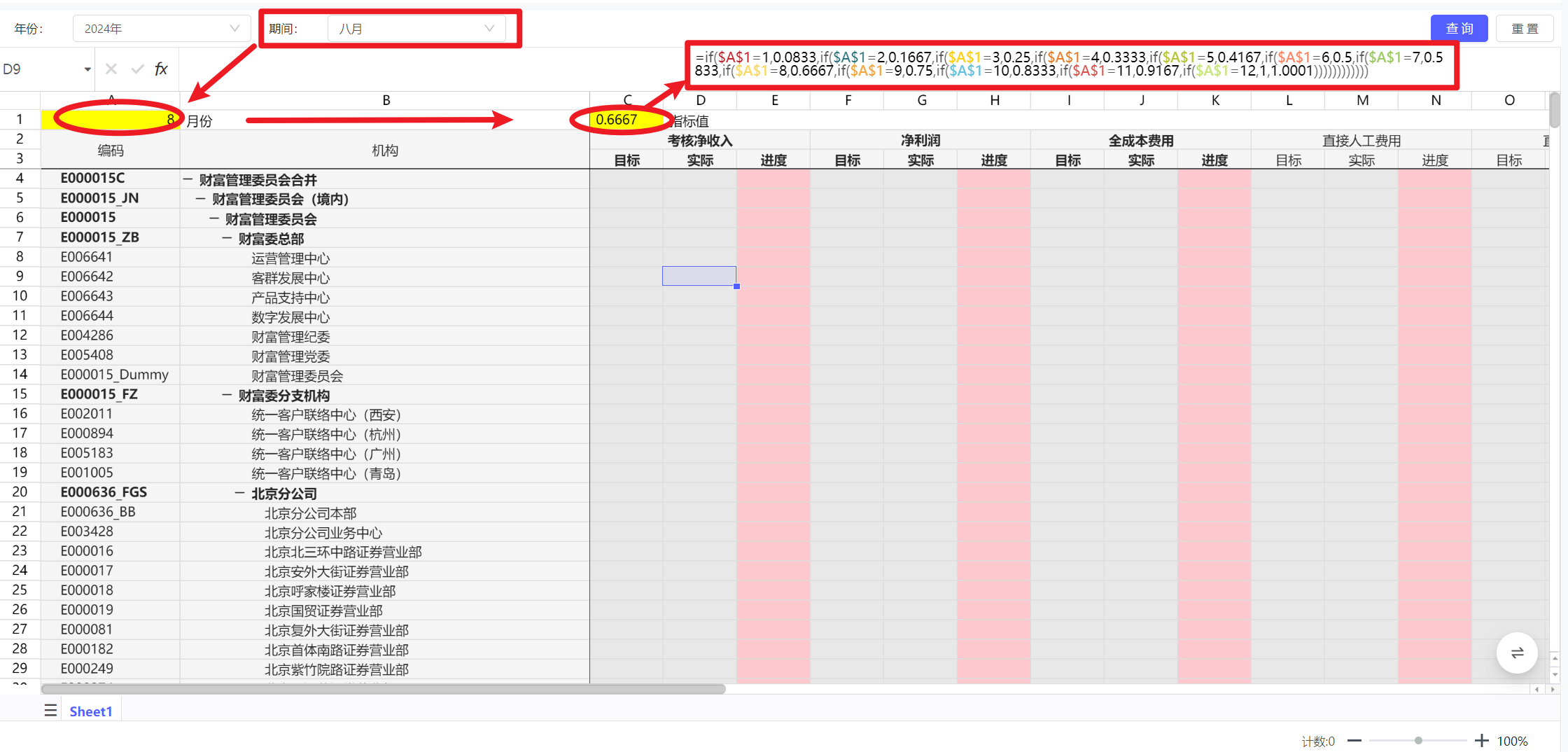
1、将月份通过dffilter函数引到表单上
2、通过excel公式计算本月指标值
3、条件条件格式:使用公式计算
DF函数
DF公式用法示例
请下载后查看公式
注意:
1、DFdata/fx函数需包含cube中的所有维度
2、引用单元格(维度成员引自单元格)需要二次查询,因此会降低查询效率,若静态表较大对性能有较高要求,请避免使用引用单元格。
3、可在Excel上编辑好公式和样式了,导入到编辑态
若一张静态表中同时包含DFDATA和DFDATAFX等多种类型公式,为方便编辑,可套用以下模版编制静态表
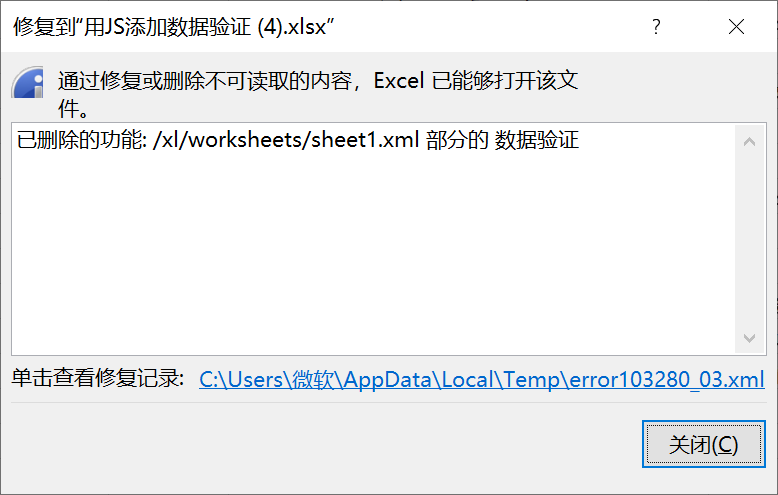
维度/字段比较多,DF函数下载到excel失效了
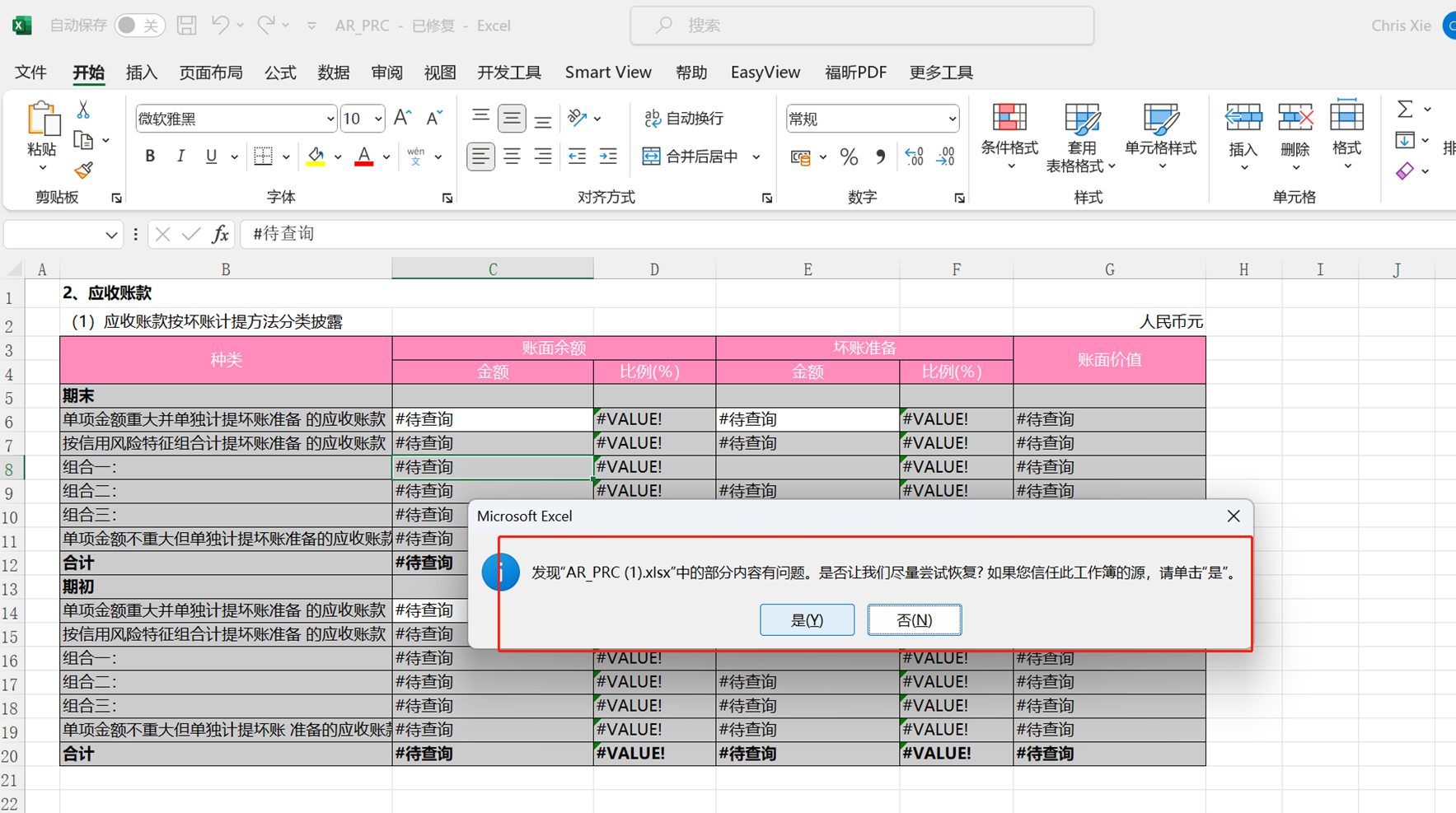
由于DF函数的第二个维度及成员参数是一个长字符串,当公式里的字符串长度大于255个字符时,excel就不支持了,所以编辑态导出的时候,excel会自动修复删除掉这些不识别的公式。
解决方法,将字符串拆分用&进行连接。举例:
“ABC”&”123” 就是excel的字符串加法,最后得出的结果是”ABC123”
可结合DF公式的引用单元格功能,将行或列上的成员直接拼接单元格

这样就能解决公式超长后,excel不识别的问题
DFdata单元格右键数据审计,没有历史记录,但是动态表相同维度下有
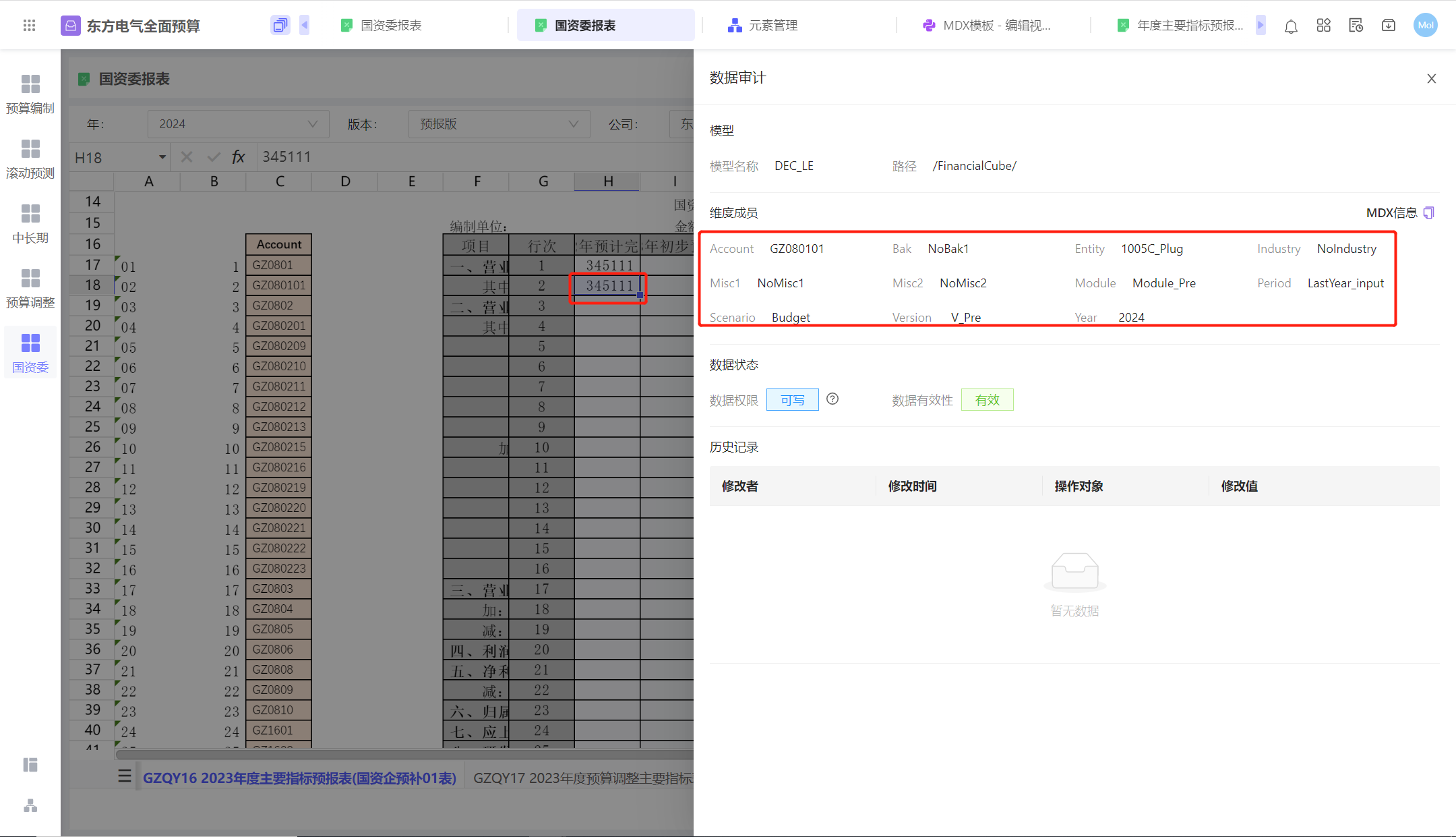
是因为动态表取数接口兼容大小写,数据审计不兼容大小写,
DFDATA由于引用了现有单元格里的成员,没有区分大小写,导致数据审计查询不到历史记录
所以,注意,引用单元格上的维度成员要区分大小写
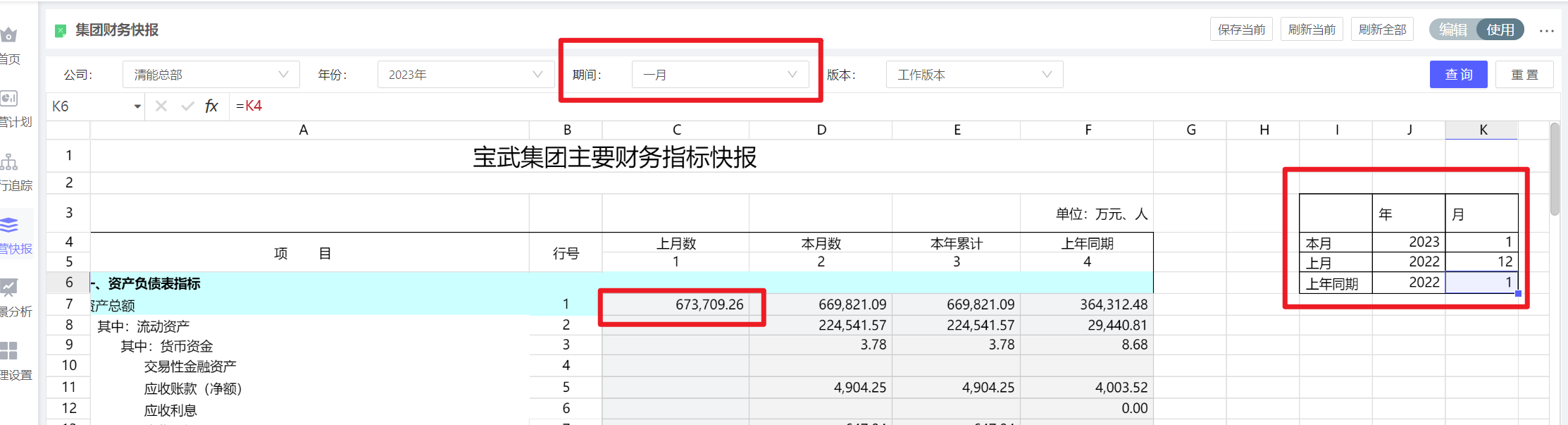
报表中要展现上期数,通过@筛选器-1功能,当期间为1月的时候,则会报错,无法取到上年12月
将筛选器值通过DFfilter取到单元格上,再通过年和月计算出上期对应的年月

再使用DFDATA函数,拼接单元格上的成员,实现取数
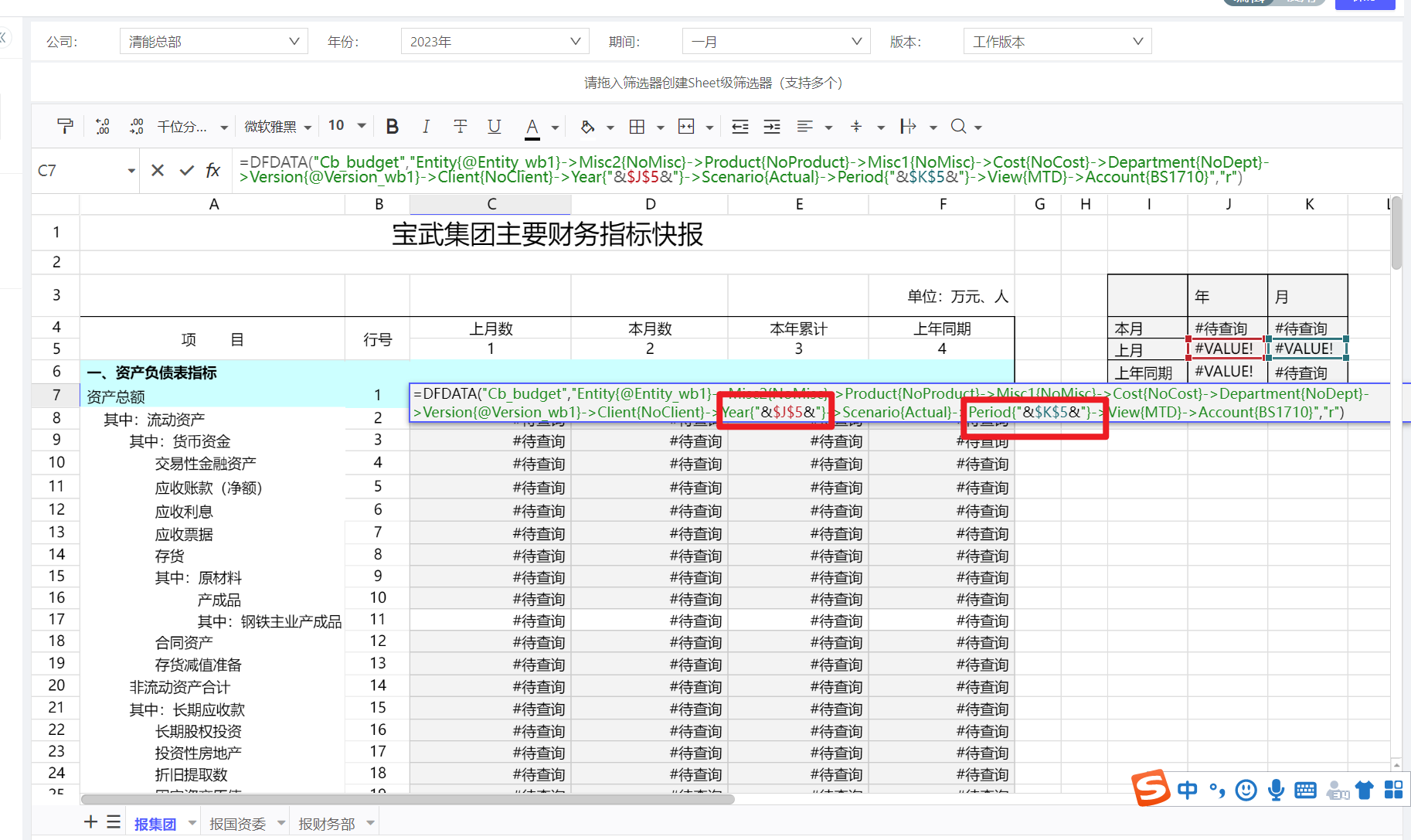
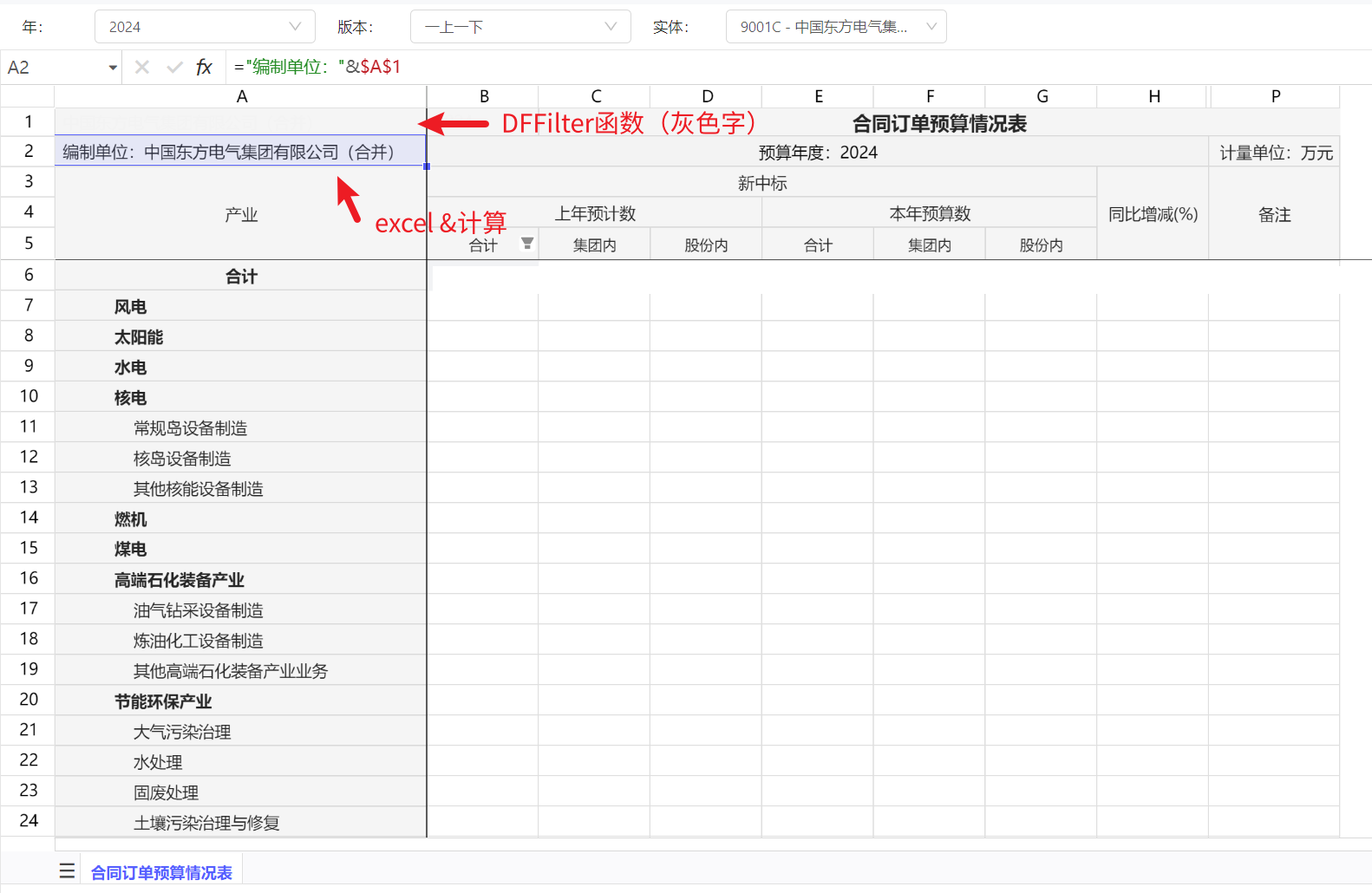
下载的Excel时能把筛选条件也导出吗?
标准功能下载时不会导出筛选条件(因为筛选器是个表外内容),但是我们编制报表时,可以主动将筛选器值通过DFFliter函数放到Sheet中,这样,导出时报表上就能自然而然带出筛选器信息。
下图是一张带报表名称、公司、年月、单位等信息的报表设计参考。
线上即席分析
为什么动态表右键没有即席分析
线上即席分析功能默认关闭,如需开启,在deep-table-server 后端服务增加启动环境变量:EXPORT_DEEP_TABLE_ADHOC_SWITCH, 0-关闭,1-开启
线上即席分析功能点如下:
从任意动态表/DF公式右键进入即席分析
即席分析目的一般为从多角度透视当前在报表上看到的某个数据。因此,开启线上即席功能之后,任意动态表(未来会拓展到静态表)的数字上右键,均可跳转即席分析。
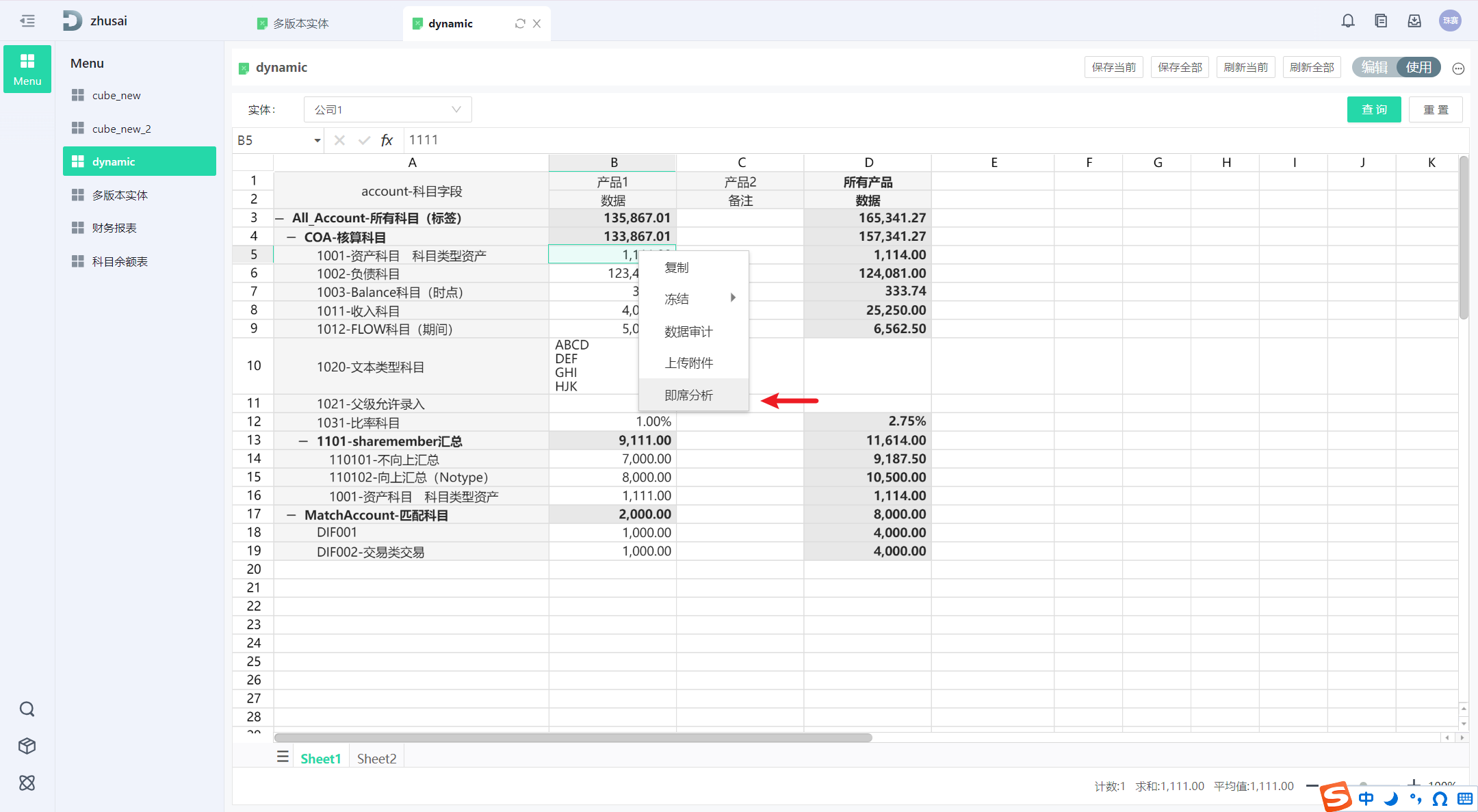
通过动态表传递的财务模型及当前单元格对应的维度组合,打开一个新的即席分析窗口。默认以科目维度的当前成员为[行],财务模型除科目外的第一个维度的当前成员为[列],剩余维度放在[筛选区]

即席分析窗口分为4个部分:
-
即席分析工具栏:包括维度成员操作按钮、维度成员选择器、信息查询、刷新按钮
-
筛选器或背景维度区域
-
单元格样式工具区:可对单元格的字体大小、加粗、居中方式等进行调整,方便查看
-
即席分析页面:数据展示区,行维度+列维度组成的一个矩阵结构。
自动识别行列结构
若默认的分析结构不符合分析需求,可直接修改行列成员,并点击[刷新]按钮,自动识别新的分析结构
比如:
-
插入行列,并增加行/列维度(背景维度会自动释放到行列)
-
删除行列,以减少行/列维度(减少的维度会自动释放到背景维度)
-
直接修改维度成员(直接编码、描述、编码-描述),以识别为另一个维度
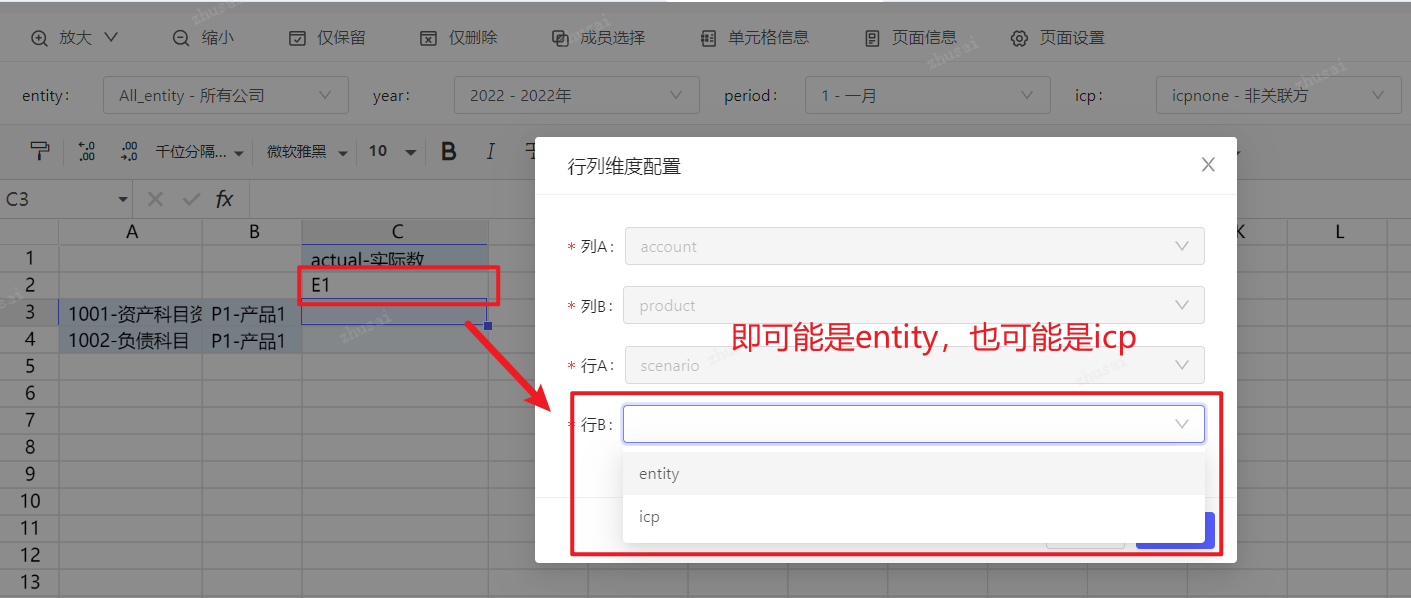
注意:若财务模型不同的字段关联相同的维度,或不同的维度但是具有相同的维度成员,在分析时,因为无法自动判断是财务模型字段A还是字段B,会弹窗由用户进行行列结构的手动指定。
手动指定之后,若再次在相同的行/列增加更多成员,会沿用现有行列结构,不要求用户重复指定维度。
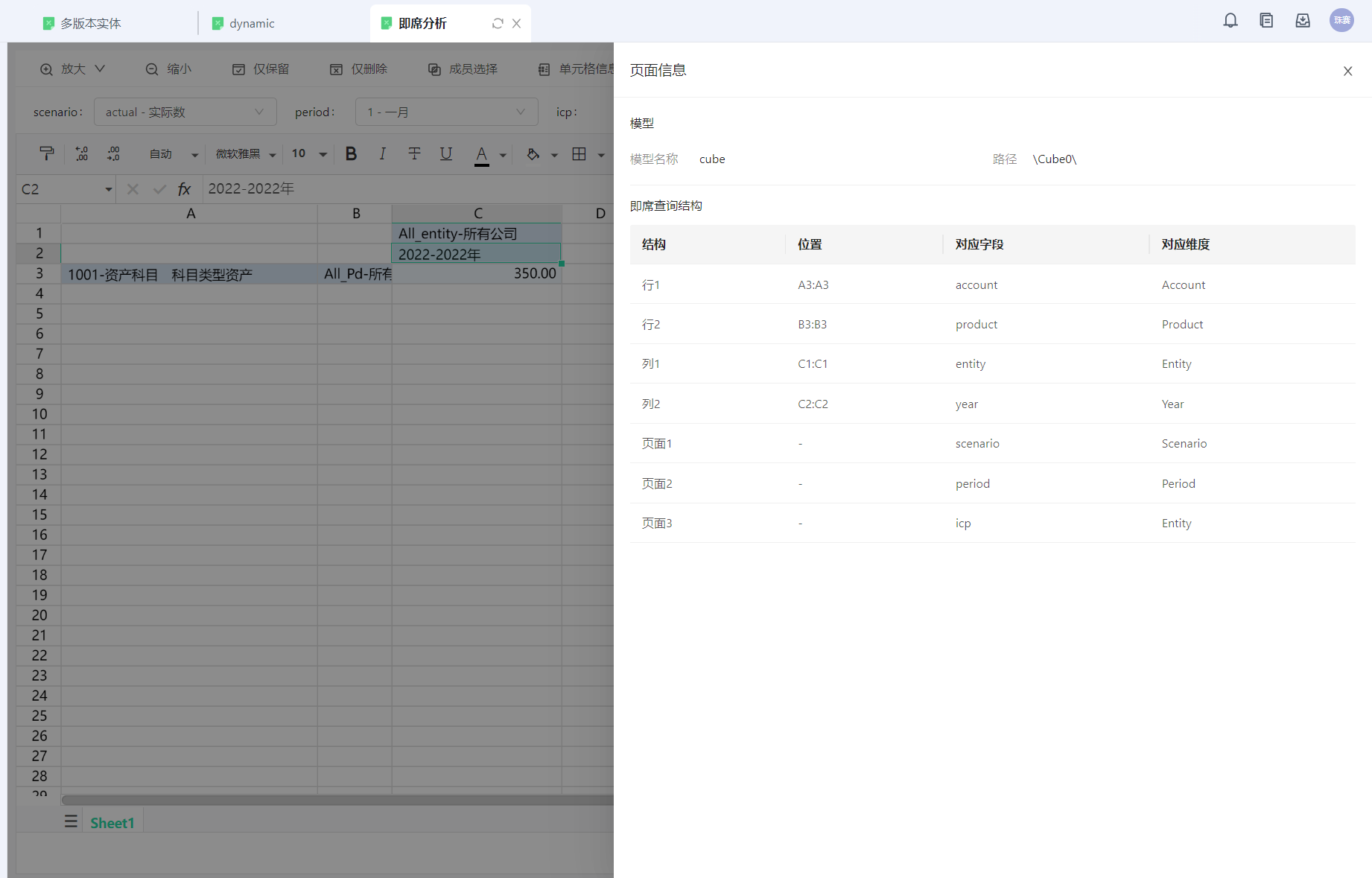
查看行列结构的具体信息
点击[页面信息]按钮进行查看
维度成员放大、缩小、保留、删除操作
在现有的分析结构下,可对当前成员进行放大、缩小、保留、删除:
-
放大:放大到下级(iChildren)、所有级别(iDecsendent)、最低级别(iBase)。执行插入新成员操作。所有相同的成员都会放大。末级节点无法再放大,点击无反应。
-
缩小:当前成员缩小为上一级成员。 执行删除当前成员父级的所有下级,并插入父级成员操作。 root下的子代无法再缩小,点击无反应。
-
仅保留:某维度仅保留当前成员,执行删除当前成员外的其他成员操作。
-
仅删除:某维度删除当前维度成员, 如果删除操作导致行/列无任何成员,则操作被阻止。
维度成员选择器
如果当前成员的放大缩小等操作,依旧无法满足分析目的,可自行挑选维度成员并插入。
操作注意事项:
-
维度:根据当前单元格所在的位置,自动匹配查询结构中的维度,左侧显示可供插入的成员。若在空白单元格点击,默认显示财务模型中的第一个维度。也可任意切换成其他维度后插入成员。
-
横向插入或纵向插入:根据当前的行列结构自动匹配插入方式,若在空白单元格点击,默认纵向插入。
查看单元格信息
即席分析中的数据区域单元格,可通过[单元格信息]按钮,查看维度组合、数据状态、单元格历史等信息
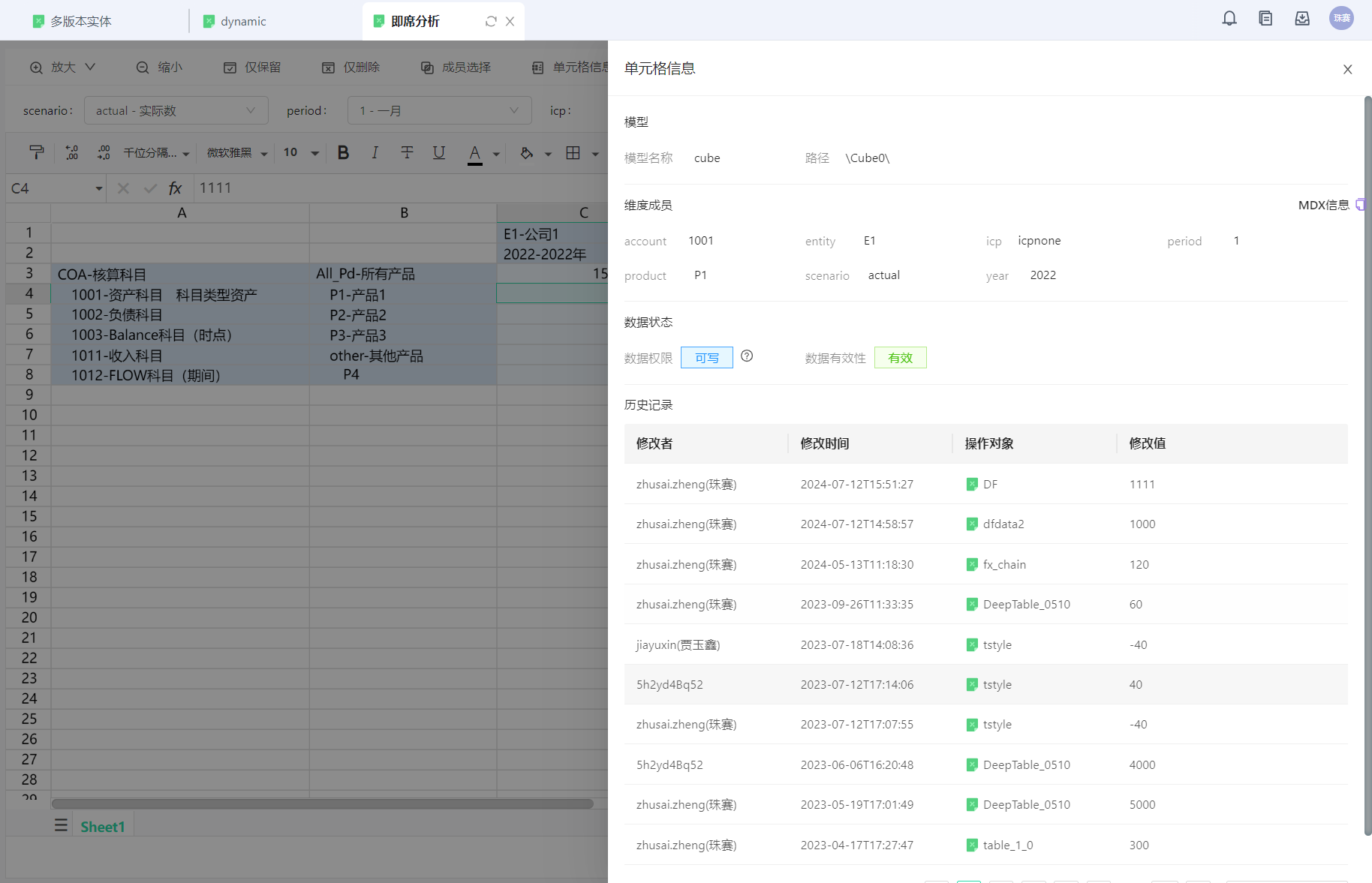
单元格操作
**工具栏:**修改单元格样式、添加筛选区域、查询替换等

注:单元格填充色和数字格式使用系统默认值,若手工修改,刷新后会重置
**右键:**插入/删除行列、冻结、清除单元格内容等
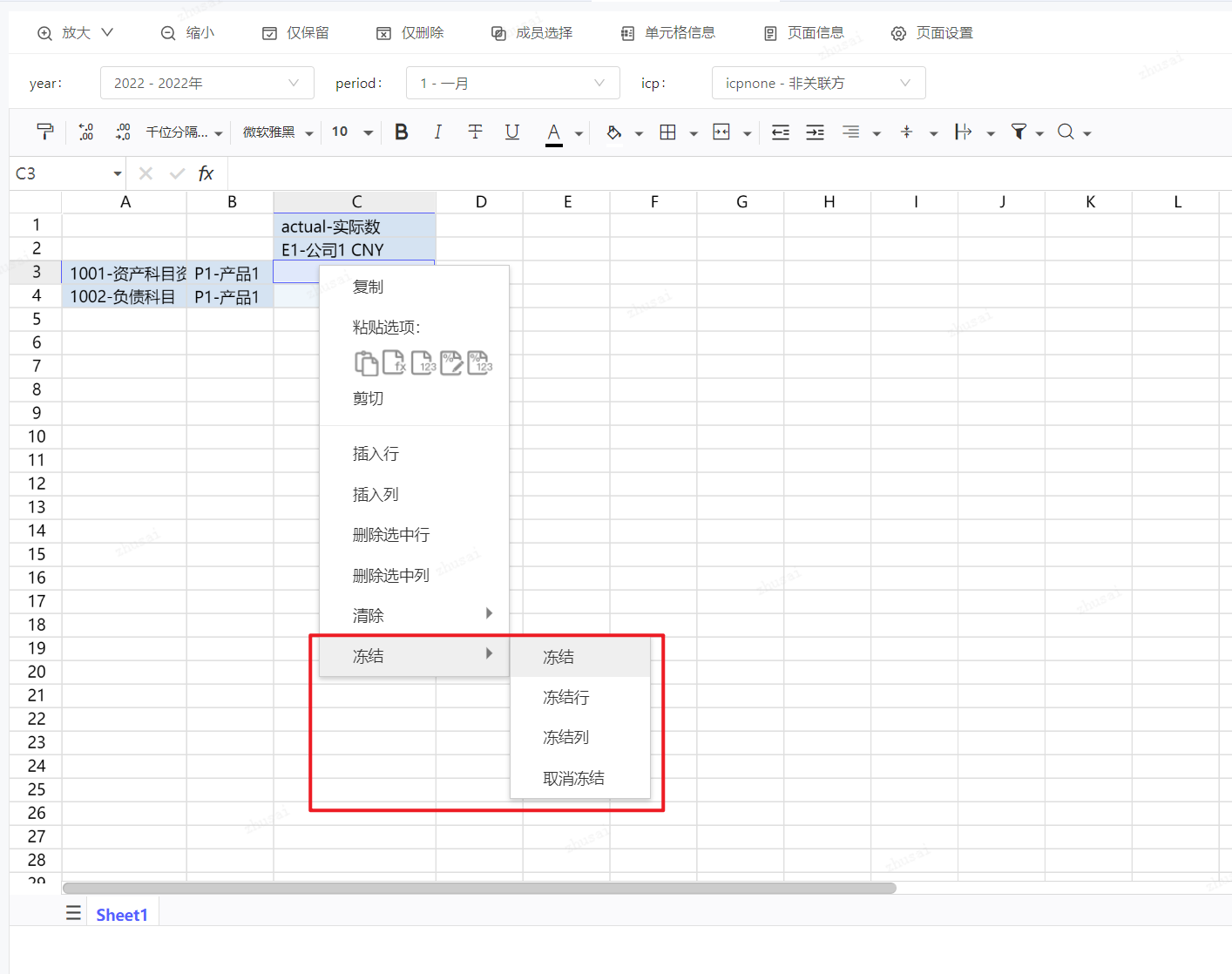
页面设置:维度显示方式
通过页面设置,选择维度成员的显示方式。
注意:维度成员显示方式和识别方式无关,即使显示成描述,但是填入维度成员编码可识别,只是刷新后,识别的维度会重新按照显示方式呈现。
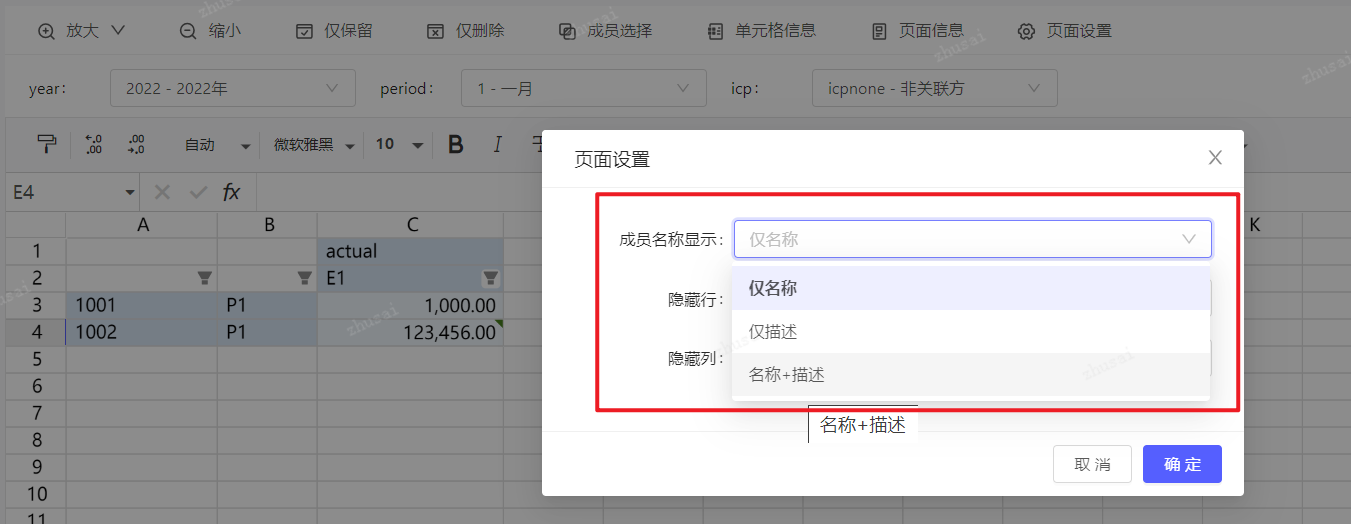
页面设置:隐藏行/列
通过页面设置,勾选隐藏行或列,再执行刷新数据或点击放大成员等操作时,删除行/列。
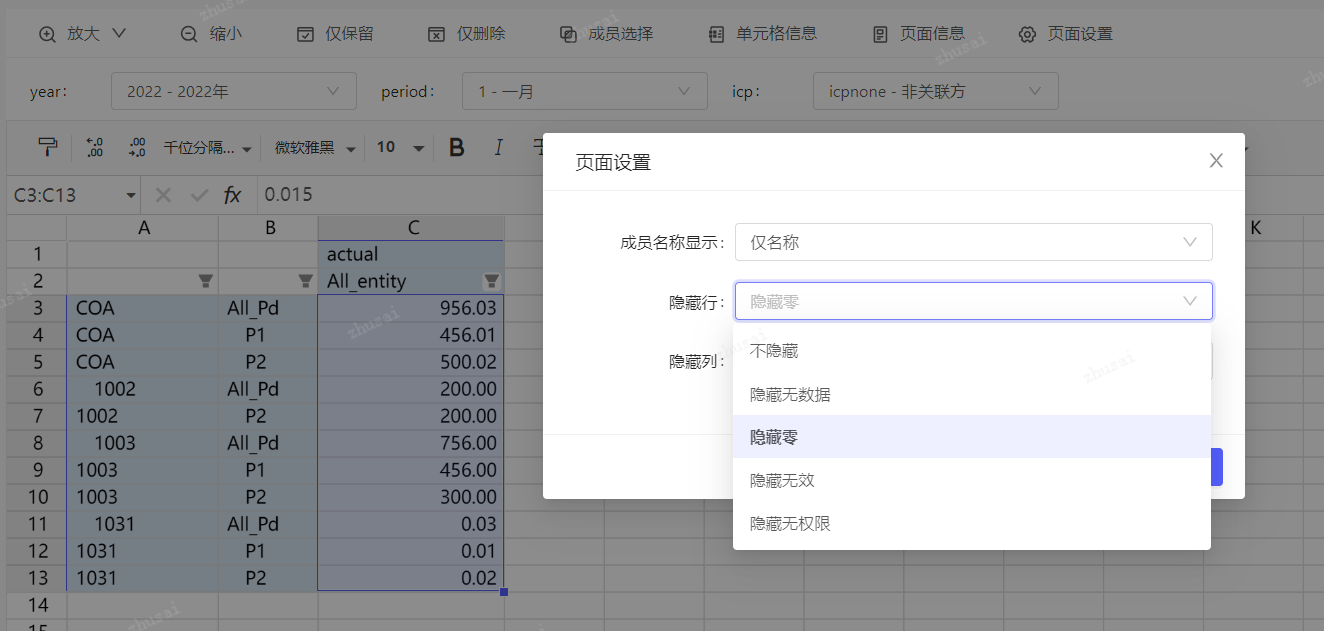
分析结果导出
点击下载按钮,可将当前的分析结果下载到本地excel进行保存。
注意:本版本不提供即席分析结构保存和复用功能,每次进入即席分析,都是从动态表开启一个新的分析。
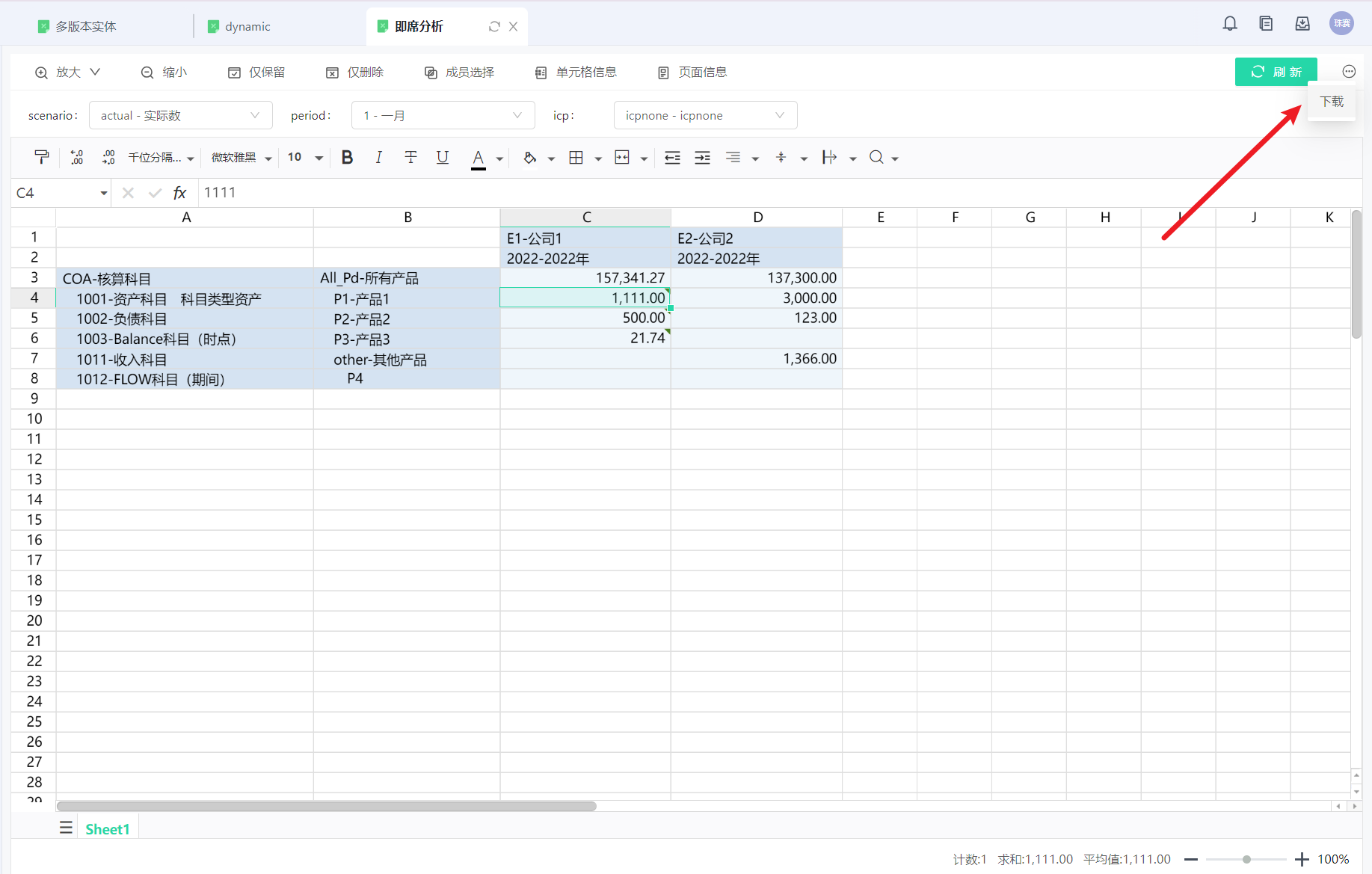
计算脚本
电子表格挂MDX脚本怎么取到POV参数?
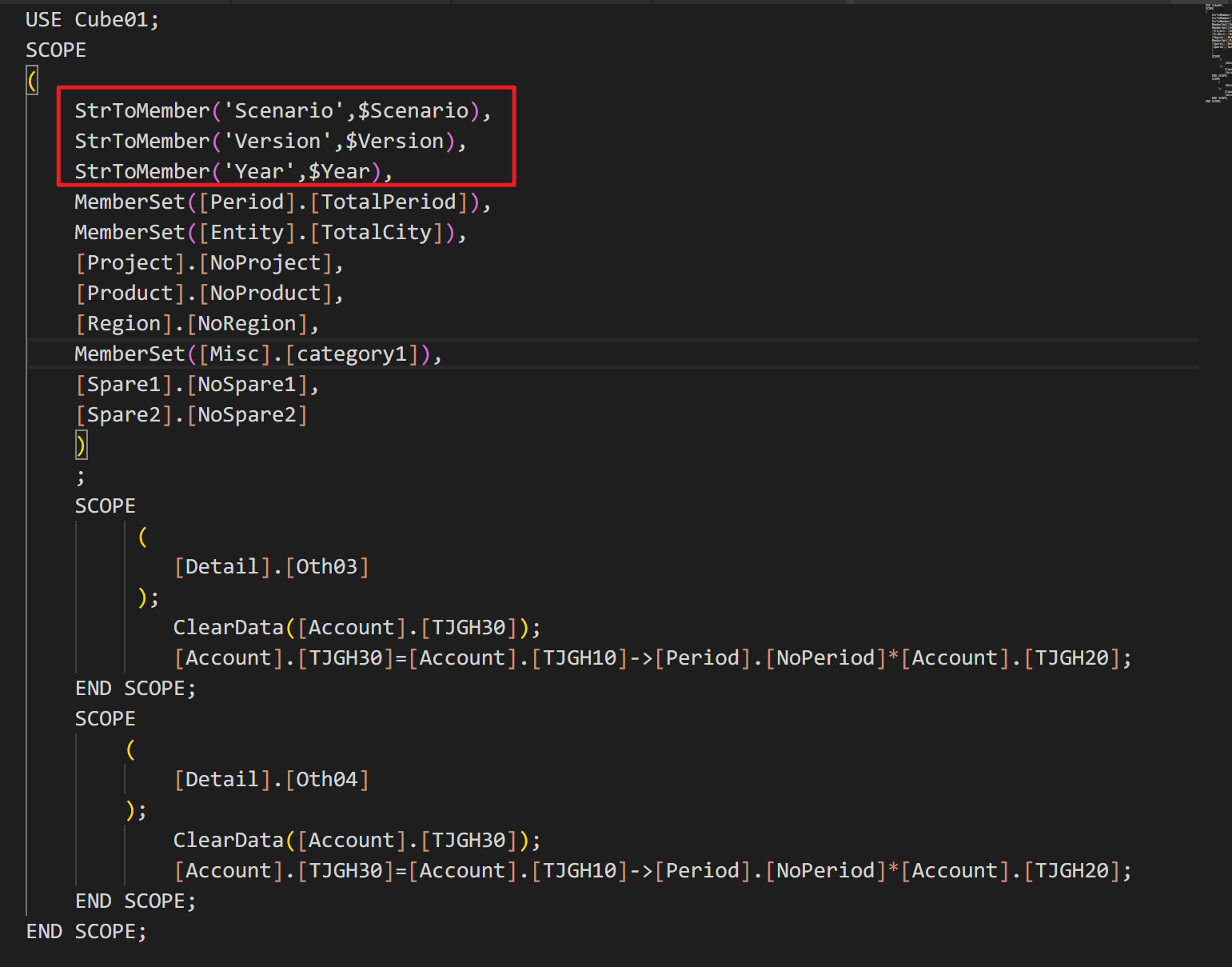
与电子表格1.0不同,1.0可以获取到表格POV作为参数传递给计算脚本,在表格2.0中,将筛选器作为默认参数给计算脚本

解决方案:将筛选器编码直接作为脚本里的参数进行使用 或 ** 配置参数映射表 ,将筛选器映射到脚本自定义参数**
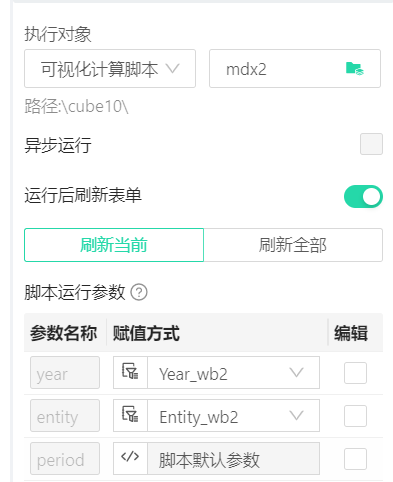
添加映射之后,除了默认给的筛选器参数外,也会同时提供这几个自定义参数的值

开表前触发计算脚本 , 参数没传过去
注意<表单加载前运行> 和 <开表前/加载筛选器后运行>的区别

<表单加载前运行> :
指整个电子表格元素开始渲染前。此时触发的参数:仅有元素和路径
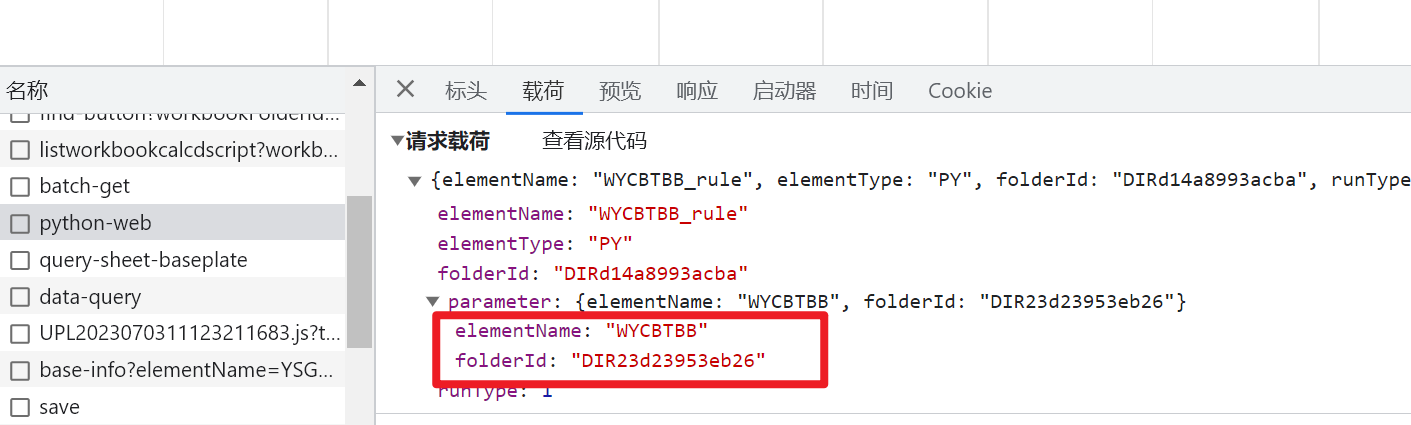
<开表前/加载筛选器后运行>:
指电子表格已经渲染了筛选器,但是还没有渲染Sheet上的数据表格。此时添加算法,可以获取到筛选器值并且将计算后的结果渲染到sheet上。
此时触发的参数:包含了筛选器值、元素、路径
跳转
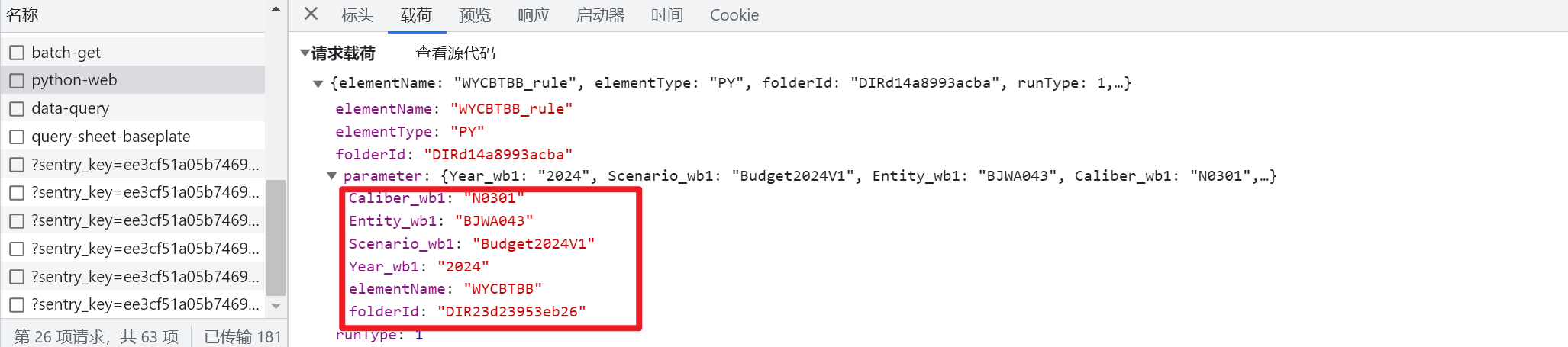
表头上配了跳转功能,跳转到目标表后,部分参数没有传过去
比如下图:年份和版本信息无法给到目标表的筛选器

动态表跳转热区可以配置:整行、整列、表头、自定义维度组合
注意,点击不同的位置,能传递的参数是不同的:
-
行头单元格:财务模型信息、行&pov维度成员,在区域中所处的行号、当前值
-
列头单元格:财务模型信息、列&pov维度成员,在区域中所处的列号、当前值
-
数据单元格:财务模型信息、行&列&pov维度成员,在区域中所处的行号列号、当前值
-
计算的单元格:财务模型信息、pov维度成员,在区域中所处的行号列号、当前值
浮动行
浮动行表关联筛选器后,会自动保存筛选器值到字段吗?
可以关联筛选器,作为查询条件
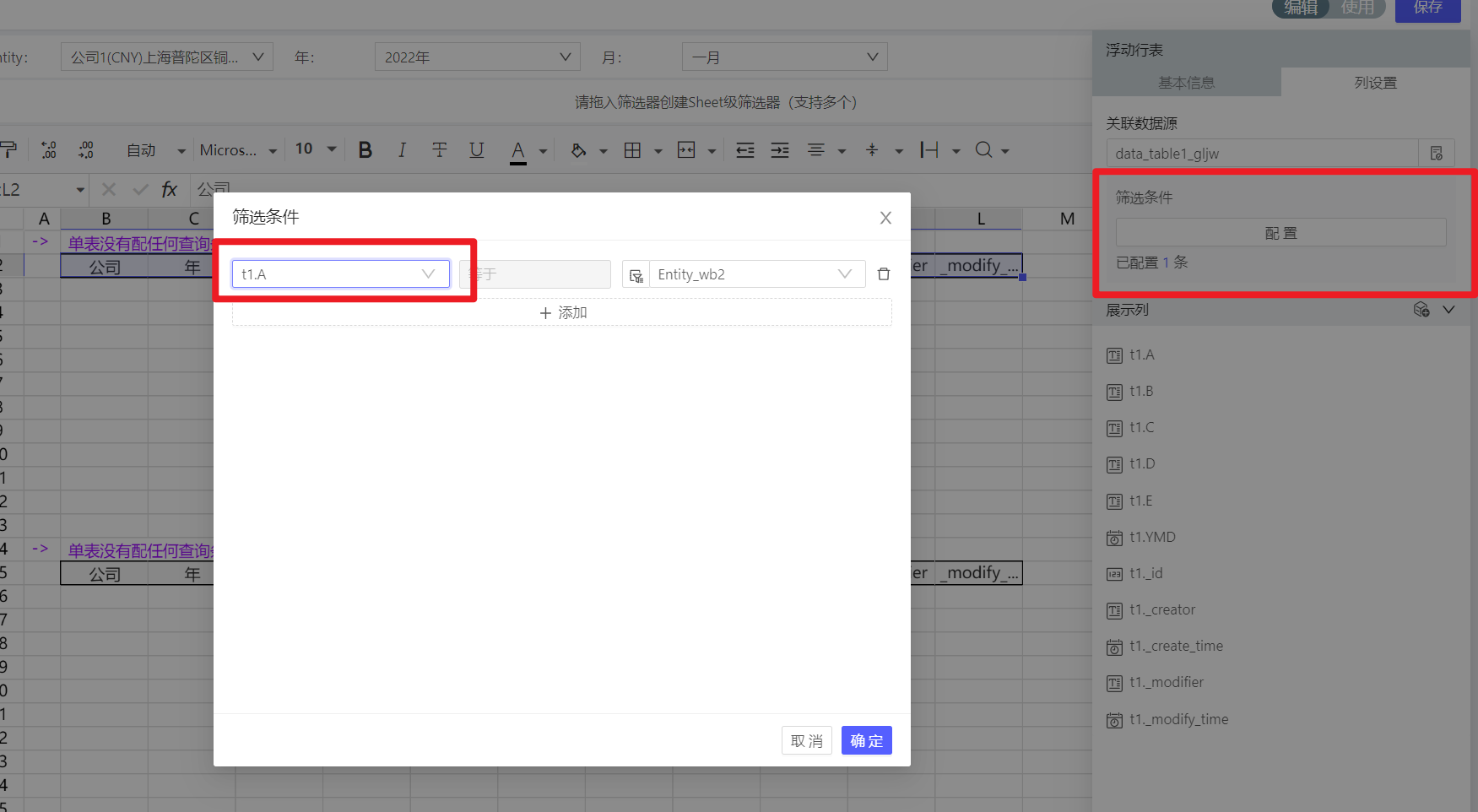
情况1:关联筛选器后,该字段不放展示列上(不是隐藏 , 隐藏时实际列还在),保存时会自动以筛选器值进行保存
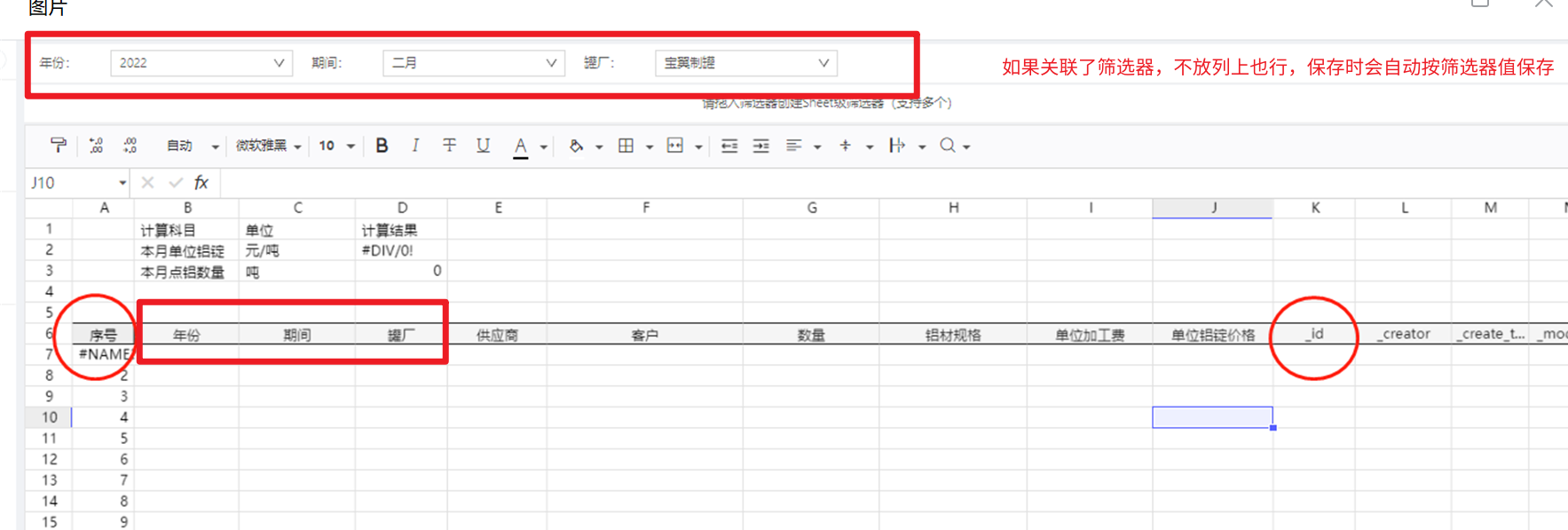
**情况2:**如果该字段同时放在了筛选器和列上,为了支持可选成员范围可能有多个值,保存时以列上填报的值为准(因此,放在列上并关联了筛选器,如果列不填的话,会以空值进入保存过程,就可能出错)
**情况3:**如果该字段仅有一个成员,可以配置该字段的默认值取筛选器,就能实现字段即在筛选器上,又在列上,同时以筛选器值进行保存:
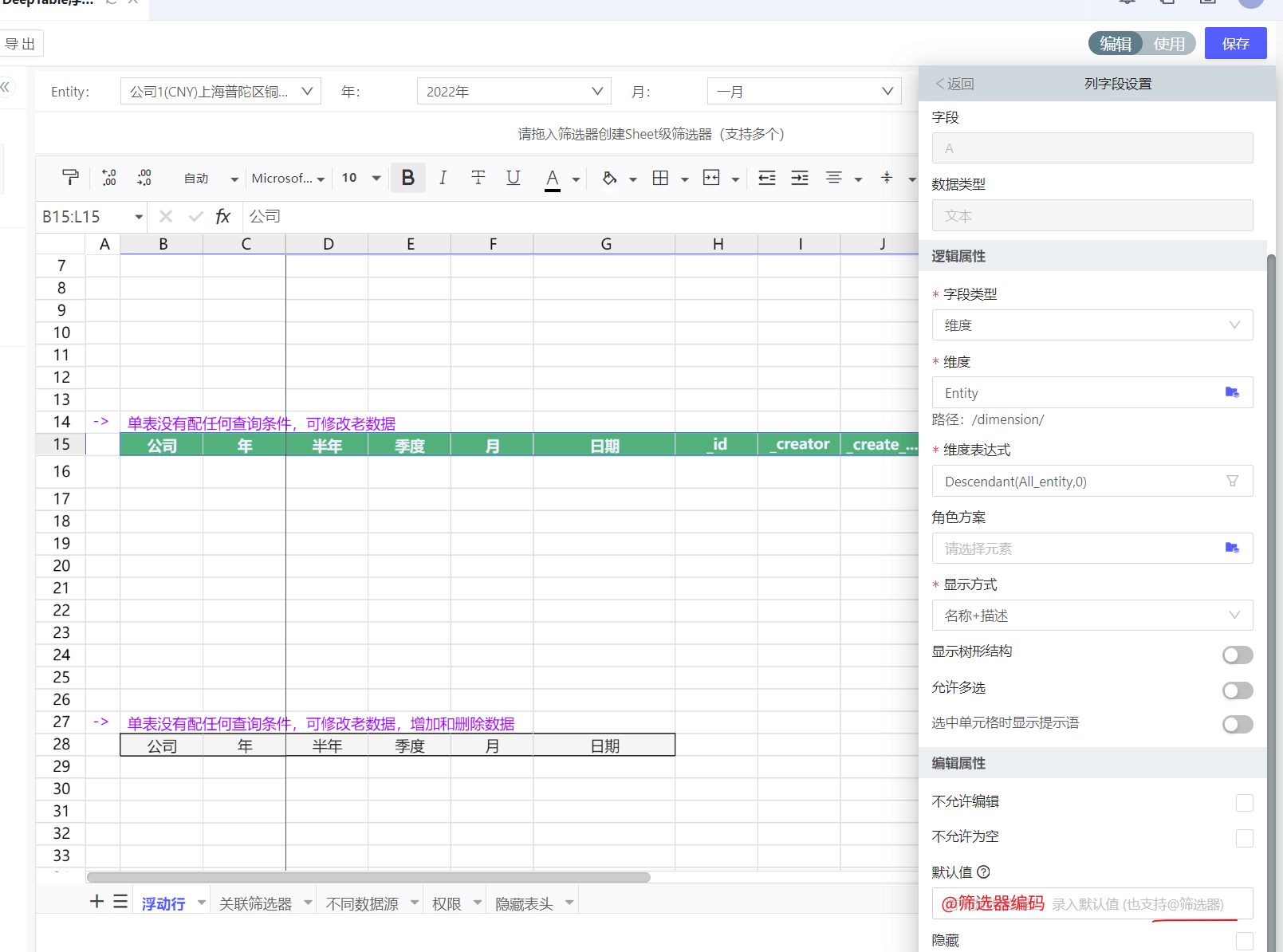
浮动行表如何控制只能填报筛选器对应的公司
当公司同时放在筛选条件和展示列上时,可查看的是A公司,填入B公司数据。
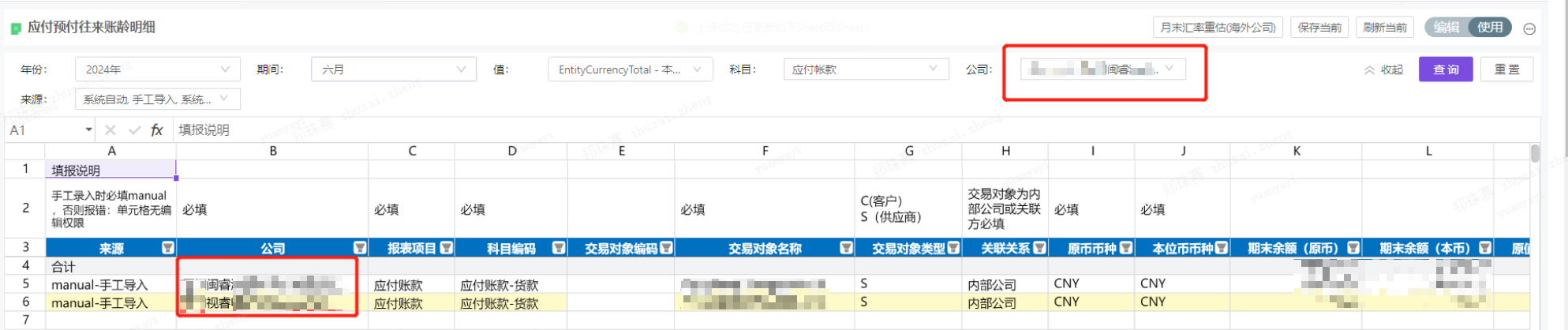
当筛选器关联筛选条件后,主要影响的是数据查询条件,并不绝对意味着保存也是按照筛选器值。
保存时,如果字段在列上或同时在列和筛选,以列上填入的值为准,进行数据保存。如果字段仅在筛选条件,则认为所有填入的值都等于筛选器的值。—此设定是为了当筛选器多选时,查询多个值保存多个值的情况能够适用。
那么如何控制只能填报筛选器对应的公司呢?
-
方案一:公司字段仅配筛选条件上,不放列上
-
方案二:配在列上,但是逻辑属性的可选值=@筛选器,此时若填入其他公司,保存时会出现逻辑属性校验报错(成员超范围)
-
方案三:配在列上,保存时默认值配置为筛选器并开启列只读。此时阻拦了填入其他公司的机会。
当数据源有多个数据表时,怎么写插入SQL及删除SQL
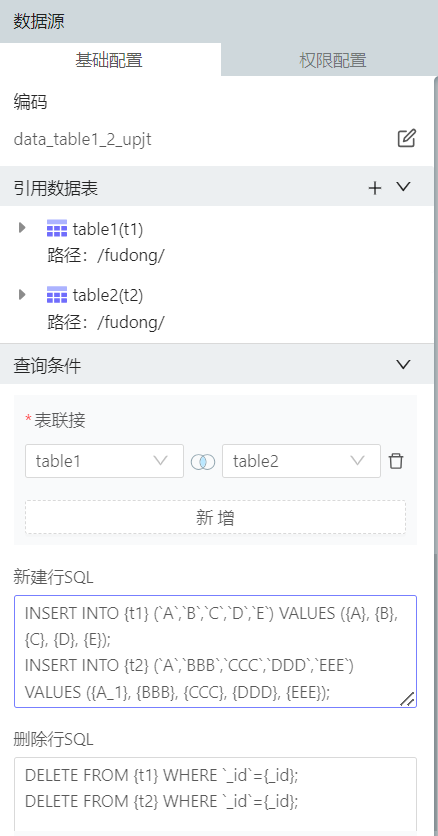 其中,联接字段是A
其中,联接字段是A
插入SQL
INSERT INTO {t1} (A,B,C,D,E) VALUES ({A}, {B}, {C}, {D}, {E});
INSERT INTO {t2} (A,BBB,CCC,DDD,EEE) VALUES ({A_1}, {BBB}, {CCC}, {DDD}, {EEE});
其中A_1是联接字段的别名,可通过此处修改
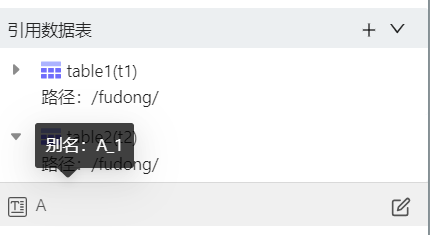
如果,想要把左表的A字段值存到右表,Values直接取A字段即可(t1.A)
删除SQL
DELETE FROM {t1} WHERE _id={_id};
DELETE FROM {t2} WHERE _id={_id};
其中,_id是物理字段名,删除操作时,前端会将某一行数据代表的各表id给到后端,执行删除操作。
多版本实体维筛选器启用父子结构后,在浮动行中关联筛选器,查询不到数据
多版本实体维,实际存储到数据表中,依然是以纯子结构存储的数据。
动态表对应的财务模型接口做了特殊逻辑,当没有value或value等于ParentCurrency以下,不管成员写A.B 还是 C.B 还是 B,都从B成员取数,但是浮动行表则没有财务模型的这些转换逻辑,他不会自动将不同写法的成员识别为同一个。
所以,当筛选器传 父.子 结构的成员作为浮动行表的查询条件时,就找不到数据了,只能通过修改筛选器维度表达式的第三个参数,传纯子成员作为查询条件。
但是当workbook有多个sheet页的时候,比如有动态表需要父子结构的话,有浮动行表需要子结构,建议设置多个筛选器并且配合隐藏来解决。
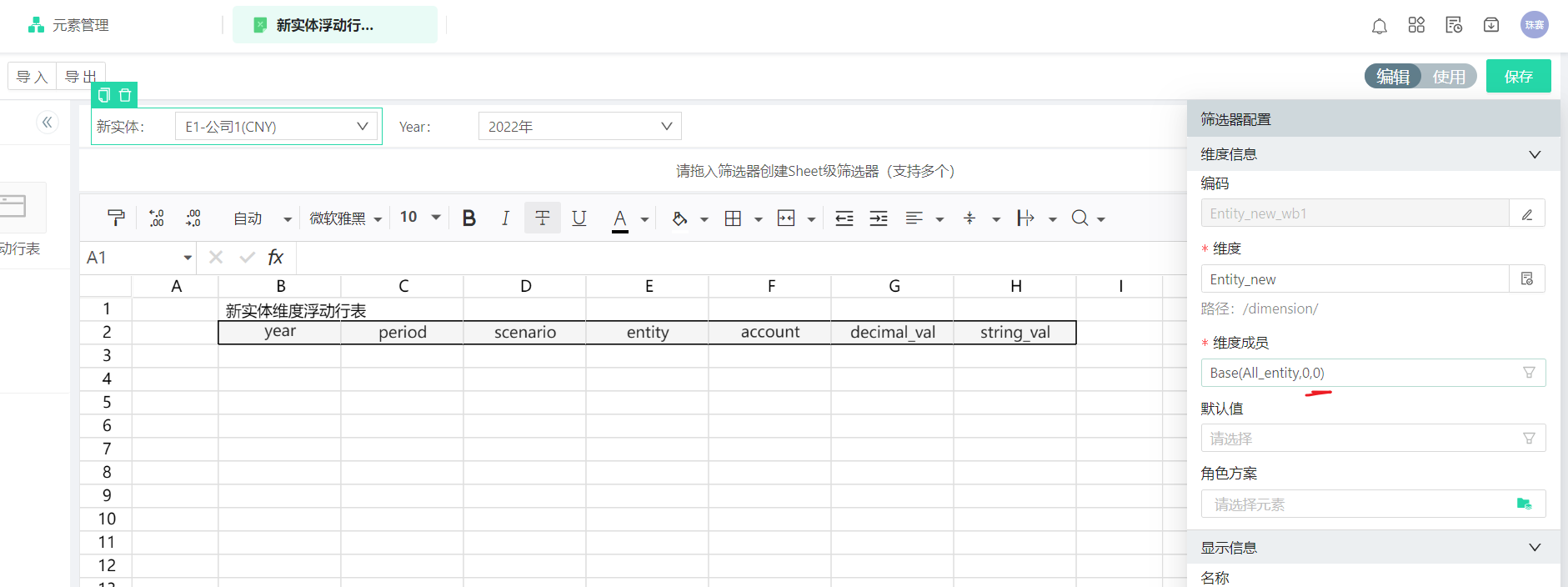
如何限制浮动行查询出来的行数,比如只要前10行
在数据源中填入limit条件
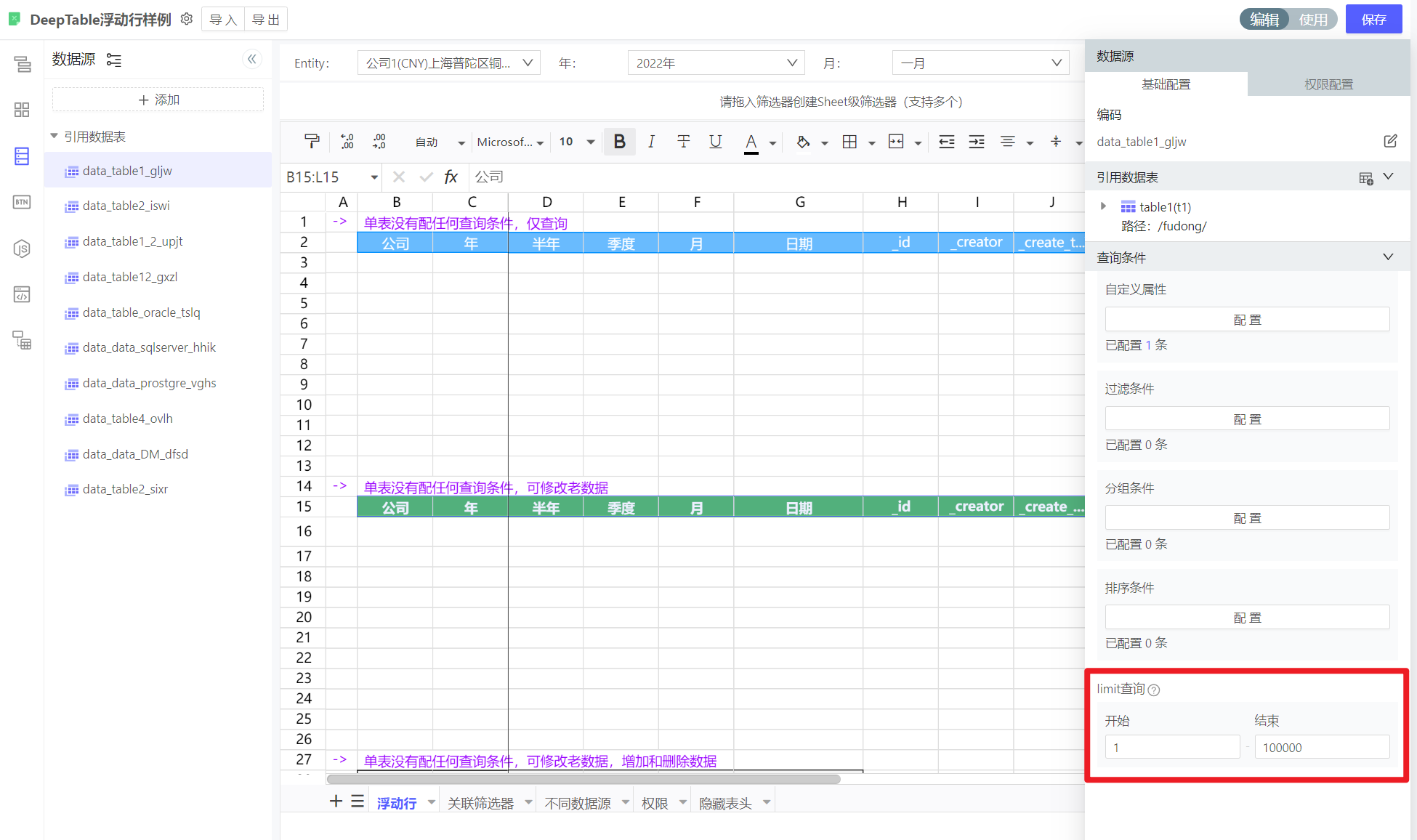
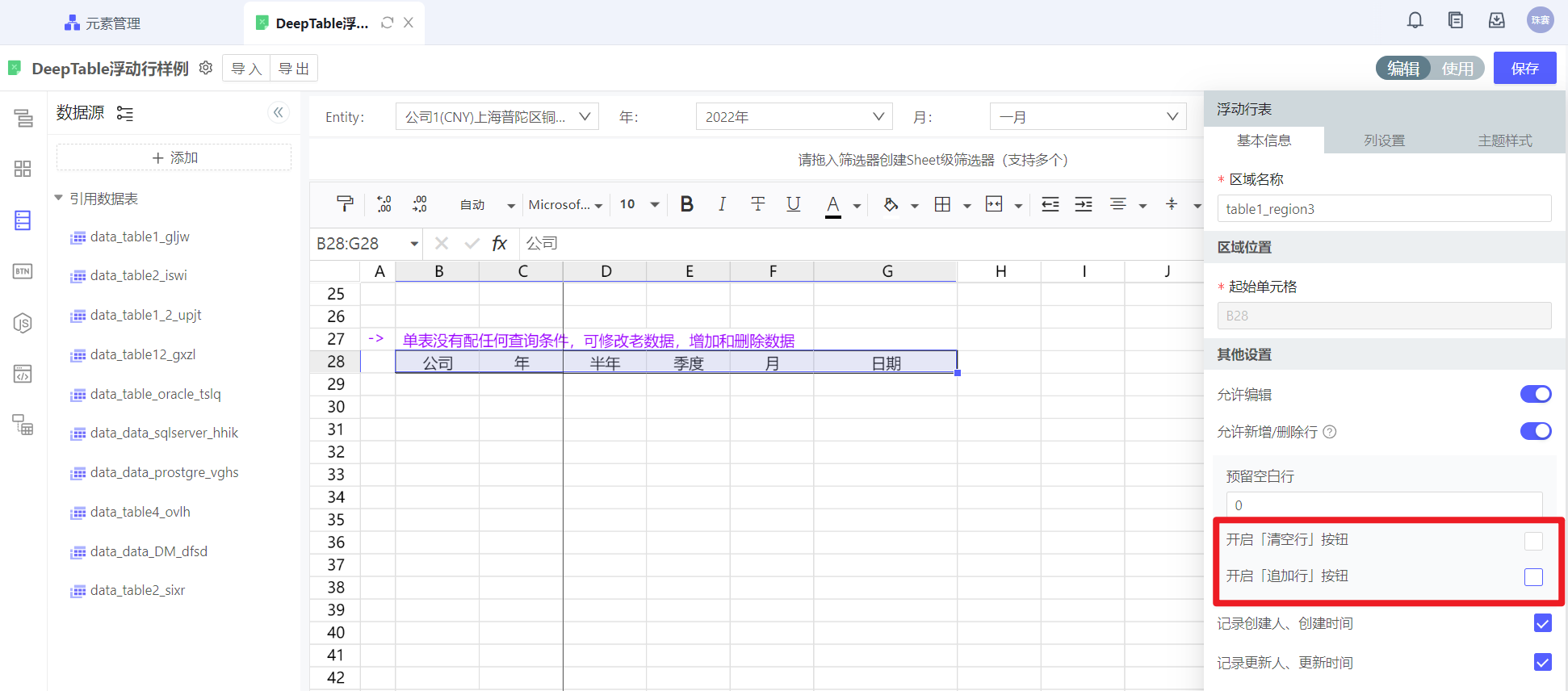
浮动行表如何在使用态删除行
在浮动行中,默认假设:如果浮动行区域的整行数据都被清除,对应数据表执行删除记录操作(删除某个id的行)。但是,如果一个填报区域中,有计算的列处于只读状态(或配置只读列),用户就无法将整行清除内容,也就无法达到数据表删除行效果。
在编辑态,启用清空行按钮
浮动行表如何在使用态增加空白行
场景一、不同单位数据量差异大:浮动行表用于填报时,每次刷新后,在现有的数据基础上,最多预留10000行空白行。但是,对于个别情况,比如同一张表,A公司仅需要填报10行,B公司需要填报10000行,不同的公司差异较大,难以取舍预留数。
场景二、需要一次性导入超过10000行的数据:基于目前表格2.0多区域的设定,浮动行表区域是有边界的,超过边界的数据无法保存。
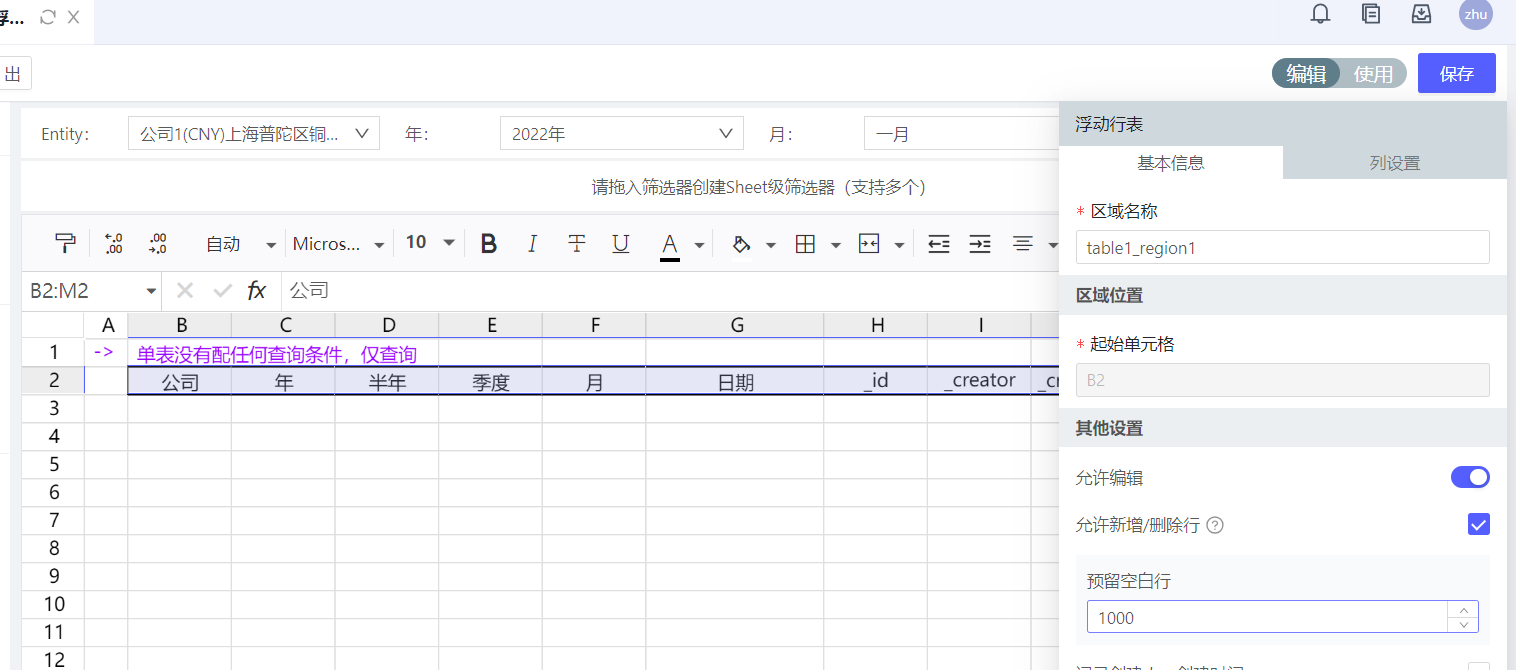
在编辑态,启用追加行按钮,默认1-1000,根据需要可配置5000,10000。注意,如果浮动行表列数较多,整体超多50万单元格,需考虑性能问题。
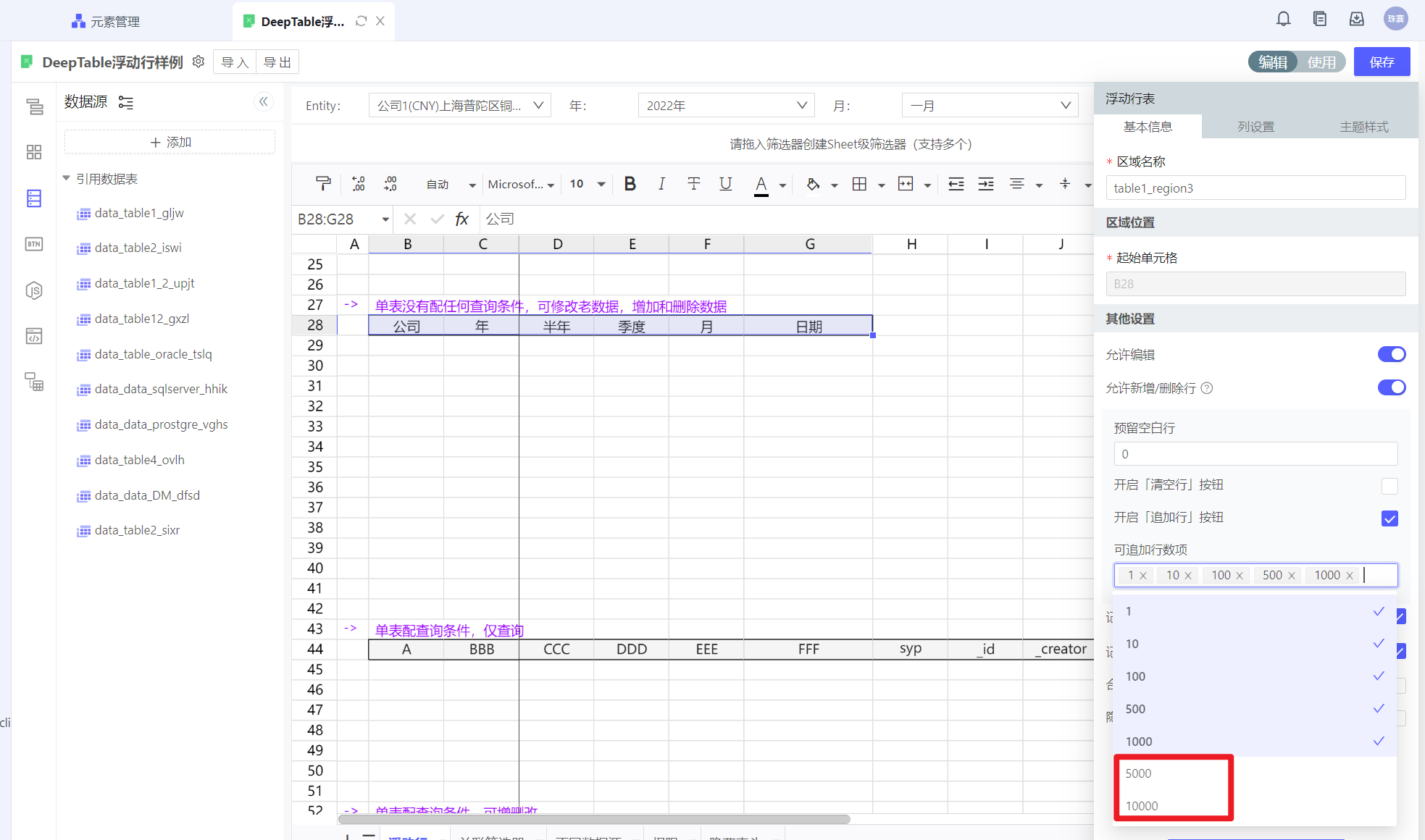
注意,建议此时编辑态画布大小不要设的过大,以免数据较少时,浮动行区域内的空白上和画布本身的空白行 ,造成用户混淆。
怎么控制浮动行表只有10行可填,每次保存后,不会再多出新的10个空白行
可以配置允许新增,并预留空白行0,
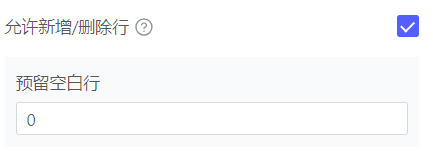
然后,使用insertFloatTableRow JSAPI,判断当前小于10行时,插入(10-现有数据行数)行。
浮动行表Groupby之后,金额只有原始数据的第一行,没有自动汇总
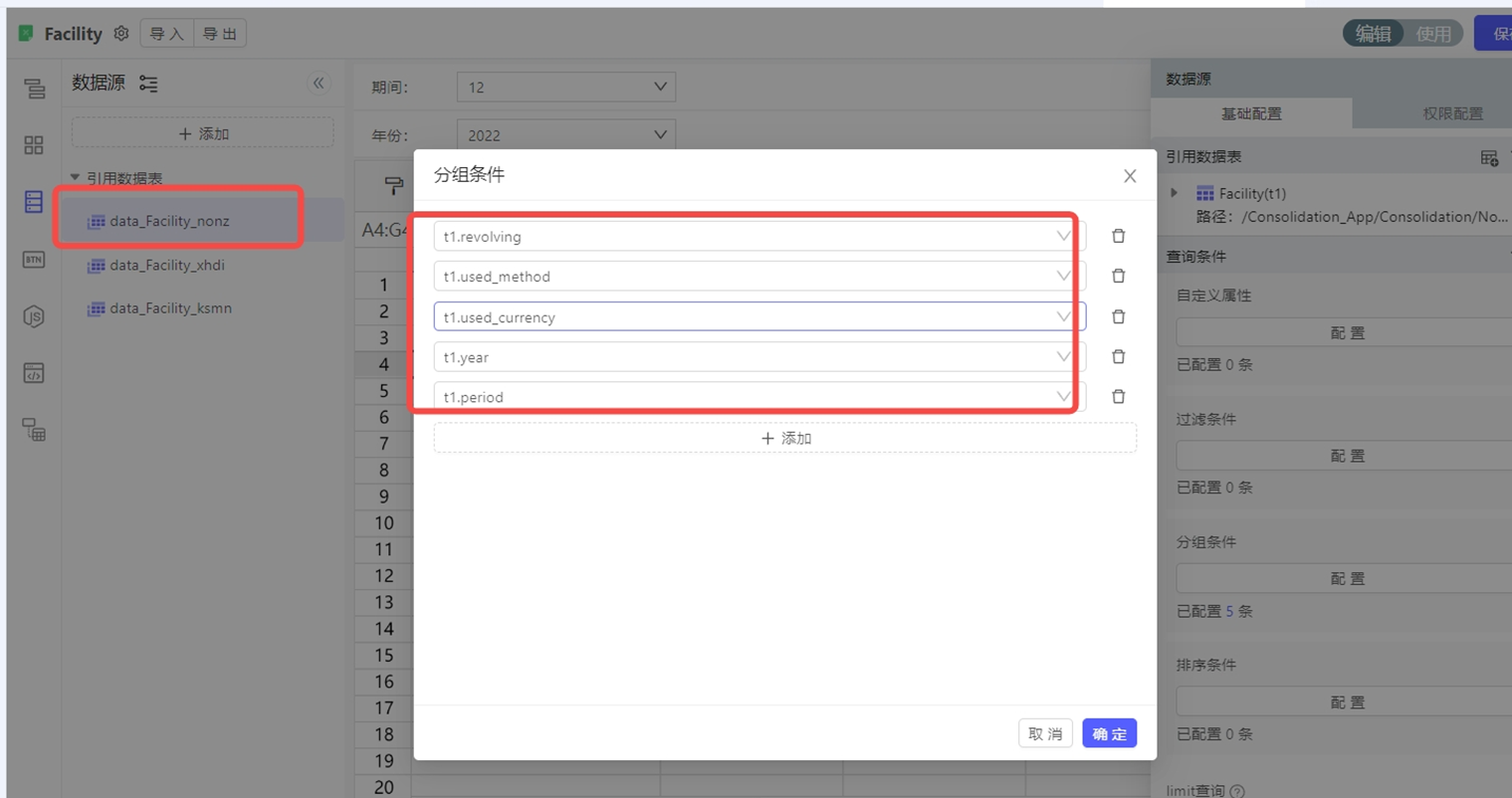
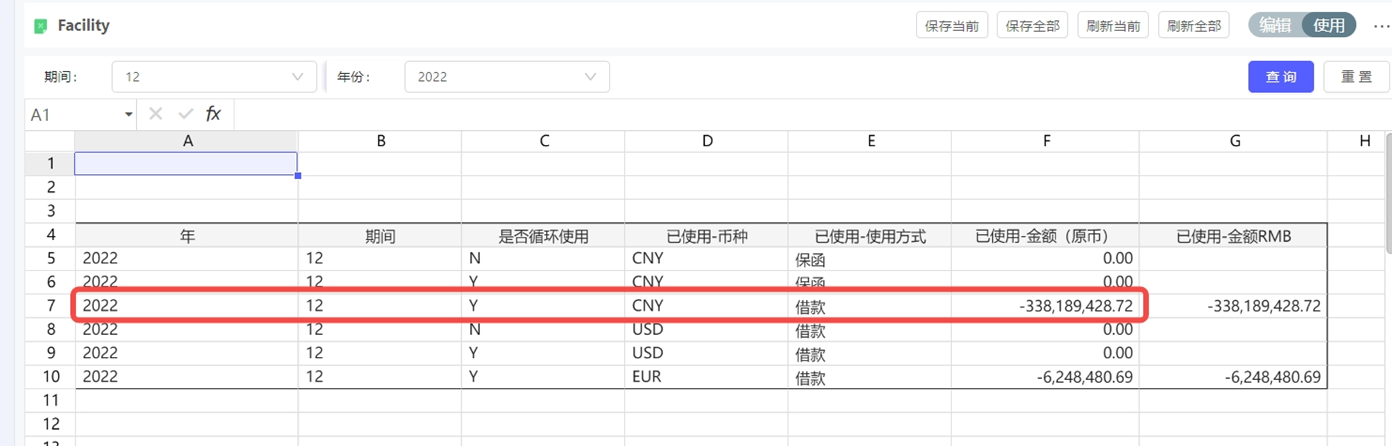
Groupby只负责分组,不负责非分组字段进行SUM聚合
非分组字段只能拉到分组后的第一条
如果需要聚合,可以添加自定义列/属性,使用聚合函数进行计算,比如sum(金额字段)
数据源的处理只有Join,如果想要Union怎么办?
比如有下述两张结构相同的表,想要上下拼在一张表里展示
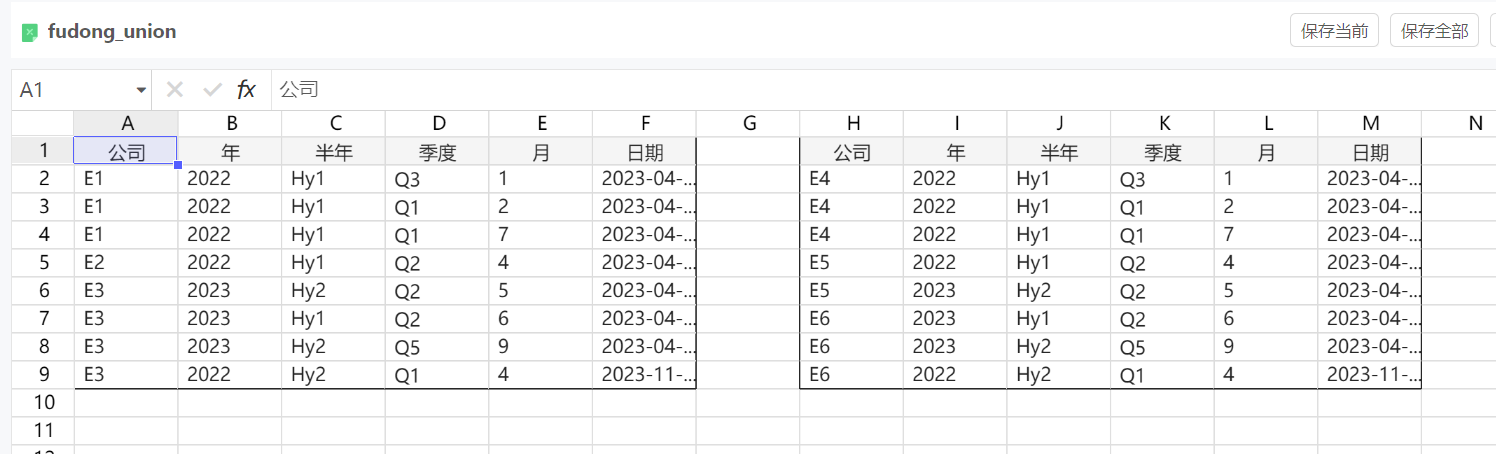
变相的实现方法供参考:
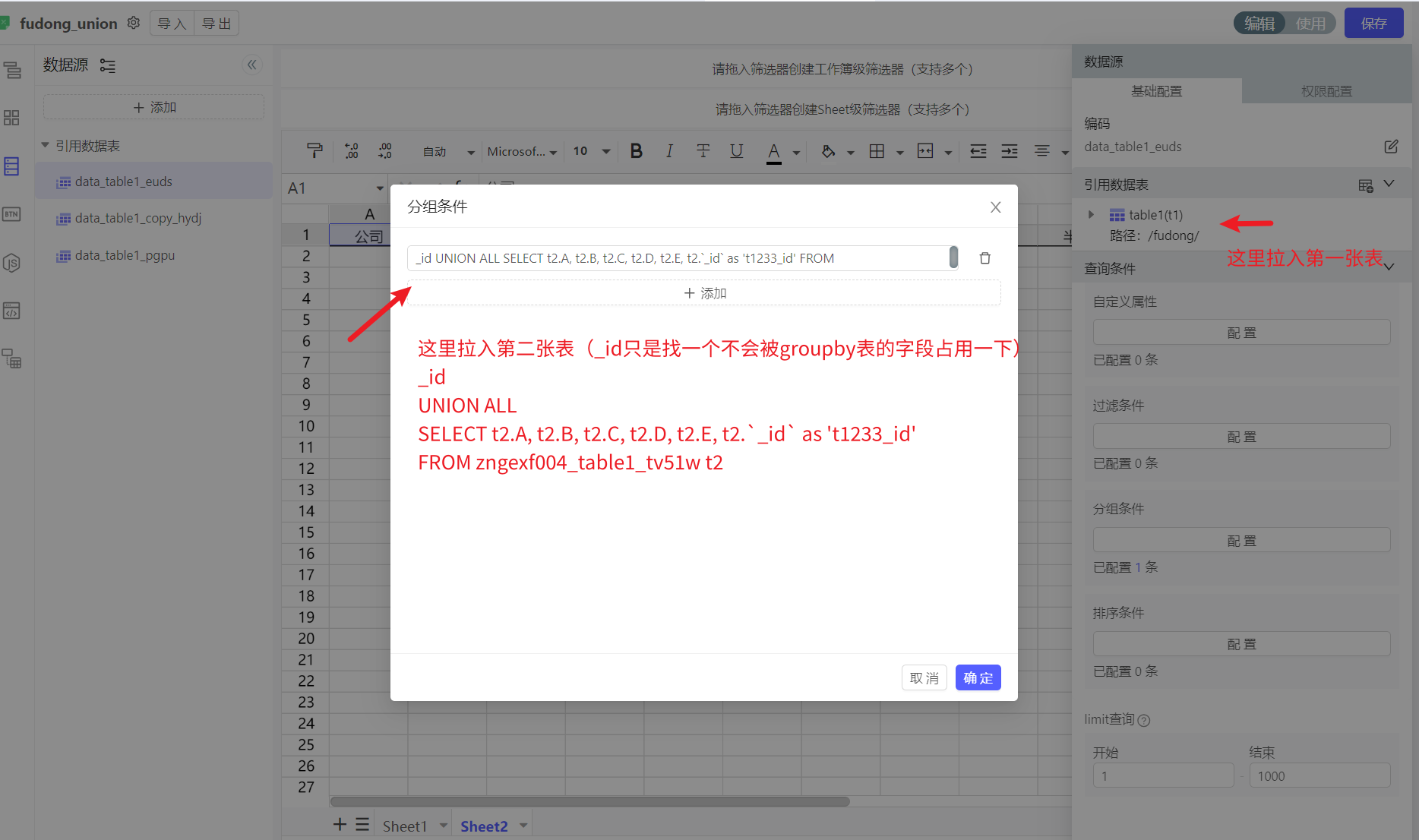
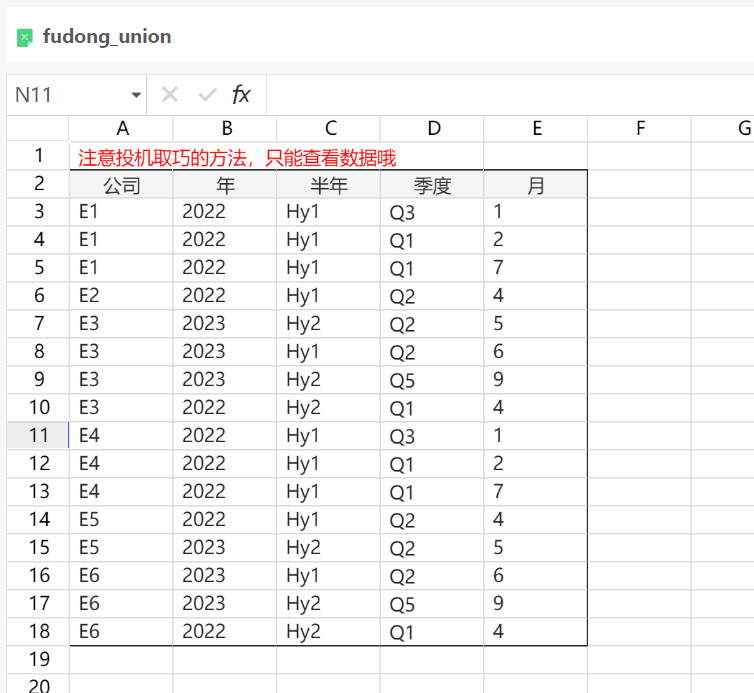
注意:只能查看数据哦,编辑的话因为union过来的表没有实际lineid,更改不了
Excel只有n位小数,上传到电子表格后小数不一样了。
Excel显示的小数位与上传到电子表格后的小数出现不同的情况主要原因是Excel本身显示精度与存储精度不同导致的。
Excel显示精度:15位,存储精度17位。比如一个数据31203713.290000003,由于超过显示精度,因此Excel显示为31203713.29,用户看到这个数据,表面以为只有2位小数,实际存储是多位小数。电子表格的显示精度和存储精度都是17,因此,就与Excel显示的不一样了,但不妨碍实际的数据都是17位。
查询Excel实际数据的方法见下视频,总体来说,Excel数据具有一定的迷惑性:
小数位数会影响数据上传的质量,比如浮动行报表,我们一般会在数据表中设置小数位数,如果超过小数位数,即使电子表格填报侧绕过了校验,到数据表服务依然会报错和不让存储。
实施时可在浮动行表上,开启自动四舍五入功能:
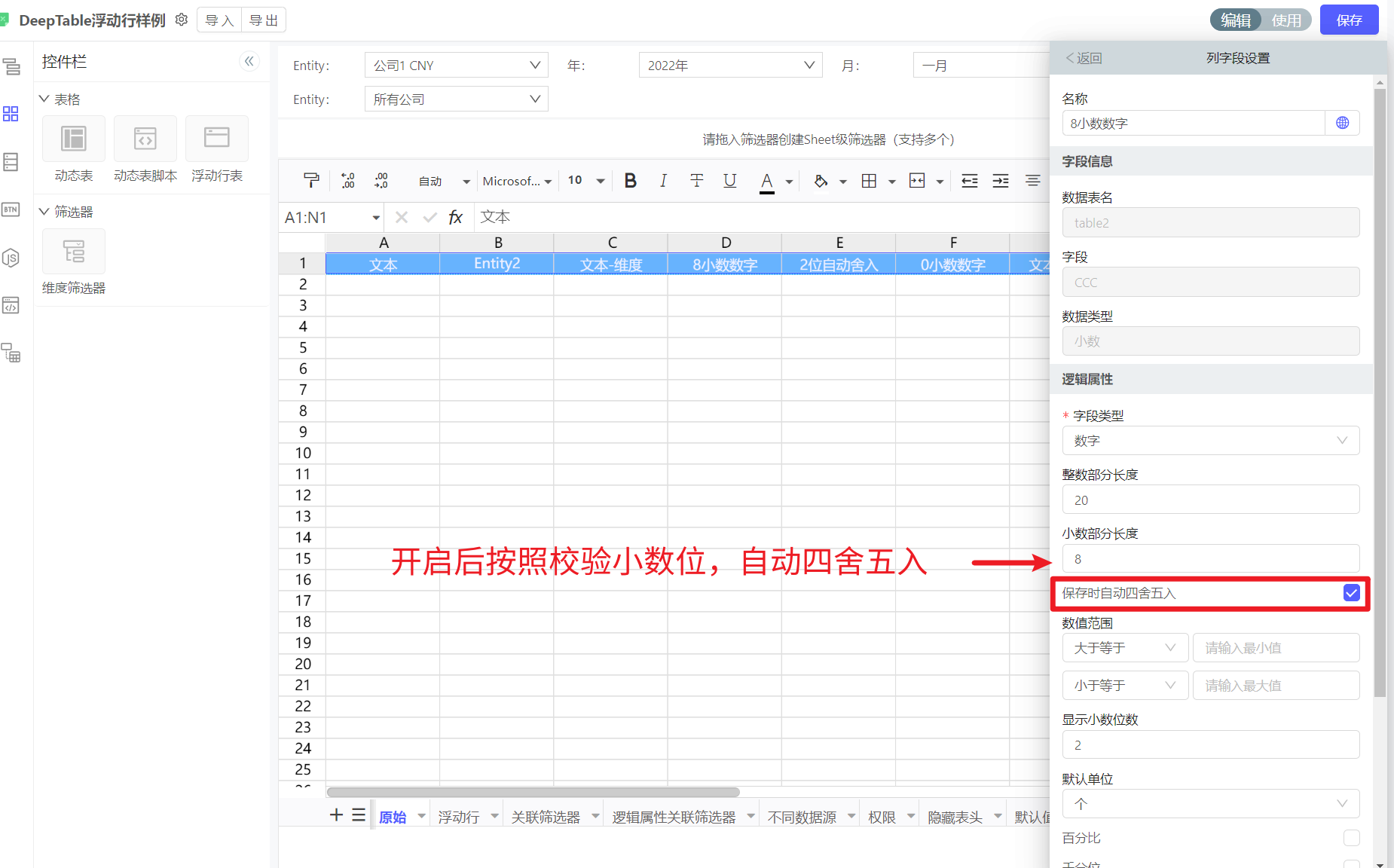
对上传后的数据进行加工后再保存到数据表。
自定义JS
自定义JS支持哪些API
见自定义JS使用手册
自定义JS写法
书写自定义JS的标准结构
export default () => {
const function_name = function (params) {
//自定义函数的具体代码
//function_name:自定义函数名
};
return {
function_name,
}
}
注意,写完函数后,需要return函数体function_name,并且挂载在电子表格的执行钩子上。
目前执行自定义JS的钩子有:
工作簿设置:
开表前/加载筛选器后:仅部分API可用(比如筛选器相关API),一般是开表前(加载具体的sheet前)配置筛选器联动时需要
Sheet设置:
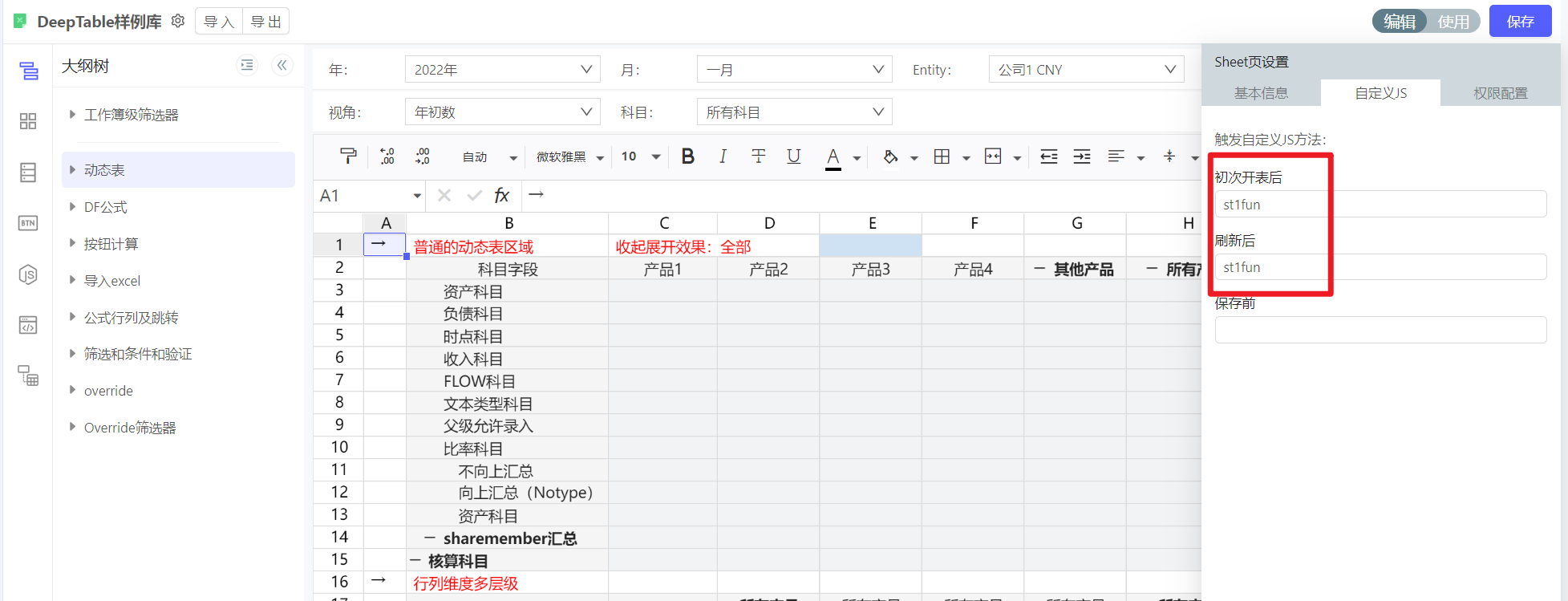
初次开表后:首次加载Sheet后需要执行的自定义JS函数。
刷新后:后续重新查询报表(比如切换筛选器后查询)需要执行的自定义JS函数
保存前:数据保存前执行的自定义JS函数。
动态表行数不确定,怎么用JS添加excel计算公式
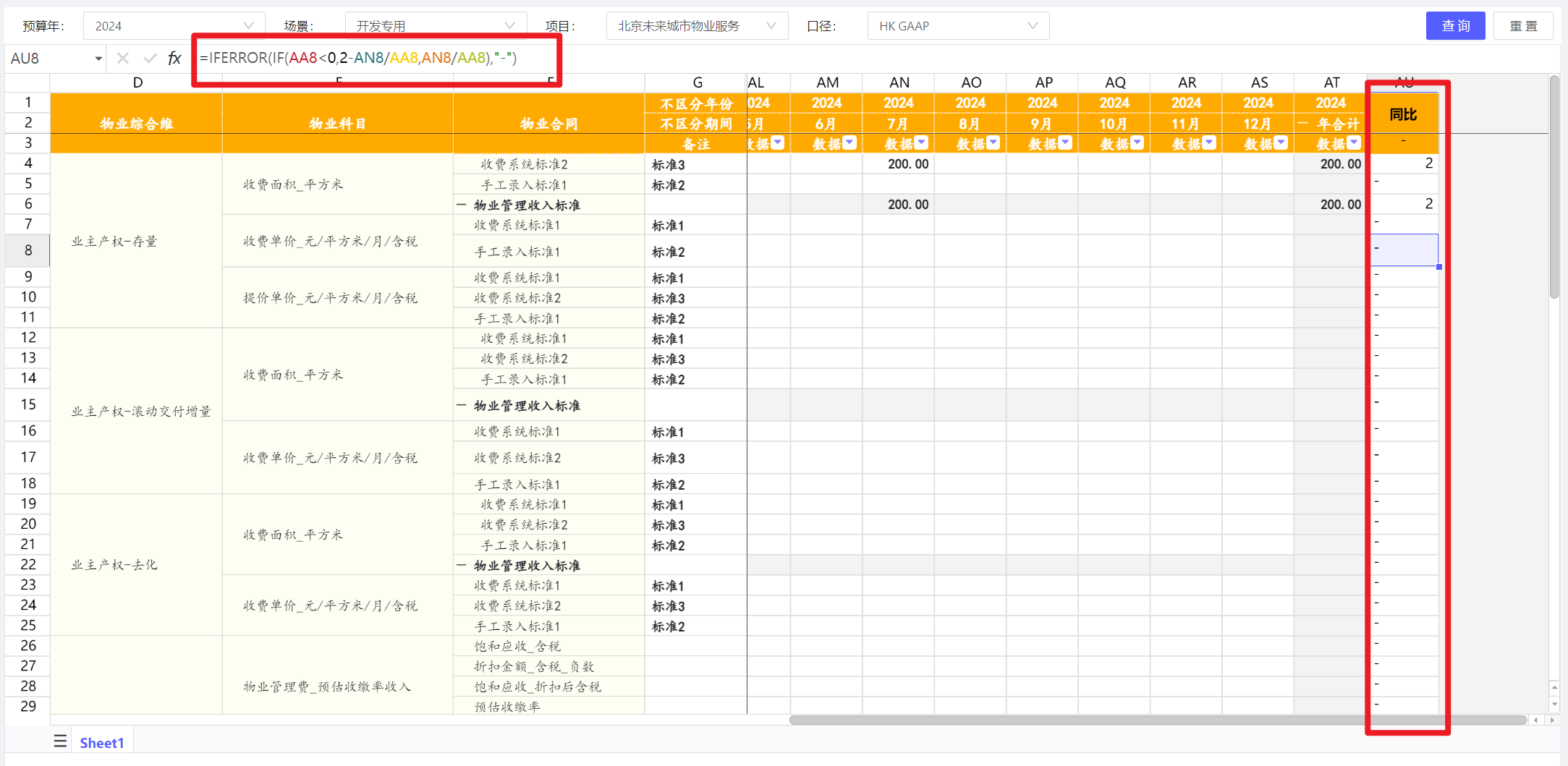
注意:优先使用动态表公式,大部分场景下可支持
超出支持部分优先考虑用Python或MDX实现
最末考虑用JS,参考如下代码:
export default () => {
const formula = [
{
index: 0,
formula: [
['AU', '=IFERROR(IF(AA{row}<0,2-AN{row}/AA{row},AN{row}/AA{row}),"-")'],
],
},
];
const viewRow = 3,
viewCol = 1;
const init = (index, { luckySheetApi: {suspendDraw,suspendCalculate,getRowCount, setCellValue, setCellFormula} }) => {
// console.log('luckySheetApi: ', luckySheetApi);
const config = formula.find((item) => item.index === index);
let rowCount = getRowCount(0)
suspendDraw(true)
suspendCalculate(true)
for (let row = viewRow; row < rowCount; row++) {
for (let i = 0; i < config.formula.length; i++) {
const [col, formula] = config.formula[i];
const value = formula.replace(/{row}/g, row + 1);
setCellFormula(index, row, ltn(col), value);
//setCellValue(index,row,ltn(col),i)
}
}
suspendCalculate(false)
suspendDraw(false)
};
const init1 = (params) => {
init(0, params);
};
return {
init1,
// init2,
};
};
// 工具函数
const ltn = (letter) => {
let num = -1;
const len = letter.length;
for (let i = 0; i < len; i++) {
num += (letter.charCodeAt(i) - 64) * Math.pow(26, len - i - 1);
}
return num;
};
const ntl = (num) => {
let letter = '';
while (num >= 0) {
letter = String.fromCharCode((num % 26) + 65) + letter;
num = Math.floor(num / 26) - 1;
}
return letter;
};
注意,如果是在动态表已有行列的基础上添加公式,需要避开汇总单元格(因为汇总单元格没有权限,保存时会报错。)
如果数据不需要保存,可通过syncOriginData(具体见JS API文档)接口进行处理
动态表样式可以配置数字居中吗?
暂时没有标准功能支持居中样式的修改,只能通过自定义JS,如下代码供参考
import { message } from '/package-base/antd4.mjs';
export default () => {
//获取Sheet1单元格内容
const st1fun = function (params) {
const {luckySheetApi:{suspendDraw,getSheet}} = params;
suspendDraw(true)
let sheet1 = getSheet(0); //返回sheet1下面的所有luckysheetapi
console.log('开始啦');
//将第5行的3至41列修改为居中
let i=2;
for (i=2; i<40; i++) {
sheet1.setHorizontalAlign(4,i,'center');
}
console.log('搞定啦');
suspendDraw(false)
};
return {
st1fun,
}
}
如何根据筛选器和每行选择,出来不同的下拉列表(有筛选字段、行字段、下拉字段的关系表)
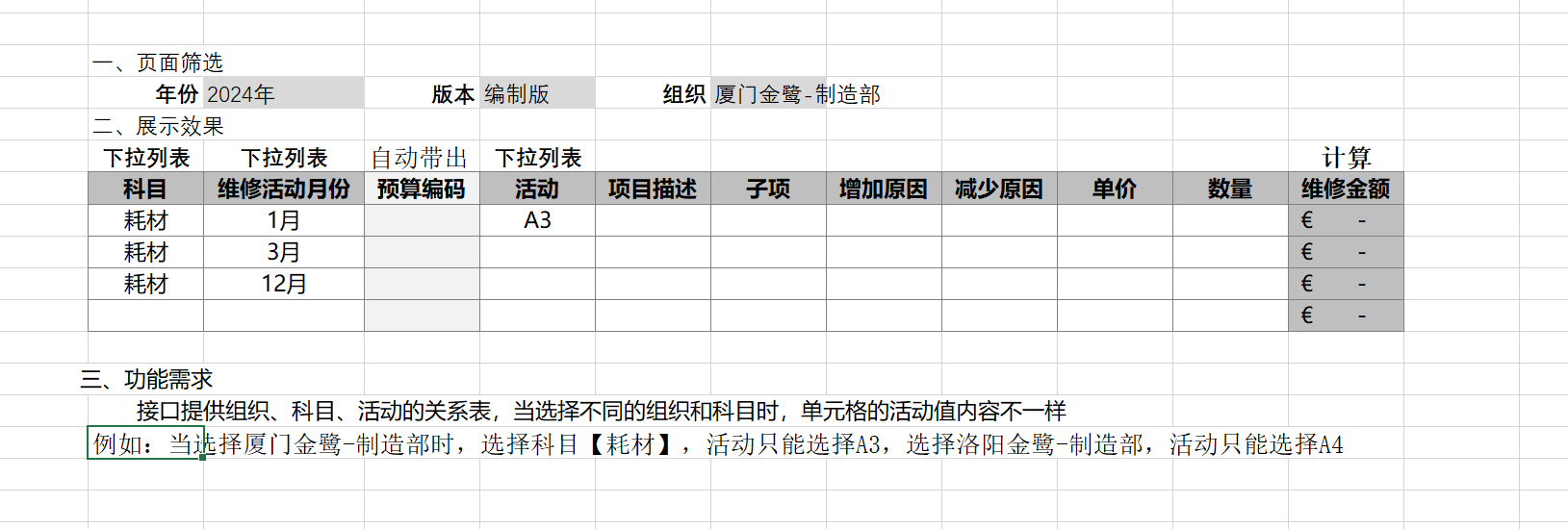
大致实现思路是:在科目列上通过单元格变更事件,查找映射表,生成对应的下拉列表
1、科目列的单元格发生变更时
涉及如下JS API
-
bindEvent
-
getCellValue
-
getFilterMember
-
DataVerify
浮动行表某列通过excel公式从其他列计算而来,追加行时如何处理
为了实时展现某列的计算结果,有些项目可能会采用自定义JS的方法在浮动表开表时叠加计算公式,但是若用户需要在追加行,填报时追加的行上没有公式,导致存入数据库时此列无值。
比如此例:A列=B列
注意:不可直接写公式=B2,而应该写 = if(B2=0,””,B2),这样空数据行不会因为计算产生一个0数据。
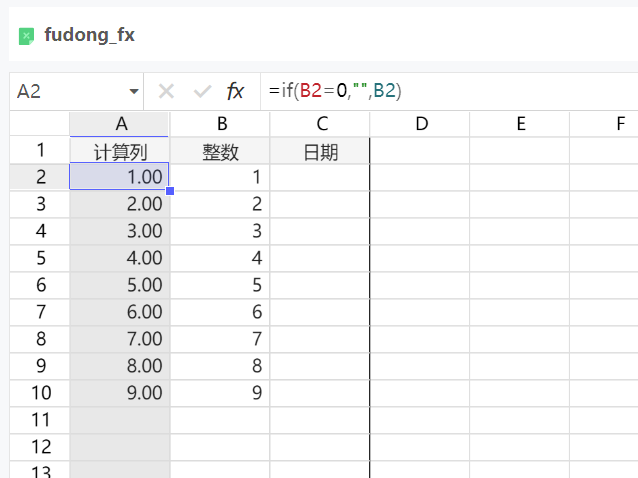
实现时:
1、配置计算列只读,以免用户修改
2、在追加行动作上,绑定事件,参考代码
params.luckySheetApi.syncOriginData(true);
deepTableApi.bindEvent('afterFloatTableInsertRow', (evt) => {
const {sheetIndex,areaName,startRow,insertRowNum} = evt;
for (var i=startRow; i<200; i++) {
sheet1.setCellFormula(i,0,'=if(B'+(i+1)+'=0,"",B'+(i+1)+')'); //在单元格添加公式
}
})
params.luckySheetApi.syncOriginData(false);
跳转非电子表格元素-自定义JS参考案例
目标标准功能只支持跳转电子表格2.0/1.0,若要跳转到其他类型元素,可通过自定义JS。
注意:sign和folderid随着应用变化,可采用下述方法,使元素在不同的应用间迁移时兼容。
import { extend } from '/package-base/@deepfos/request@2.0.0.mjs';
const appServer = extend({
prefix: `/deepfos-server/app-server`,
});
export default () => {
const getsignFromUrl = () => {
const str = window.location.search.substring(1);
const list = str.split('&');
const obj = {};
list.forEach(item => {
const arr = item.split('=');
obj[arr[0]] = decodeURIComponent(arr[1]);
});
const sign = obj['sign']
//const info = atob(decodeURIComponent(obj['sign']));
//const appId = info.split('&');
return sign;
}
// ======================跳转凭证清单======================
let elementName1="Journal_Report"
let moduleId1="JL1_0"
let Path1="/Consolidation_App/Journal/Journal_Report/"
//let folder
let folderId1 = '';
appServer.get('/folders/get-folder-id/by-full-path', {
params: {
fullPath: Path1
}
}).then(res => {
folderId1 = res;
});
const jump_jr = (params,context) => {
const { cube, povDimension, cellDimension, value } = context;
let pov = {
"entity2": povDimension.entity,
"scenario2": povDimension.scenario,
"version2": povDimension.version,
"year2": povDimension.year,
"period2": povDimension.period,
}
return `/element-journal/1-0-0/list?pov=${JSON.stringify(pov)}&elementName=`+elementName1+"&folderId="+folderId1+"&moduleId="+moduleId1+"&sign="+getsignFromUrl()
}
// ======================跳转分组报告======================
let elementName2="InterCo"
let Path2="/Consolidation_App/RR/"
//let folder
let moduleId2="GR1_0"
let folderId2 = '';
appServer.get('/folders/get-folder-id/by-full-path', {
params: {
fullPath: Path2
}
}).then(res => {
folderId2 = res;
});
const jump_rr = (params,context) => {
const { cube, povDimension, cellDimension, value } = context;
let pov = {"pov":{
"entityPartners":
[{
"entityText": povDimension.entity,
"partnerText": povDimension.entity
},],
"head.year": povDimension.year,
"head.period": povDimension.period,
}}
return `/element-group-report/1-0-0/report/use?customConfig=${JSON.stringify(pov)}&elementName=`+elementName2+"&folderId="+folderId2+"&moduleId="+moduleId2+"&sign="+getsignFromUrl()
}
//======================跳转清单表======================
let elementName3="815"
let Path3="/Consolidation_App/RR/"
//let folder
let moduleId3="LST1_2"
let folderId3 = '';
appServer.get('/folders/get-folder-id/by-full-path', {
params: {
fullPath: Path3
}
}).then(res => {
folderId3 = res;
});
const jump_list = (parmas, context)=>{
const { cube, povDimension, cellDimension, value } = context;
let pov = {
CPMC1: povDimension.entity
}
return `/element-list-table/1-2-0/?pov=${JSON.stringify(pov)}&elementName=`+elementName3+"&folderId="+folderId3+"&moduleId="+moduleId3+"&sign="+getsignFromUrl()
}
return {
jump_jr,
jump_rr,
jump_list,
}
}
展现层权限
展现层权限定义
在电子表格中,涉及权限的控件有:
-
动态表、DF公式:使用财务模型权限
-
浮动行表:使用数据源权限
-
筛选器权限:按筛选器配置继承维度/自定义
-
sheet、按钮权限:按sheet配置
我们将使用到的这些权限分为两类:
-
模型侧权限:一般是指外部模型提供的数据查询与保存权限。比如财务模型权限、筛选器的继承维度权限
-
展现层权限定义:除模型侧的数据权限外,在展现层额外配置的权限。比如sheet权限、按钮权限、筛选器自定义权限。
展现层权限与模型侧数据权限的对比:
-
模型侧权限在模型上进行配置,所有通过模型获取数据的,兼受此权限控制,无需在表格上每张表配置。
-
展现层权限需要每张表重复配置,因为Sheet、按钮、筛选器这些内部元素在每个表格中都是相互独立的。
-
模型侧和Sheet权限都能达到锁数的目的(通过状态控制数据填写或只读)
-
模型侧权限优势:可以按照维度配复杂组合,控制到每个数据块的权限,同一张表按照维度组合分别应用不同的权限。
-
模型侧权限劣势:配置较为复杂,理解难度高。
-
展现层权限优势:若用于权限控制的维度组合过于复杂,比如到了科目级,可直接以表为单位进行权限控制。逻辑简单,理解成本低。
-
展现层权限劣势:一个sheet只能使用统一的权限控制方案,无法按照不同数据块拆分权限。权限控制颗粒度粗。用户通过建不同的表,可绕过展现层权限。
-
-
注:数据源权限比较特殊,他是在表格侧配置的权限,但是一个数据源对应多个浮动行表时可重复利用权限方案,是在数据查询中提供的权限,具有模型侧权限的特征。
筛选器和模型都可以配权限,会不会冲突
不会冲突,筛选器是单独内部元素,权限不遵循模型,所以,才需要额外配置权限。
当使用时,筛选器启用权限控制后,用户有权限的成员向动态表区域去传递,也就是说,可以模型不配权限,只通过筛选器去控制用户的可见数据范围。
筛选器权限相当于前端控权,比如某一张表筛选器漏配权限,容易造成权限泄露,从严谨的角度来说,财务模型实现控权相当于后端控权,前端+后端双重保证更不容易出问题。
筛选器权限和模型权限不一样也没关系,最多是,筛选器能选到,但是模型查出来都是noaccess。
由于每张表的筛选器都要关联权限,略繁琐,建议使用继承维度权限功能,或者专门存一张电子表格元素,把常用的筛选器都配置好,接下来就复制元素建新的表格。
财务模型权限、数据源权限和sheet锁定在权限控制上有什么区别
当我们编制一张动态表或浮动行表时,如果需要实现用户权限控制,可以选择财务模型权限、数据源权限和sheet权限,那么这几种权限改怎么选择呢?
首先看三种权限在实现上的区别:
1️⃣ 财务模型权限:
维度成员可见权限:
通过权限方案,获取用户对维度成员的可见权限。
数据状态:
通过流程控制字段+审批单元字段,按维度组合作为流程控制的最小单元。
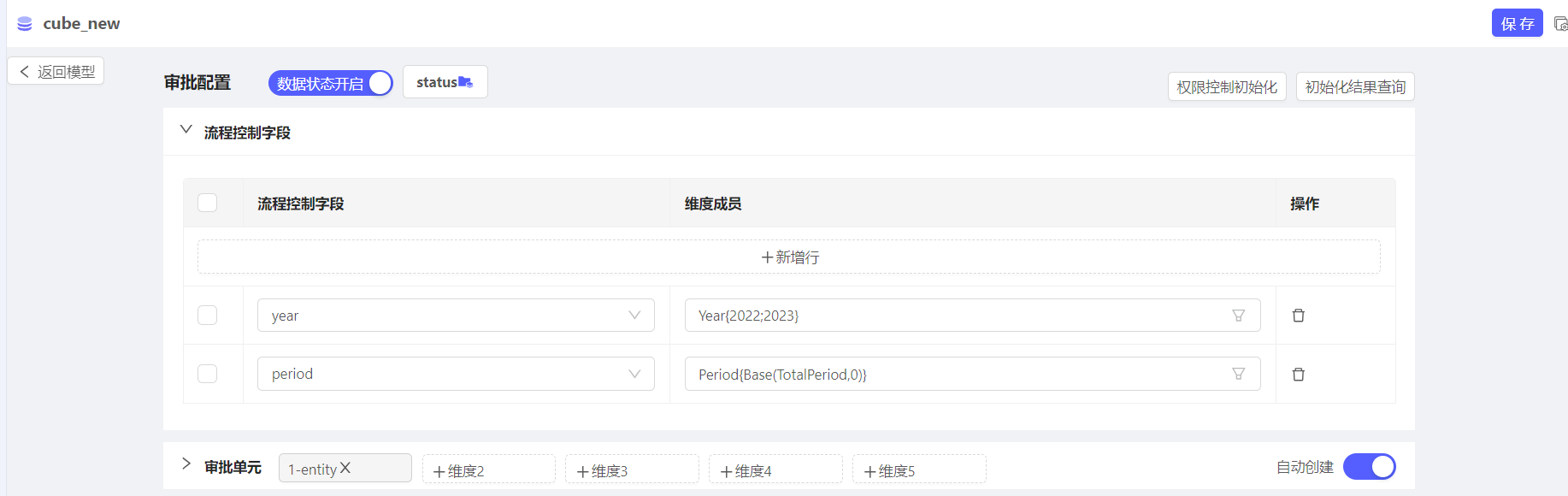
比如上例,最后形成的流程控制单元如下:
|
year |
period |
entity |
status |
|---|---|---|---|
|
2022 |
1 |
E1 |
1 |
|
… |
… |
… |
… |
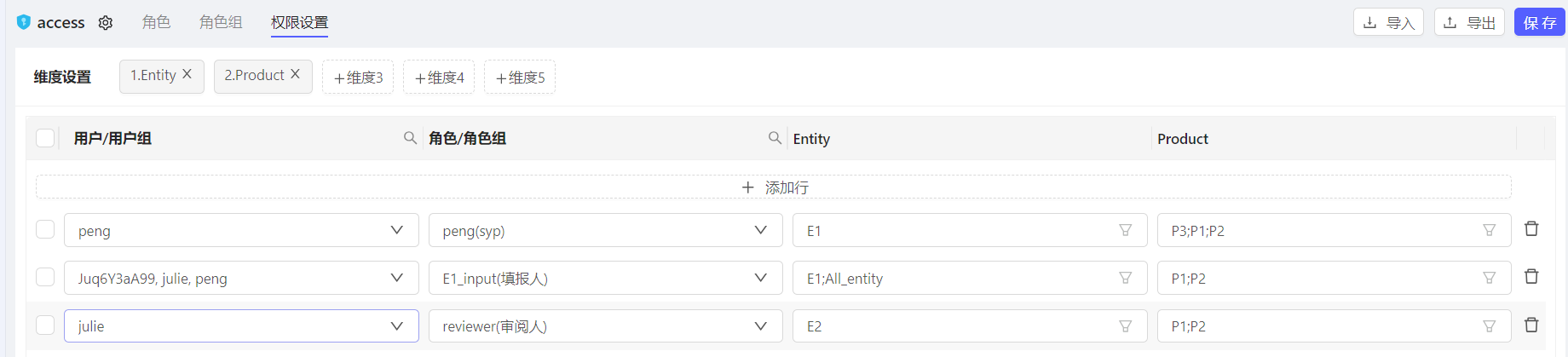
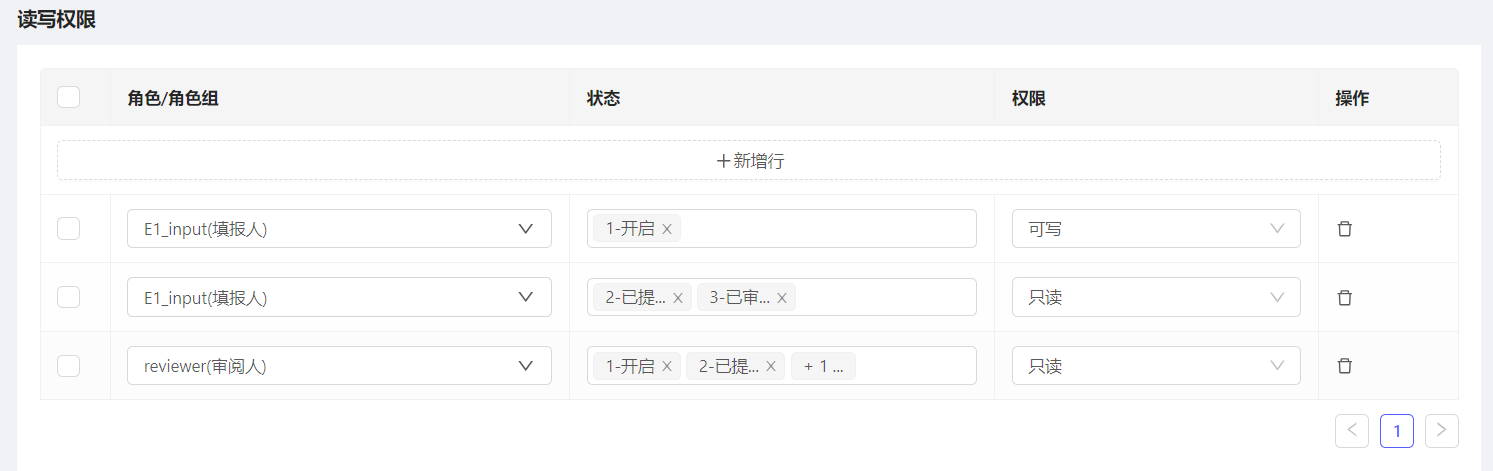
权限配置:
通过角色+状态,得出用户最终对某个维度组合的访问权限
计算过程举例:
|
用户 |
权限关联维度-Entity |
权限关联维度-Product |
根据左侧维度查询用户角色 |
year |
period |
根据流程控制维度查询状态 |
权限 |
|---|---|---|---|---|---|---|---|
|
用户1 |
E1 |
P1 |
填报者 |
2022 |
1 |
1 |
可写 |
|
用户1 |
E2 |
P1 |
审阅者 |
2022 |
1 |
1 |
只读 |
|
用户1 |
E3 |
P1 |
无 |
2022 |
1 |
1 |
Noaccess |
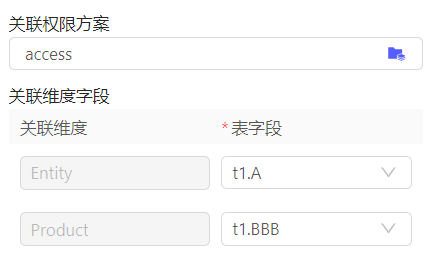
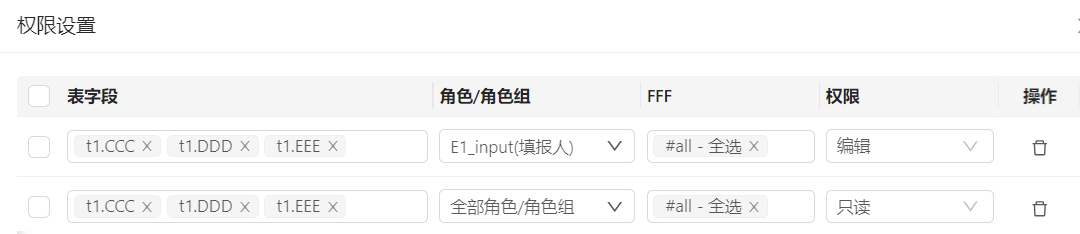
2️⃣ 浮动行表数据源权限:
维度成员可见权限:
通过权限方案,获取用户对维度成员的可见权限(查询浮动行数据时,具有过滤行作用)。
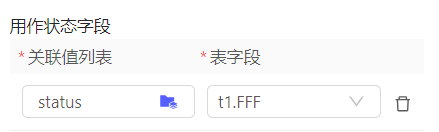
数据状态:
指定浮动行列中,用于状态的字段(浮动行表的数据状态不是通过流程控制单元额外查询,而是在行上直接提供)。
权限配置:
通过角色+状态,得出用户最终对某些字段的访问权限
计算过程举例:
|
用户 |
权限关联维度-Entity |
权限关联维度-Product |
根据左侧维度查询用户角色 |
状态字段的值 |
权限(作用到某些字段) |
|---|---|---|---|---|---|
|
用户1 |
E1 |
P1 |
填报者 |
1 |
可写 |
|
用户1 |
E2 |
P1 |
审阅者 |
1 |
只读 |
|
用户1 |
E3 |
P1 |
无 |
1 |
直接过滤 |
3️⃣ Sheet锁定:
查询用户角色:
通过权限方案,获取用户在某个维度下的角色。

举例,当筛选器的值如下时,可根据entity+product成员,得到用户当前的角色
|
用户 |
year |
period |
entity |
product |
角色 |
|---|---|---|---|---|---|
|
用户1 |
2022 |
1 |
E1 |
P1 |
填报者 |
|
用户1 |
2022 |
1 |
E2 |
P1 |
审阅者 |
注:若不关联维度,返回用户在该权限方案中的所有角色。此时,当一个用户在不同的维度成员拥有不同的角色时,后续进行权限计算时,可能会造成混淆。
数据状态:
外接入一张流程状态表,通过筛选器传参,得出当前sheet所处状态。
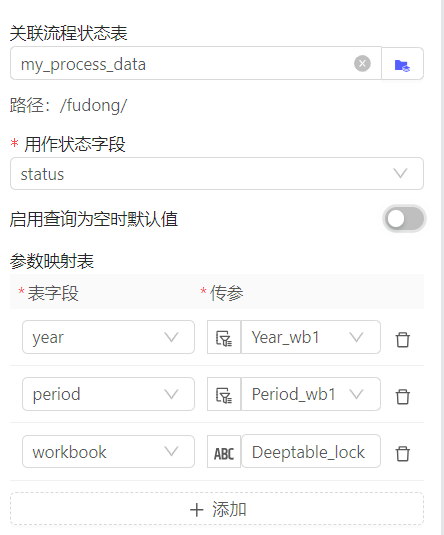
举例,根据year+period+entity筛选器成员+表名,得到当前sheet状态
|
用户 |
year |
period |
entity |
表名 |
product |
角色 |
状态 |
|---|---|---|---|---|---|---|---|
|
用户1 |
2022 |
1 |
E1 |
表1 |
P1 |
填报者 |
1 |
|
用户1 |
2022 |
1 |
E2 |
表1 |
P1 |
审阅者 |
1 |
权限配置:
通过角色+状态,得出用户最终对这张sheet的访问权限

计算过程举例:
|
用户 |
year |
period |
entity |
product |
表名 |
角色 |
状态 |
权限 |
|---|---|---|---|---|---|---|---|---|
|
用户1 |
2022 |
1 |
E1 |
P1 |
表1 |
填报者 |
1 |
可写 |
|
用户1 |
2022 |
1 |
E2 |
P1 |
表1 |
审阅者 |
1 |
锁定 |
注:sheet锁定命中则为只读,不命中则为可写。对同一个维度组合又有锁又有写,以锁优先。(财务模型权限和浮动行数据源权限是读写双向可配,以读优先)
综上,三种权限控制方式基本逻辑类似,但是在权限控制颗粒度上有明显的区别
-
财务模型权限:以维度组合为颗粒度进行权限控制,流程状态表由财务模型自动生成
-
浮动行表数据源权限:以行为颗粒度进行权限控制,流程状态由每行的状态字段上自带
-
sheet权限:以sheet为颗粒度进行权限控制,入参依赖筛选器,流程状态表由用户自建
财务模型comment的权限控制规则
comment数据分为不同的使用场景,权限控制规则不同,具体见下表。
|
场景 |
权限规则 |
|---|---|
|
动态表用虚拟度量维作为行列 |
把comment当维度用,因此,comment度量有完整的权限控制,由财务模型接口提供a值(权限值),8,5值(Noaccess)会一直同步到备注单元格,7值(只读)根据模型权限是否勾选备注权限决定是否同步到单元格 |
|
动态表右键插入批注 |
把comment当批注用,仅对noaccess情况进行权限控制(右键隐藏插入批注) |
|
DF函数右键插入批注 |
把comment当批注用,仅对noaccess情况进行权限控制(右键隐藏插入批注) |
|
DF函数显示批注到单元格 |
把comment当批注用,当a值=noaccess时,显示noaccess并保护,当表格侧配置第三个参数为r,进行保护,除此之外,都可写入 |
注:科目设置数据类型为文本,也可以达到填入文本的效果,并且严格受到财务模型权限控制,若仅是填列文本数据场景,建议修改科目主数据。
某张Sheet,想要所有人(除应用管理员外)都不可见/只读
可使用Sheet权限实现此功能
在Sheet上配置权限,对所有用户、所有角色隐藏。
UX
表格2.0可以装到页面2.0中吗?
不可以,表格2.0只支持装在UX中,UX是比页面更丰富功能的新组件
表格2.0可以和UX联动吗?
目前支持
1、别的控件联动查询表格
2、表格监控其他控件值变化,主动联动刷新表格
3、设置表格内筛选器隐藏或禁用
4、表格通过单元格点击事件配置后续动作:比如修改其他控件的值
5、跳转到新窗口打开表格
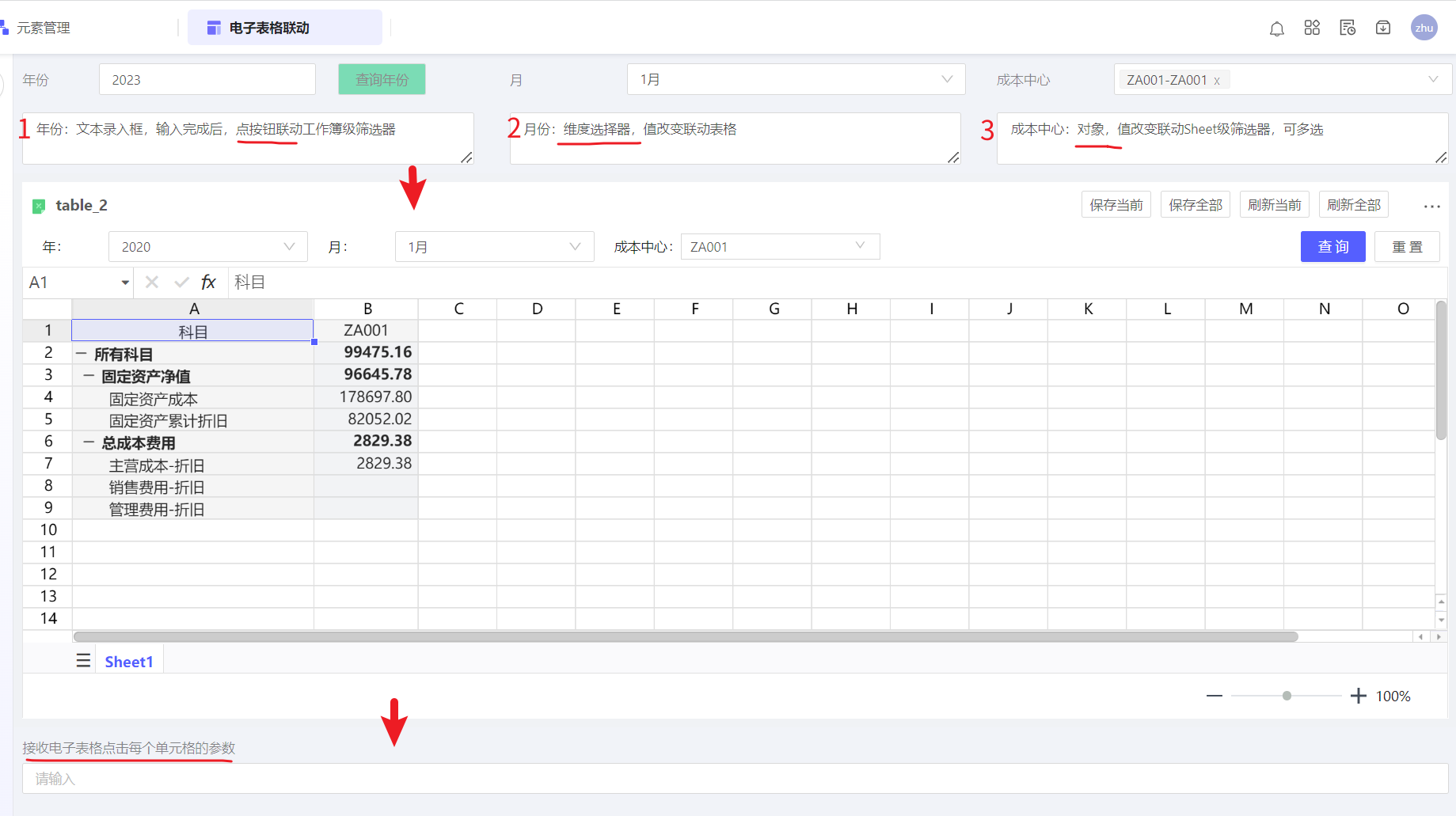
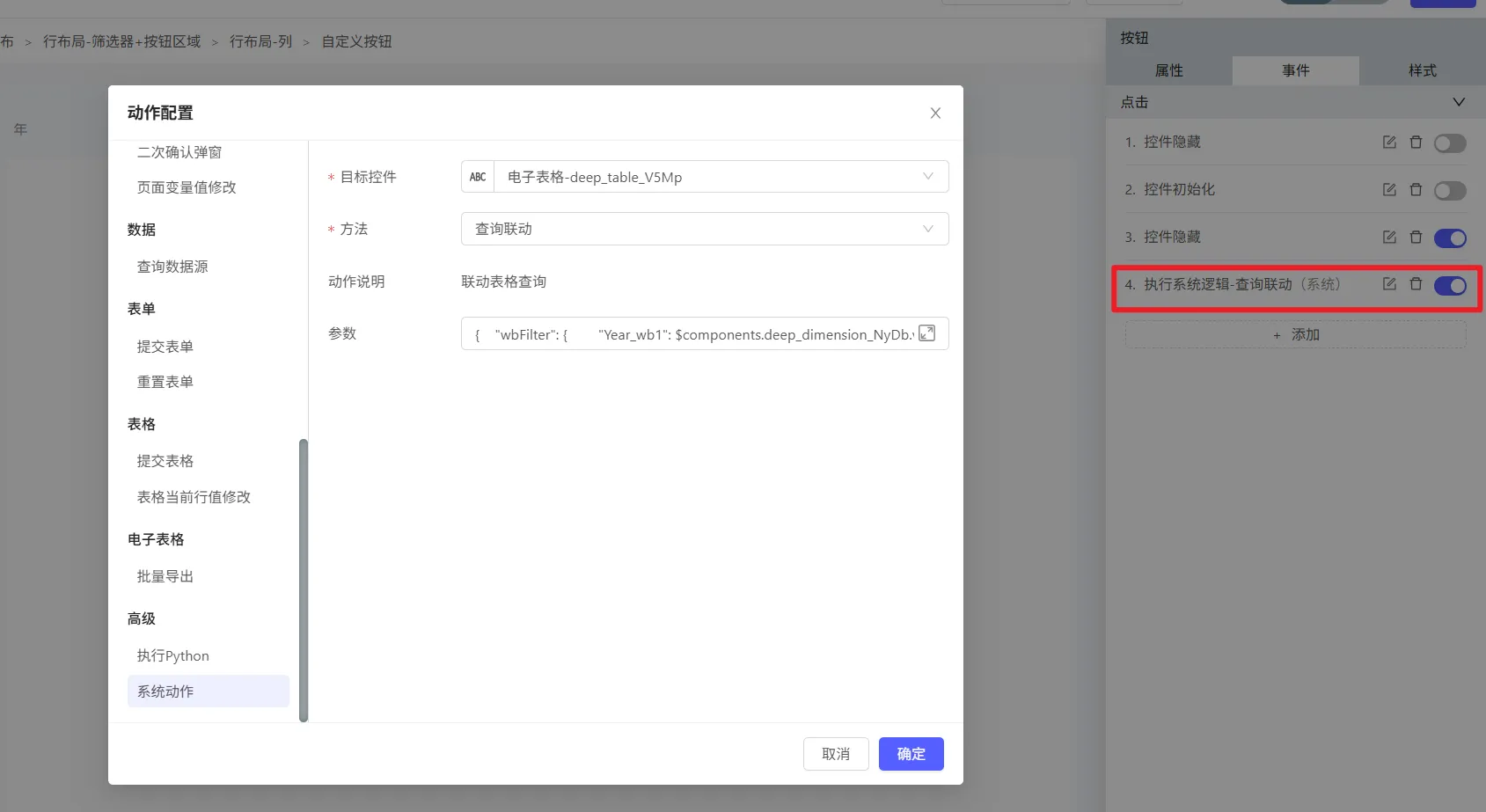
{
// WB级筛选器
"wbFilter": {
"Period_wb1": $components.deep_dimension_jt6x.value
}
// sheet级筛选器
"sheetFilter": {
// sheet名称
"Sheet1": {
"Cost_Center_st1": $components.object_select_SNjv.value
}
}
}
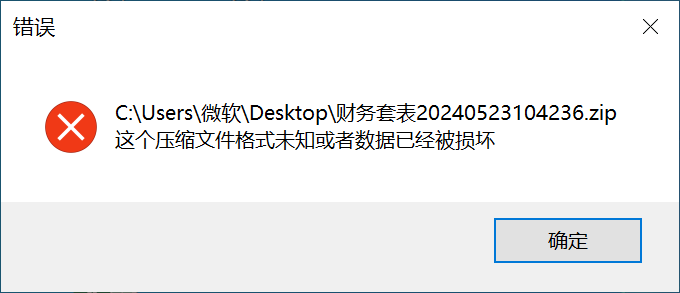
UX-电子表格批量下载后,ZIP文件不能打开
下载的ZIP打开失败,F12看download接口报错文件过多
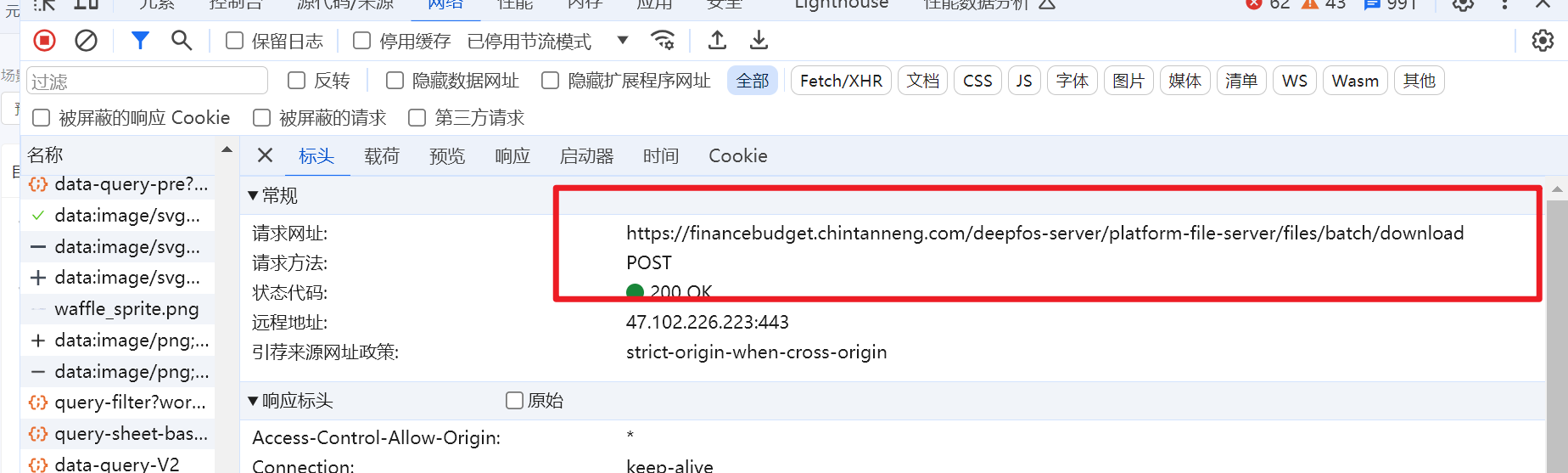
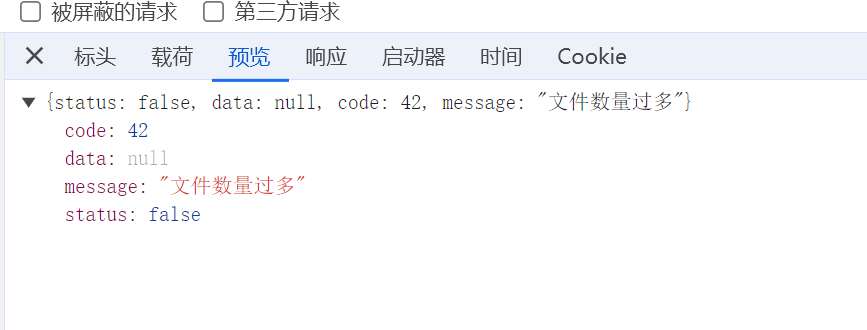
若采用zip方式,平台侧打包下载接口( /deepfos-server/platform-file-server/files/batch/download )默认限制10个文件,超出这个文件数量则会ZIP失败(一个电子表格元素是一个excel文件),可根据项目服务器配置情况(比如内存大小),自行进行调整参数和测试
套表只支持一次导出一家公司的多张报表,怎么实现多家公司多个报表随意组合
批量导出功能接受Json格式作为入参,并by元素前端模拟开表后导出。
[
{
"elementName": "", //元素编码
"folderId": "",
"fileName": "动态表示例", // 指定下载的文件名(仅适用于ZIP或单文件导出方式)
"sheetSuffix": "_sheet后缀", // 指定Sheet名称后缀(适用于合并成一个excel的导出方式),暂未上线
"filterMap": {
"wbFilter":{
"筛选器_wb1":"A01", //筛选器_wb1为筛选器编码
},
"sheetFilter":{
"sheet1":{
"筛选器_st1":"A0102"
}
}
}
}
]
因此,通过UX自带的方法,可以按照多个维度对Json参数进行加工,并按需导出报表
示例1:通过table选择报表,通过Entity筛选器选择公司,为每家公司导出所选报表,以ZIP方式导出
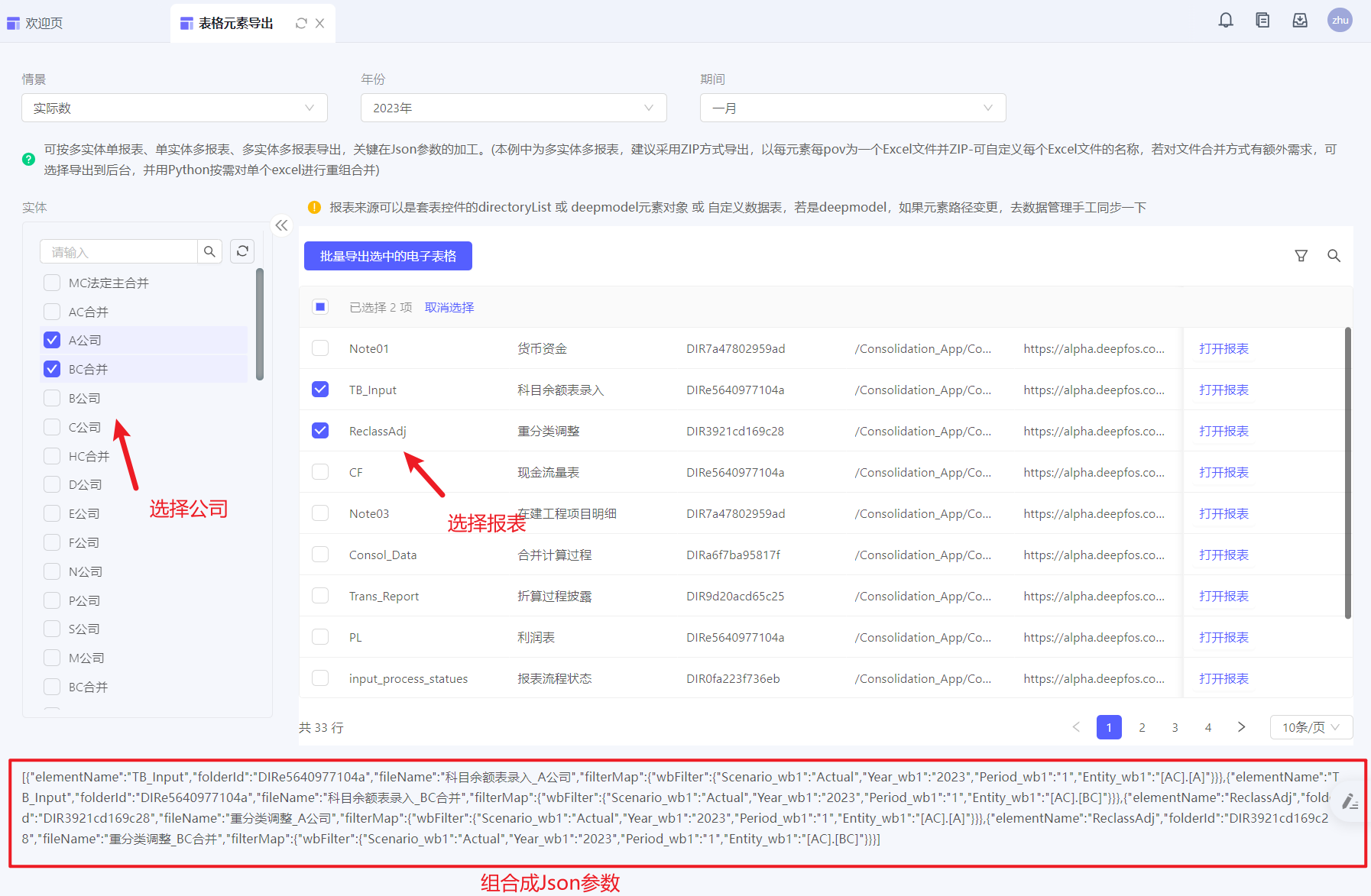
点击按钮时,执行批量导出动作,参数如下(循环获取selectedRows 和 entity维度值,拼Json参数)
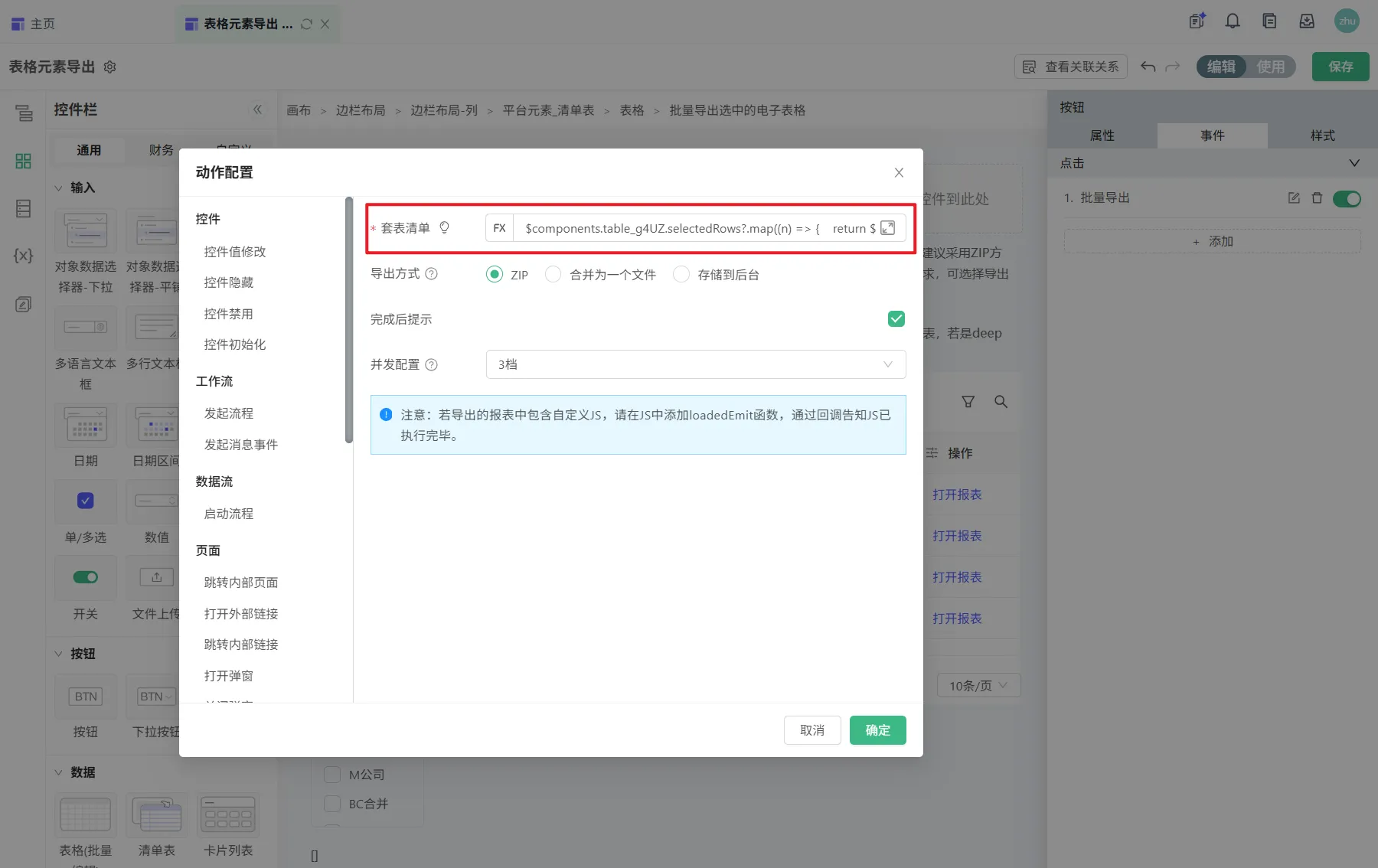
$components.report_table.selectedRows?.map((n) => {
return $components.Entity.info?.map((e) => {
return {
elementName: n.element_code,
folderId: n.folder_id,
fileName: n.element_name + "_" + e.description,
filterMap: {
wbFilter: {
"Scenario_wb1": $components.Scenario.value,
"Year_wb1": $components.Year.value,
"Period_wb1": $components.Period.value,
"Entity_wb1": e.expectedName
}
}
}
})
}).flat()
示例2:
有value的报表导出公司报表value组合,没value的报表导出公司*报表组合。合并成一个文件。(注,此处以套表为例,重点体现不同报表由于自身筛选器配置需导出不同份数,若报表也要可选,可使用元素清单)
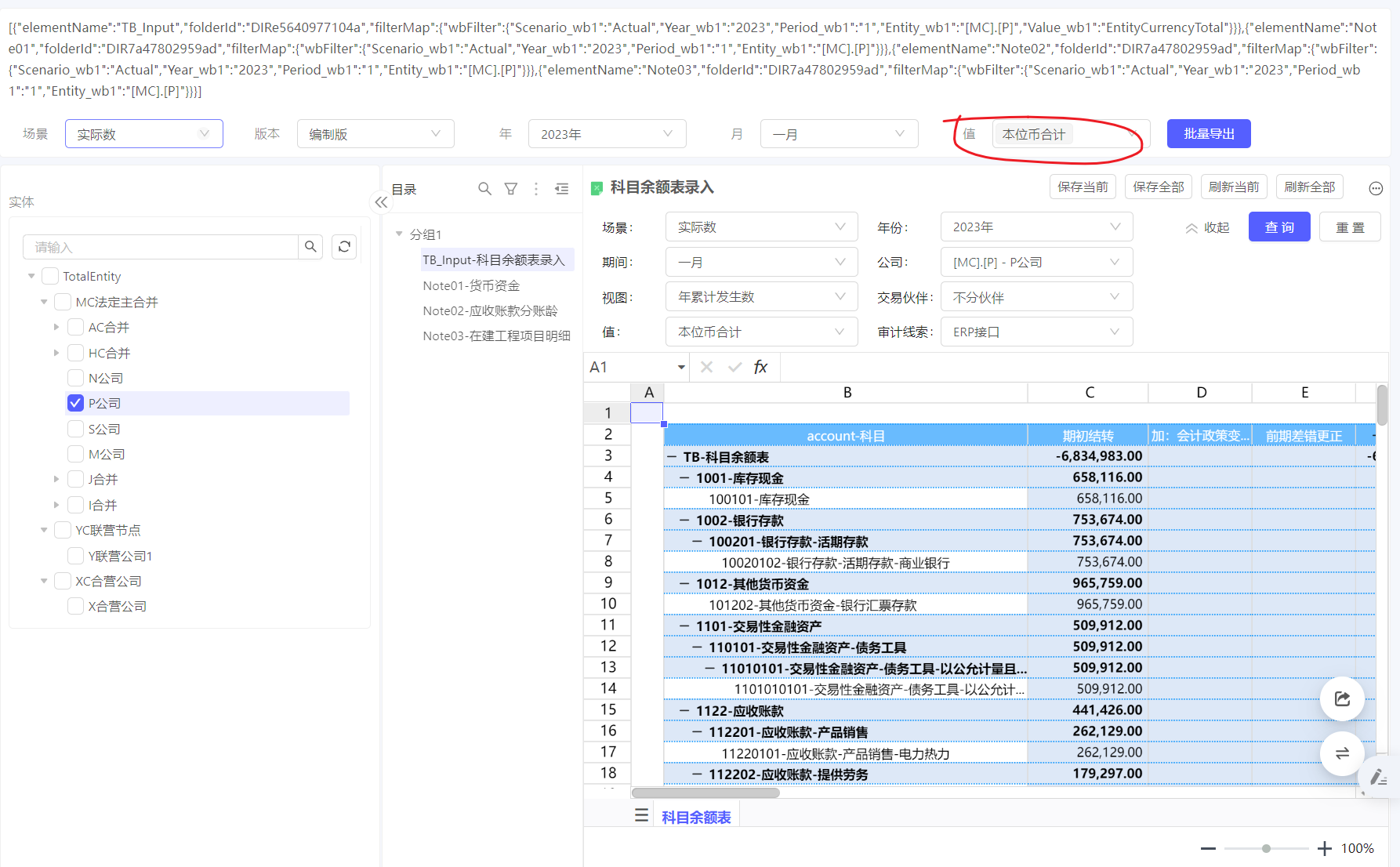
$components.package.directoryList.map((n) => {
if (n.linkageParam.wbFilter.Value_wb1) {
return $components.entity.info?.map((e) => {
return $components.value.value.map((v) => {
return {
elementName: n.element.elementName,
folderId: n.element.folderId,
sheetSuffix: "_" + e.name + "_" + v,
filterMap: {
wbFilter: {
"Scenario_wb1": $components.scenario.value,
"Year_wb1": $components.year.value,
"Period_wb1": $components.period.value,
"Entity_wb1": e.expectedName,
"Value_wb1": v,
}
}
}
})
}).flat()
} else {
return $components.entity.info?.map((e) => {
return {
elementName: n.element.elementName,
folderId: n.element.folderId,
sheetSuffix: "_" + e.name,
filterMap: {
wbFilter: {
"Scenario_wb1": $components.scenario.value,
"Year_wb1": $components.year.value,
"Period_wb1": $components.period.value,
"Entity_wb1": e.expectedName,
}
}
}
})
}
}).flat()
在UX中,如何创建一个电子表格清单(以模型3.0为例)
预期效果:
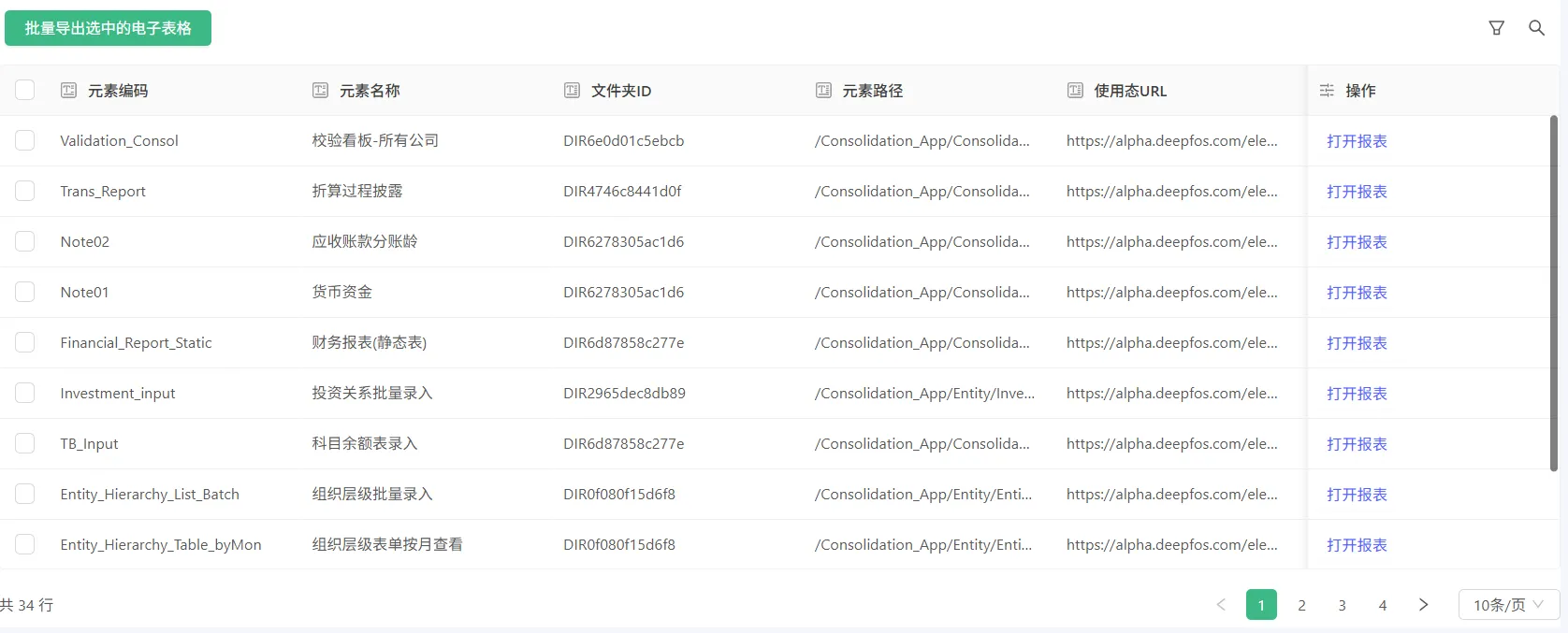
1、先用模型3.0创建一个元素对象
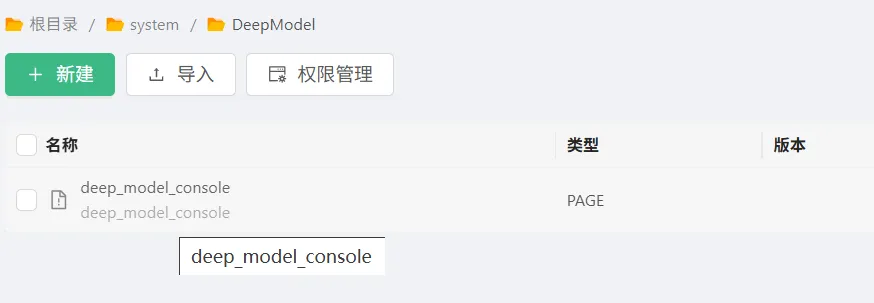

2、在UX中创建数据源,选择元素对象,并配置过滤条件为电子表格2.0类型
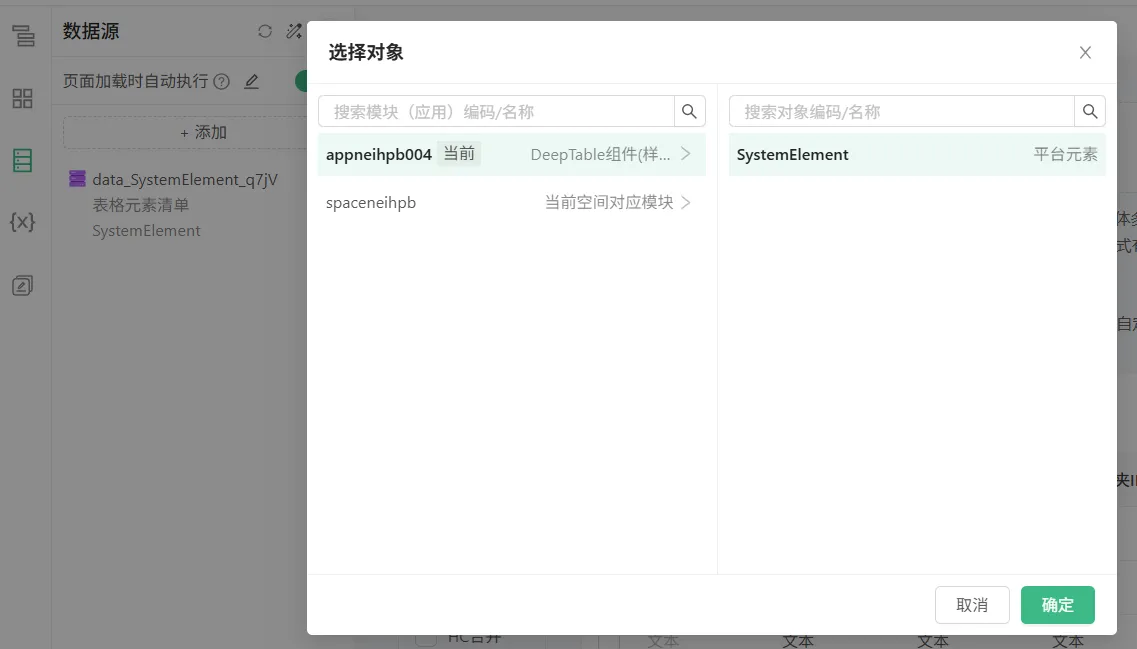
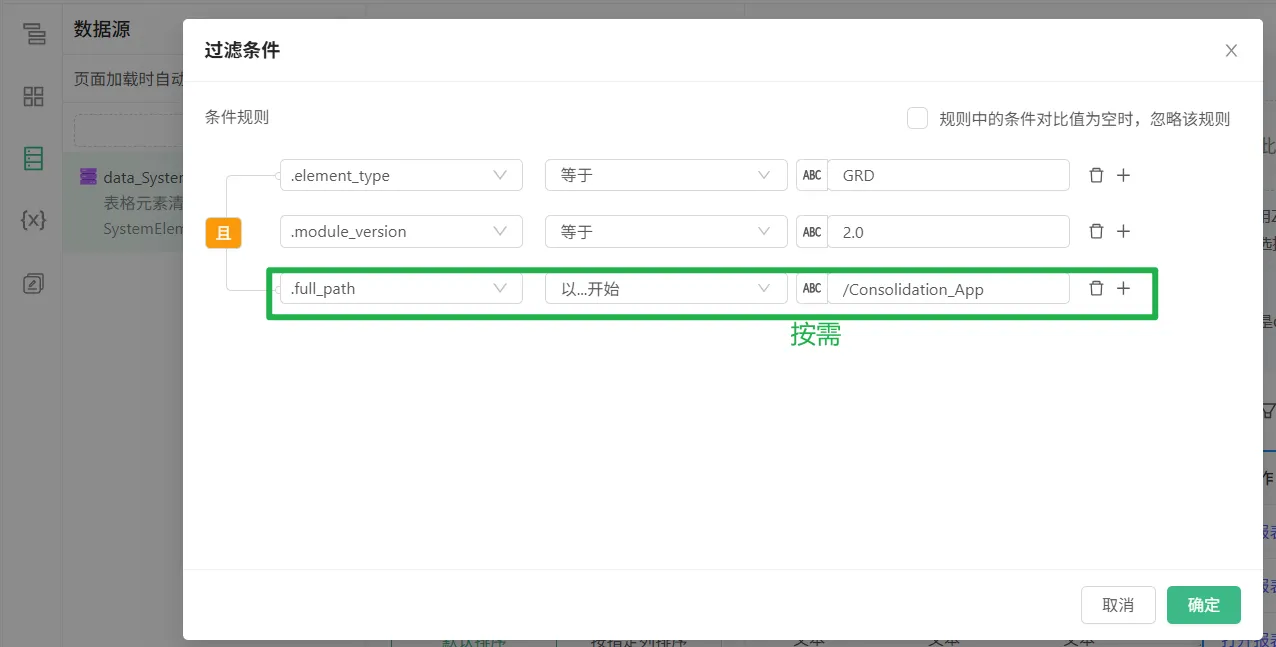
3、在UX中创建一个清单表,关联上一步的数据源
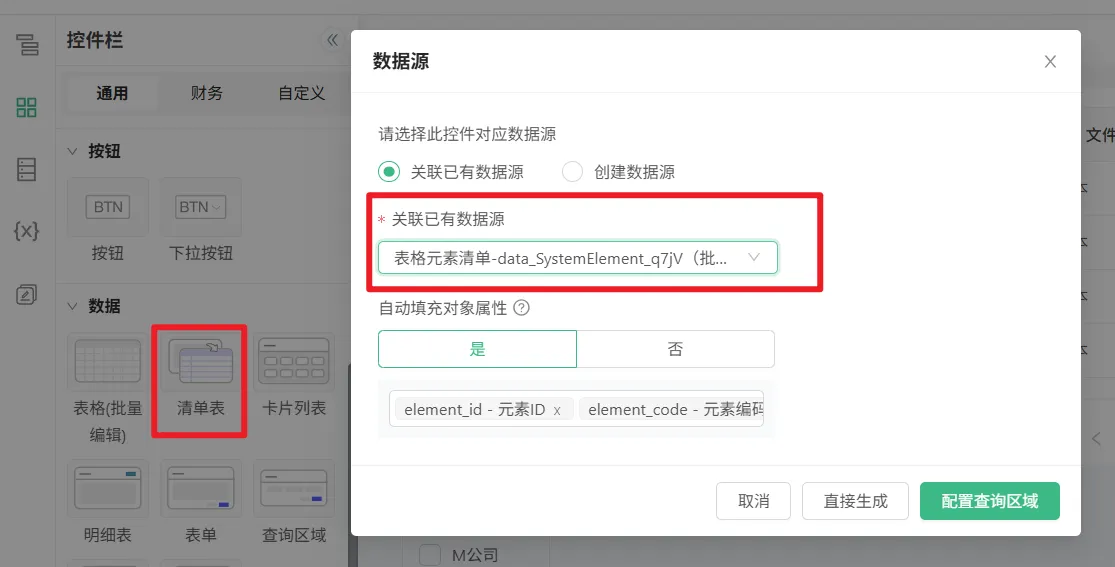
4、按需配置清单表的展示列及按钮
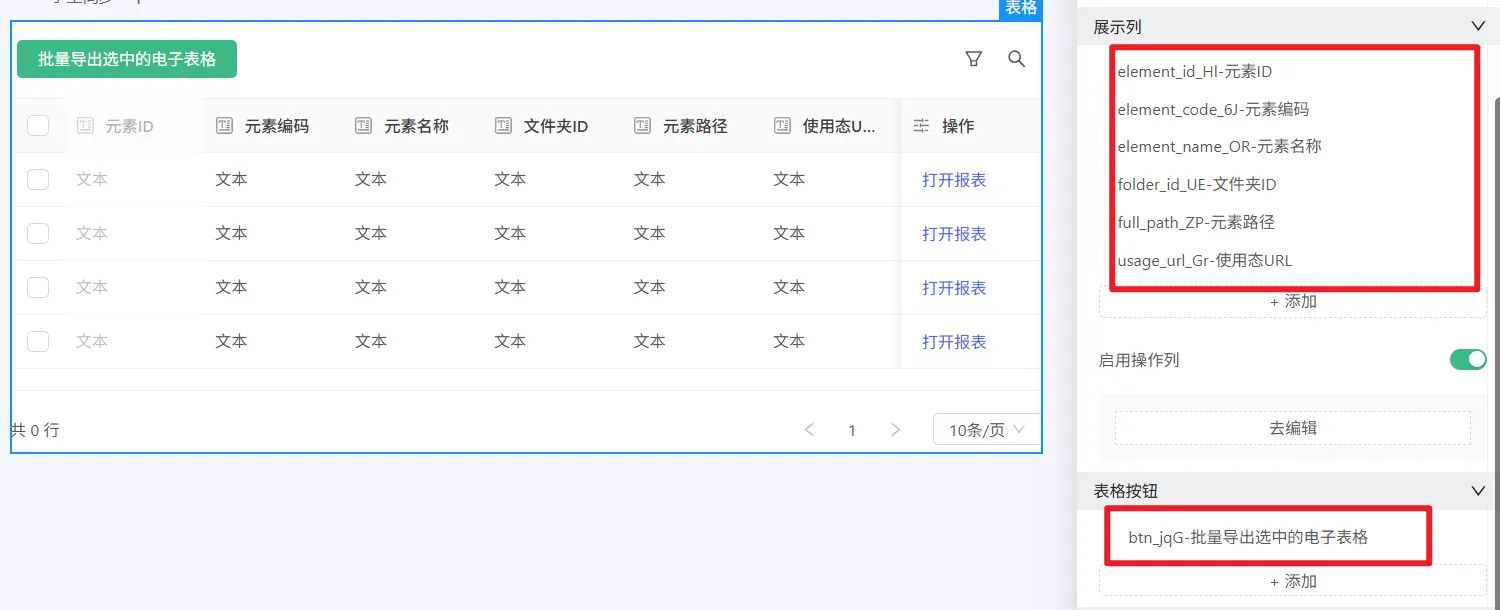
5、若需跳转打开每行的对应元素,可启用操作列,并配置自定义行按钮
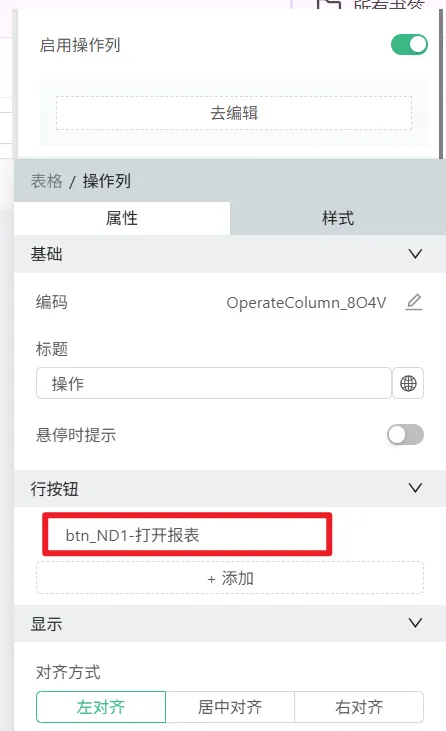
6、行按钮中配点击事件,执行跳转内部链接动作
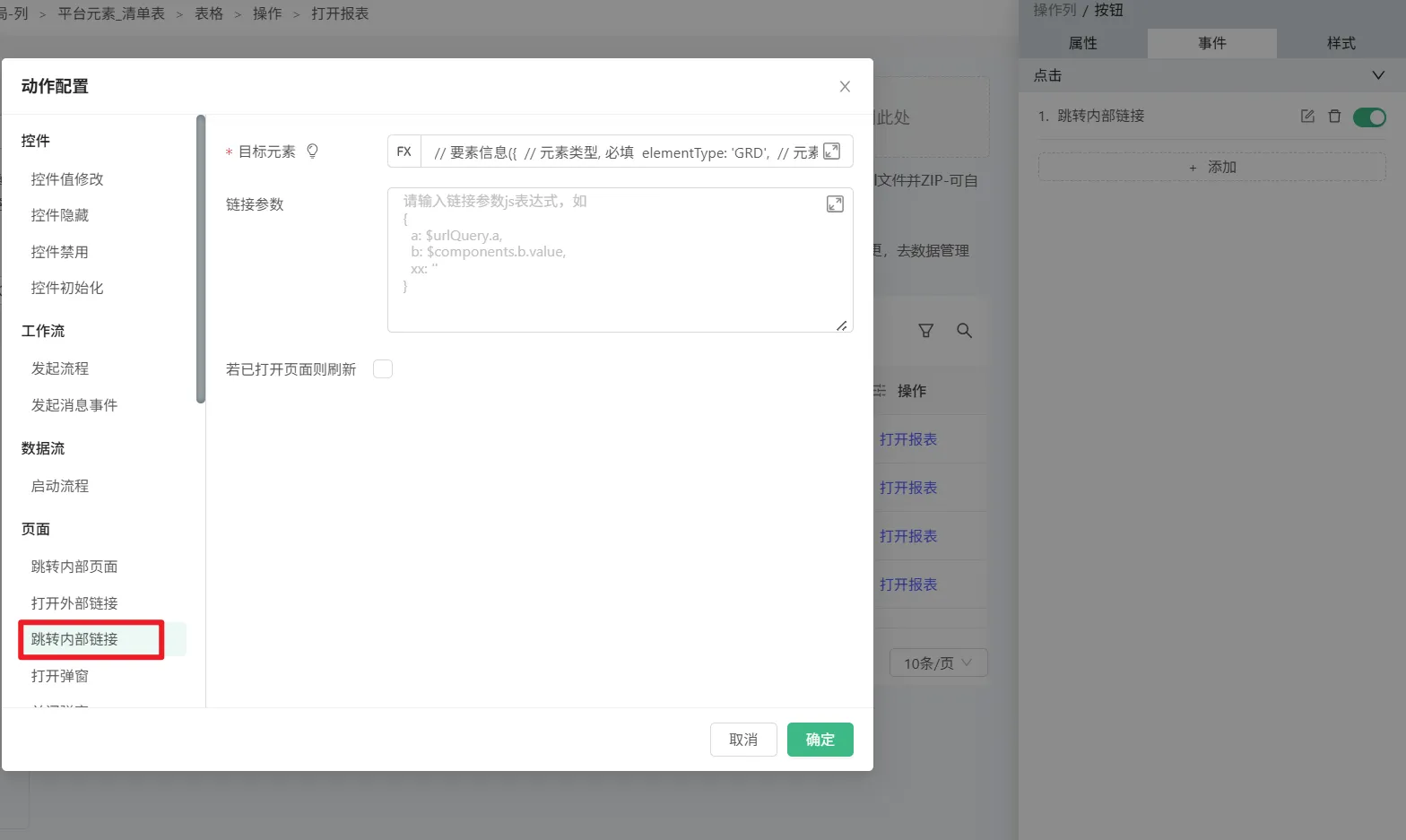
参数如下:
// 要素信息
({
// 元素类型, 必填
elementType: 'GRD',
// 元素名称, 必填
elementName: $context.event.data.element_code,
// 所在文件夹 Id, 必填
folderId: $context.event.data.folder_id,
// 模块版本, 必填
moduleVersion: '2.0',
// 模块 Id,某些项目里的接口可能需要,可不传
moduleId: 'GRD2_0',
// 元素所在的 appId,第三方应用需要,可不传
//appId: '',
// PAGE 元素的打开路径, 默认为'/',否则需要传
openPath: $context.event.data.full_path,
// 显示类型 'USAGE' | 'EDIT' | 'ADD'
displayType: 'USAGE'
})
ux中如何通过【按钮】触发电子表格查询
要求:所有筛选器都选择完成后,点击查询按钮,才开始查询表格。UX一打开时不用查询表。
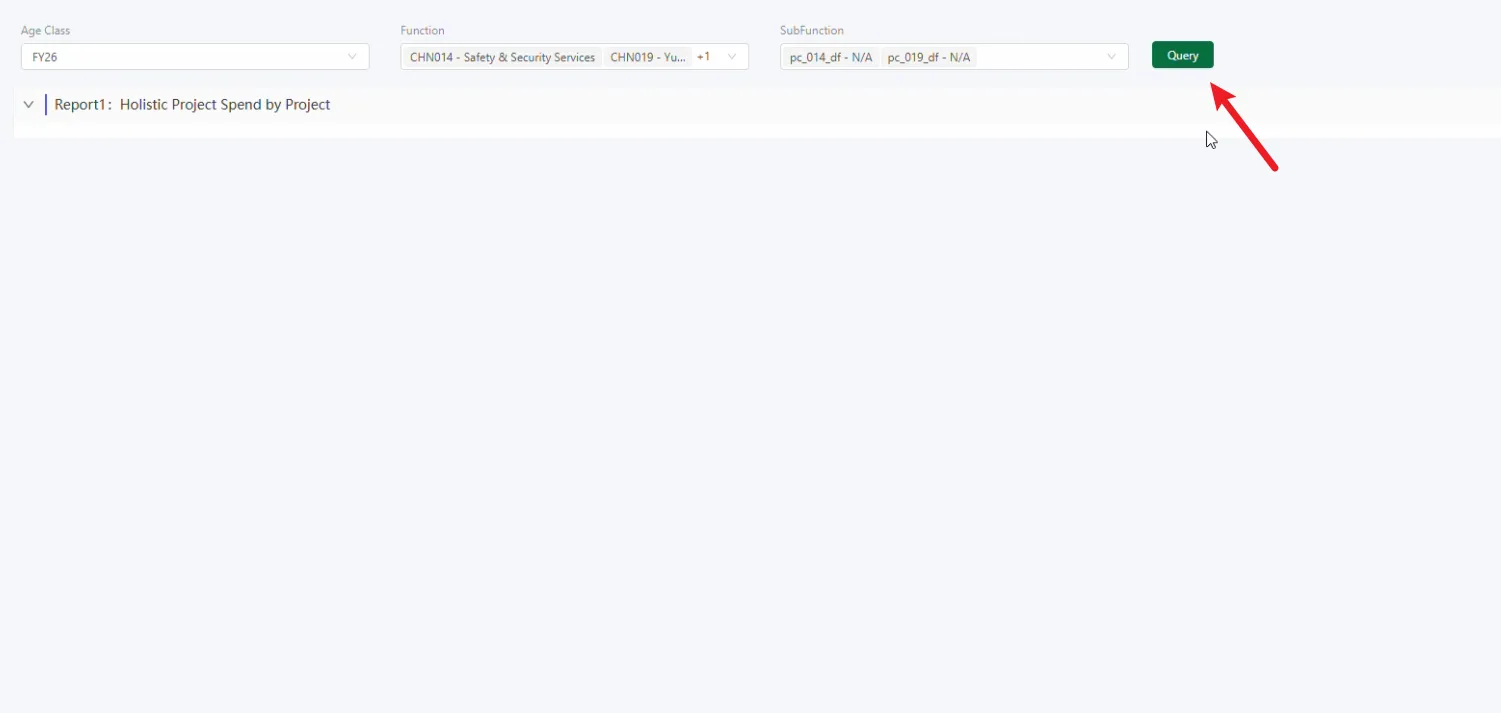
1、需要这些控件布局:
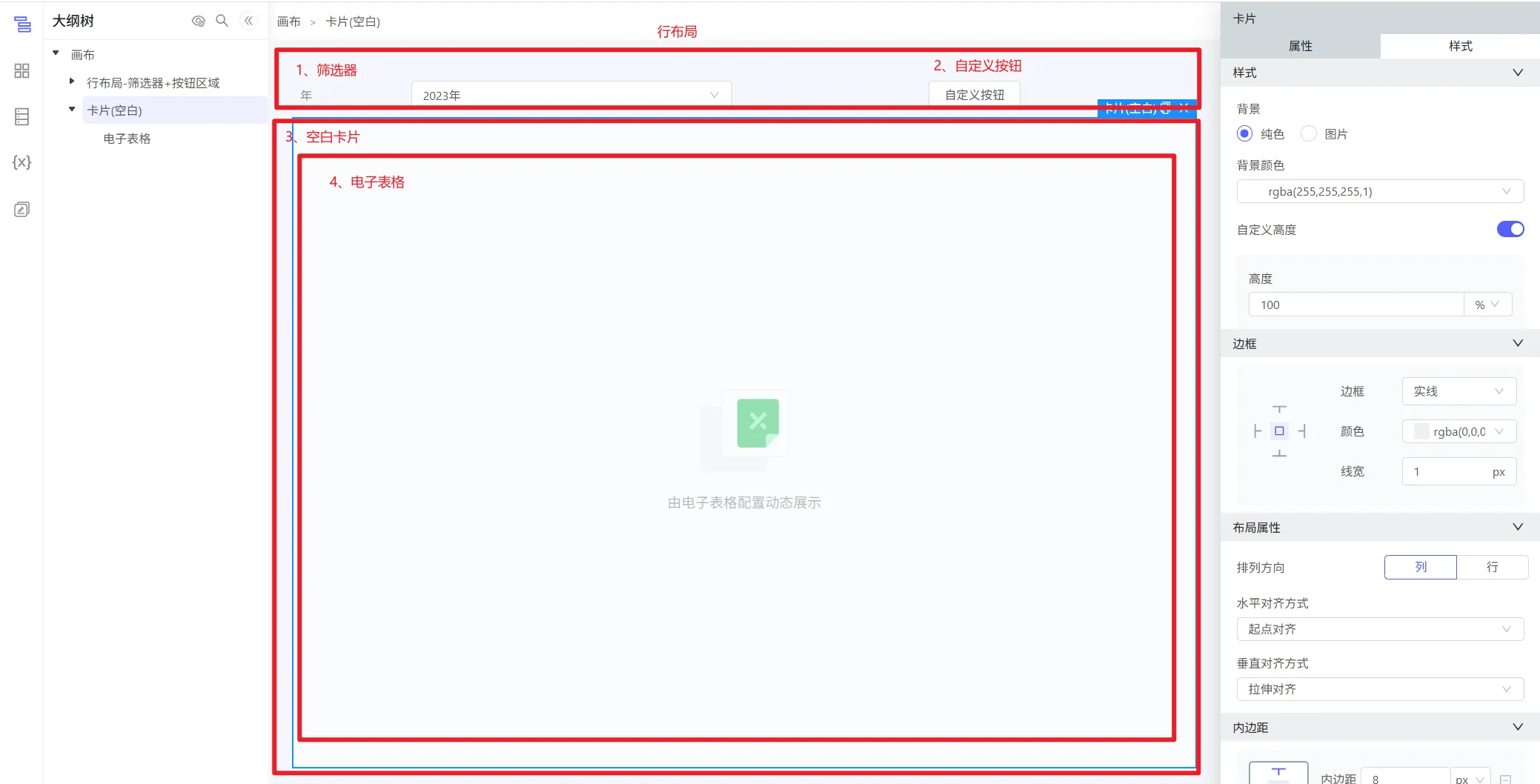
2、对空白卡片设置隐藏
3、对电子表格配置开表联动参数,并仅勾选加载时执行
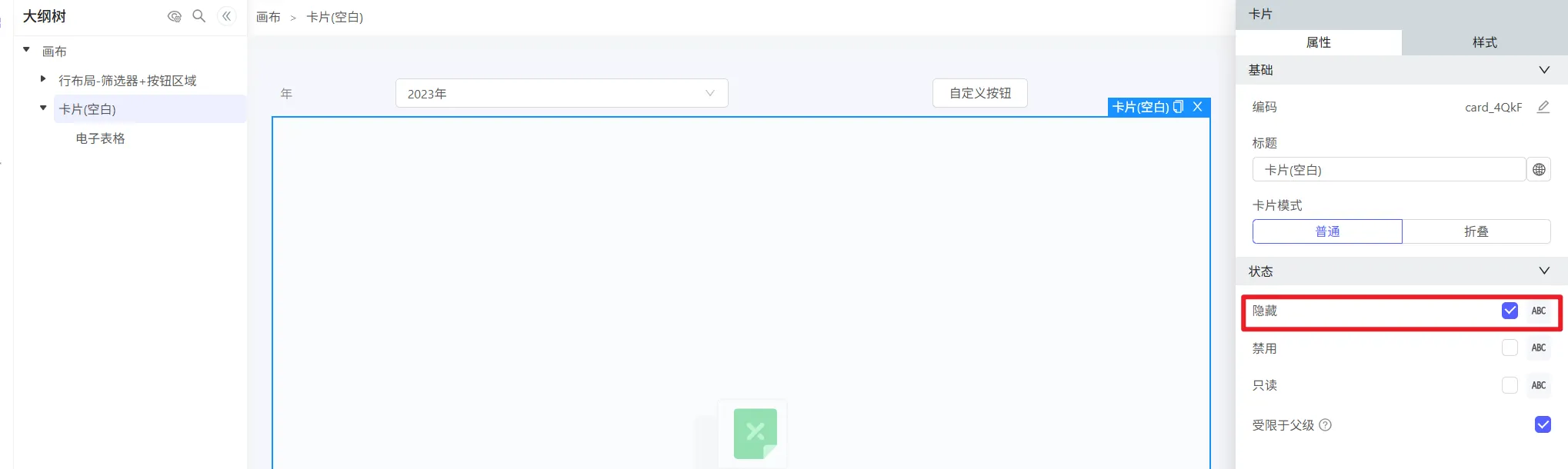
4、对自定义按钮添加两个动作
(1)点击按钮时取消隐藏:第一次点击时,电子表格首次加载,并使用第三步配置的联动参数进行初始化。第二次点击时重复取消隐藏,相当于无作用。
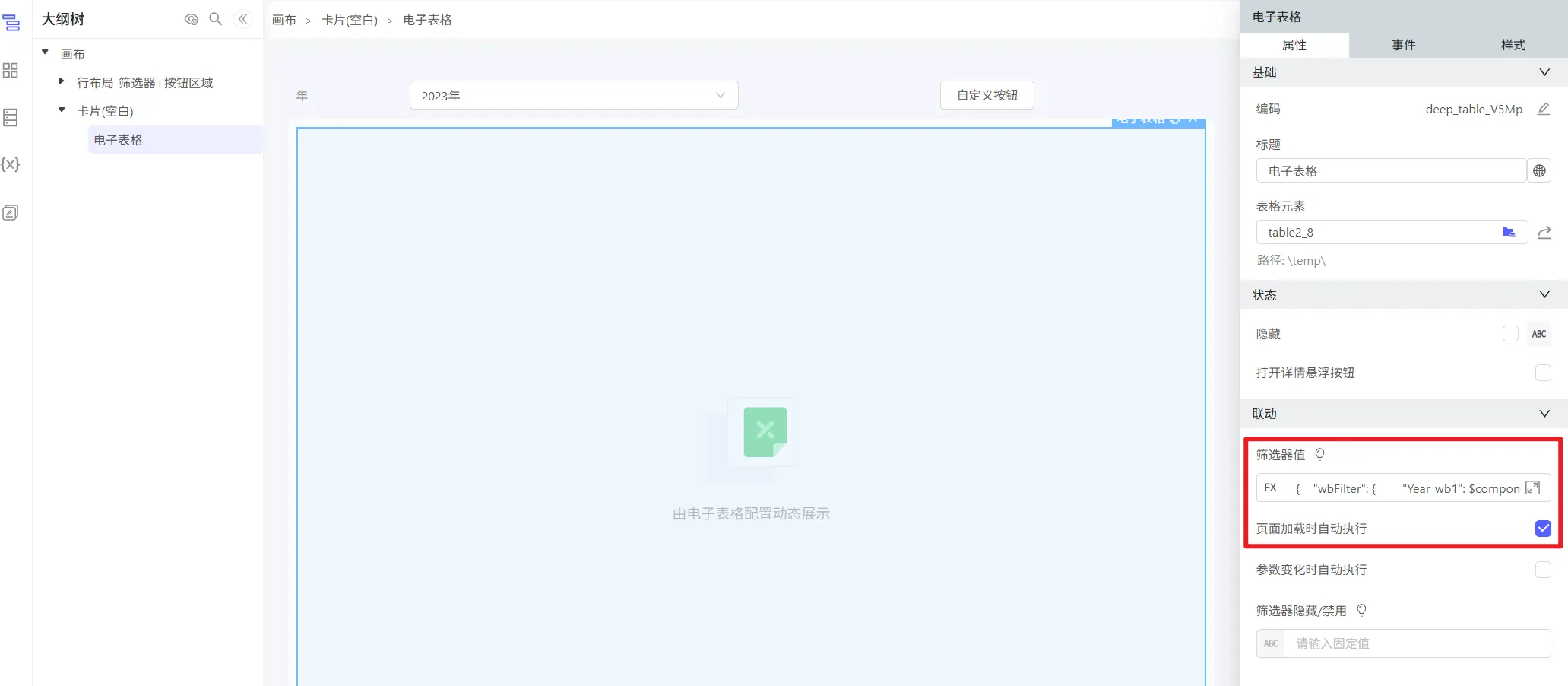
(2)点击按钮时,进行电子表格查询:该动作会在电子表格初始化时忽略,所以只有再次点击按钮时,才会执行,也就是按钮二次点击时,按当时的筛选器条件查询表格。
财务模型
财务模型view逻辑
期间汇总的几种组合:
-
用通用维类型,不开启view逻辑:通用维汇总逻辑(科目上开启了父节点允许录入不汇总,其他自动汇总)
-
用期间维类型,不开启view逻辑:不会自动汇总,全靠脚本计算
-
用期间维类型,开启老view或新view:notype科目类型不自动计算,其他科目类型都自动汇总
老view逻辑:
财务模型的读写逻辑 — 概述
新view逻辑:
3.3Period+Movement+View逻辑
执行Python计算之后,数据审计有数据,但是表格上没数据
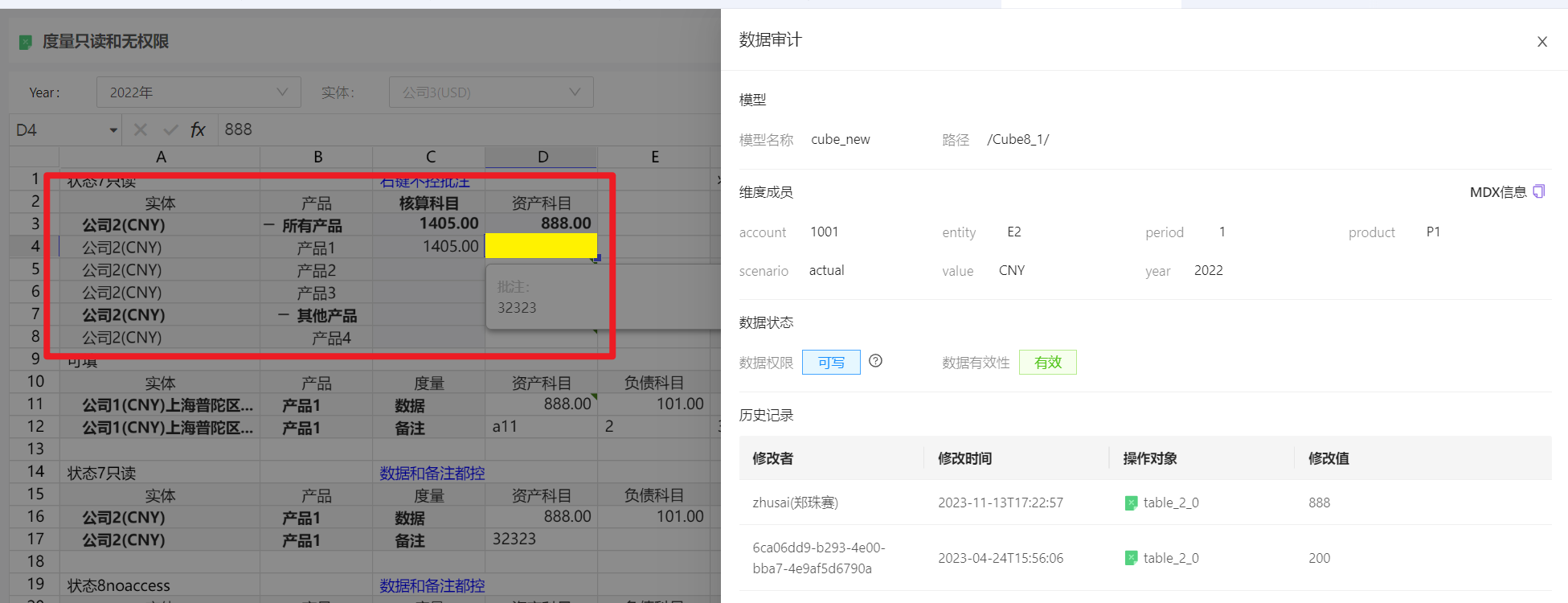
动态表上的数据取自财务模型底表(默认为Maintable_***),数据审计来自于模型log表(默认为财务模型名称+log)。执行Python计算的时候,可能因为各种原因,数据已经生成到log表,没有生成到Maintable表,或者相反。
遇到以上问题,先确认是否Maintable确实没数,再查找Python代码是否有问题,确认Python无误,可寻求模型侧解决。
查找Maintable特定维度组合数据的方法:
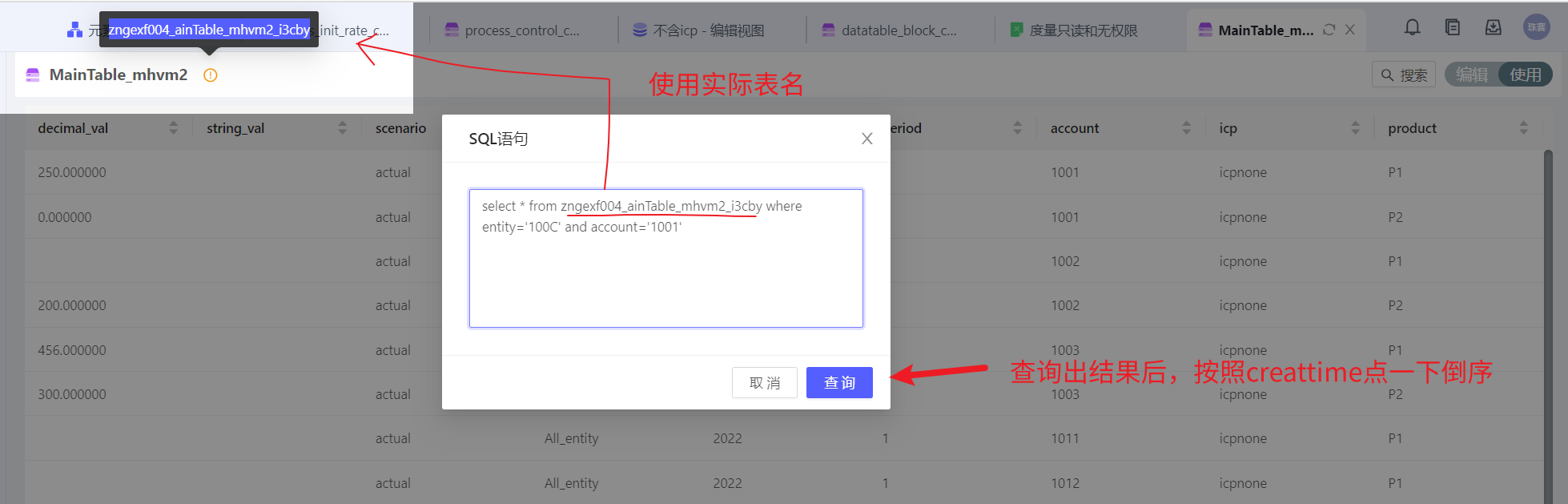
新增公司没有权限
模型权限初始化之后
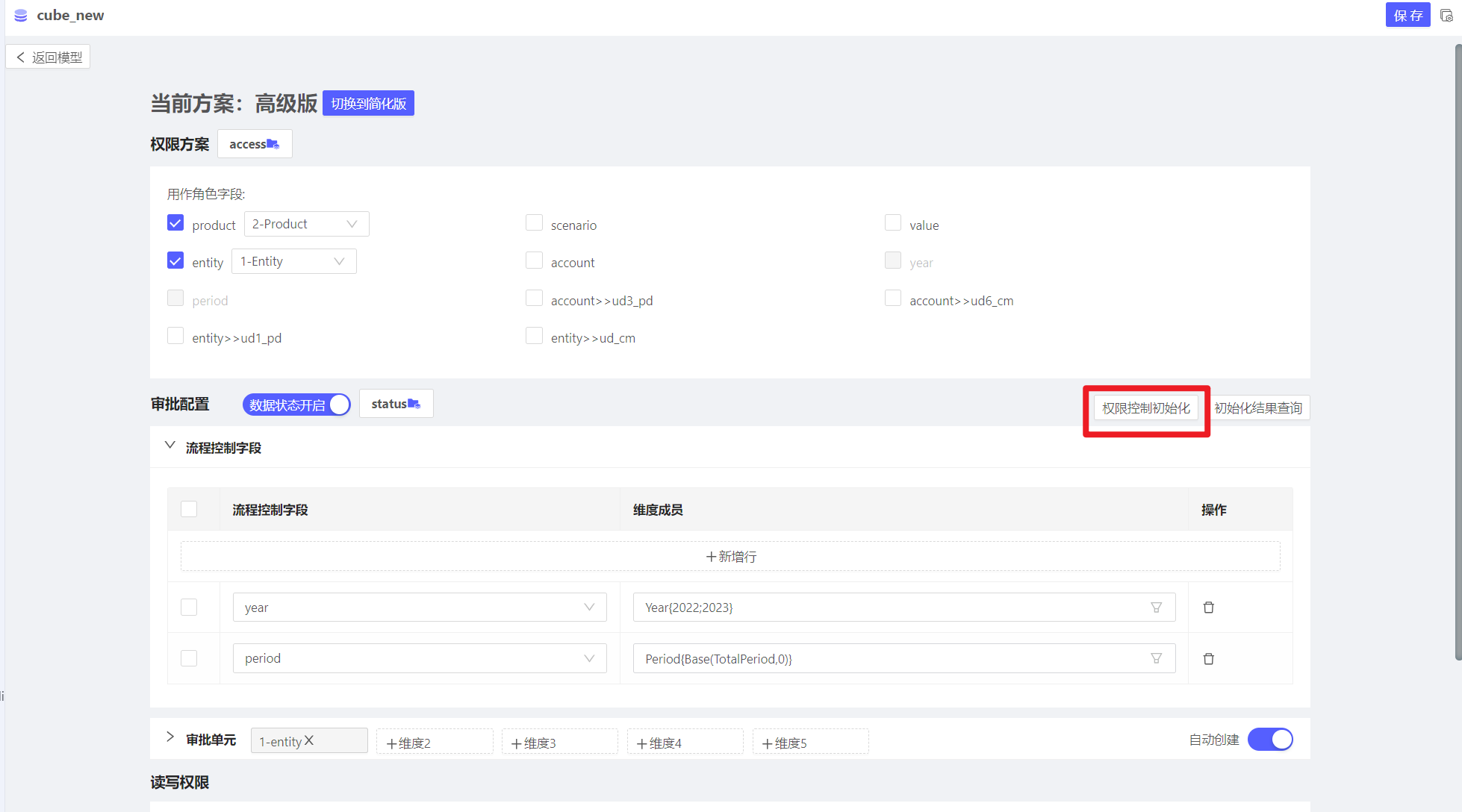
新增加的公司并且已经在权限方案里面配置了权限,表格依然提示noacess

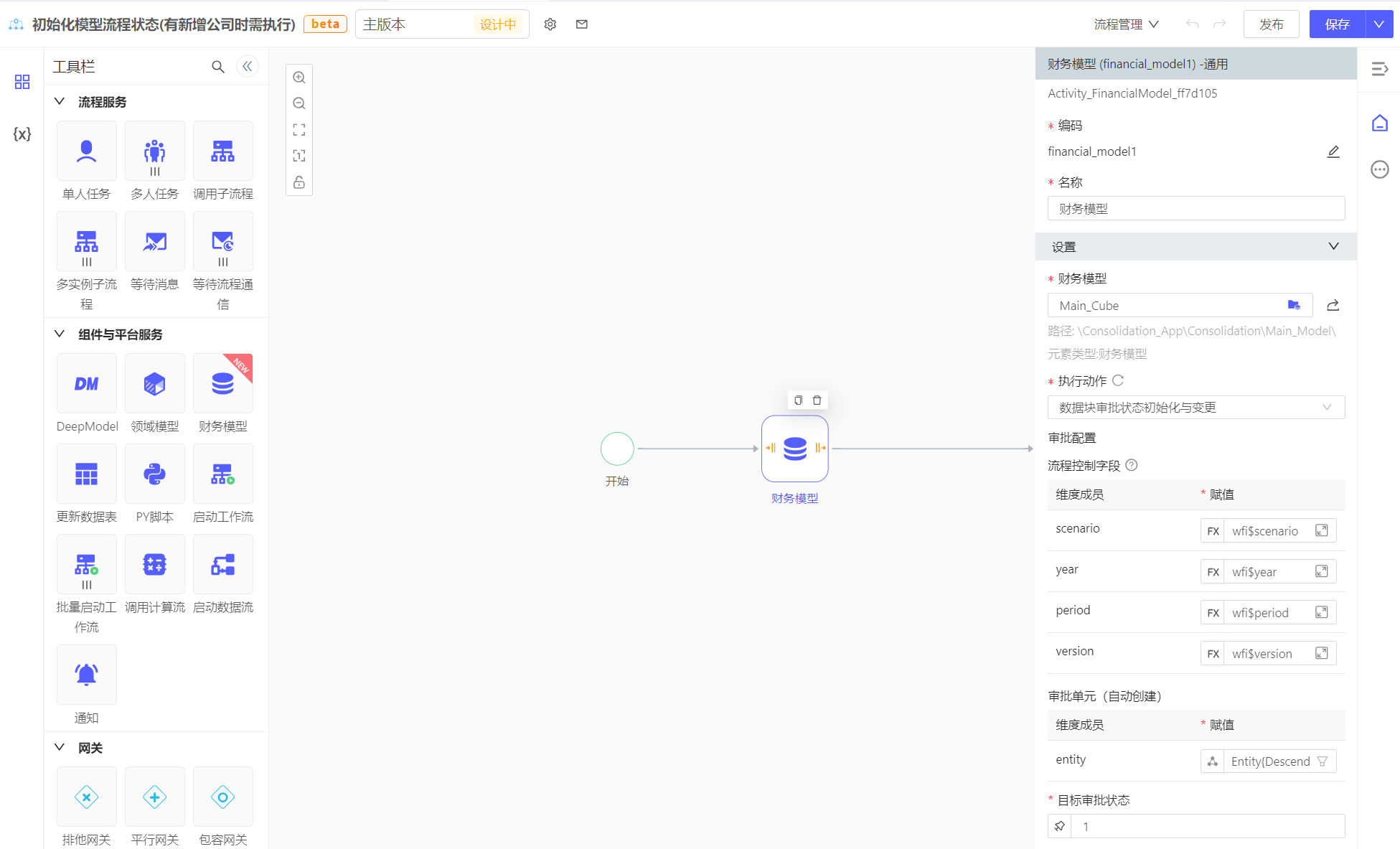
在模型点击权限控制初始化之后,会生成如下权限控制单元状态表(基于此表中的process_status值控制读写权限),但是新增的公司不会自动同步到此表中。需要手动同步
实施建议:使用工作流,在每个流程开始期间,初始化一下模型的权限表
clickhouse限制最大并发查询100

修改模型侧服务端参数
导出导入元素后,查询财务模型失败,提示维度的td表不存在
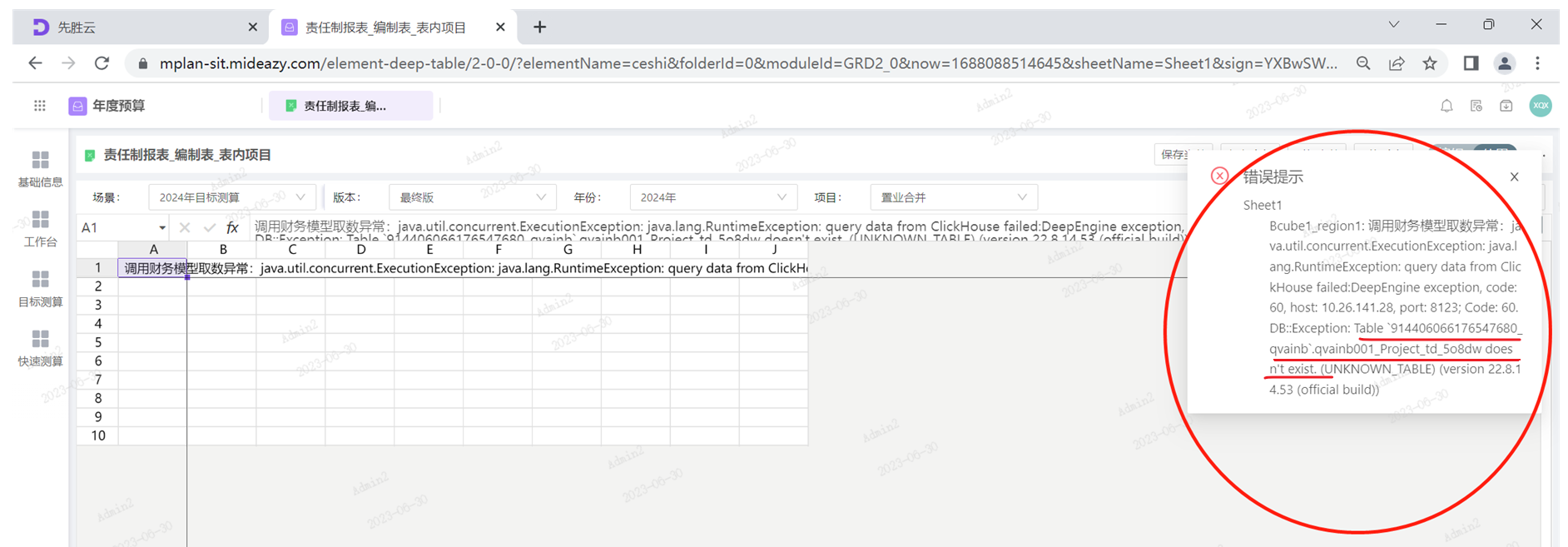
ck库中维度对应的td表在元素导入导出的过程中丢失,重新编辑保存维度,进行同步。
解释:维度的td表创建的时候是存mysql的,但是如果模型是ck,会同时在ck里同步一下。导入的时候,只导入了mysql的那个td表,ck的丢掉了。重新编辑维度的时候,会触发mysql向ck同步的过程 。
其他表都没有问题,仅某张表获取财务数据异常
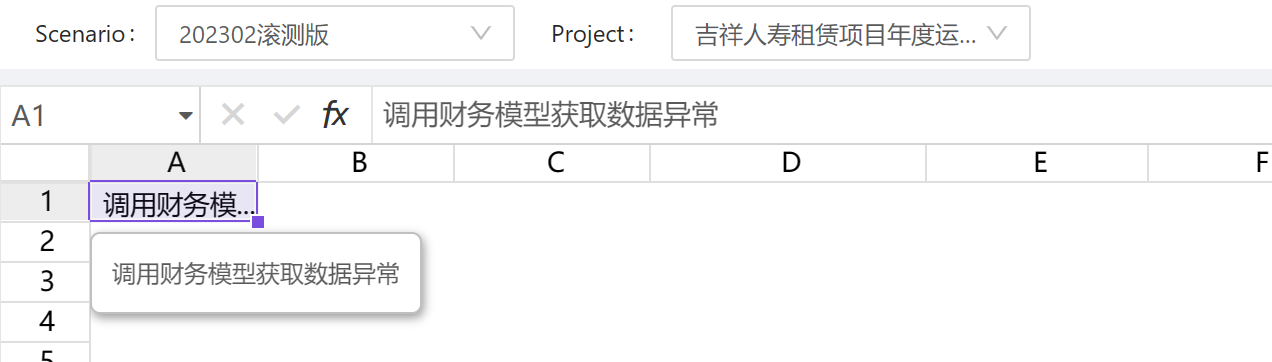
检查一下,是否某个维度成员的td表里面的层级或汇总关系不对
模型权限速查
|
权限值 |
解释 |
|---|---|
|
1 |
可写 |
|
2 |
汇总节点,属性维,view维引起的只读 |
|
3 |
可写-但是是因为维度成员特殊引起的可写(如科目维父级可写,文本类型科目) |
|
4 |
属性维只读 |
|
5 |
页面设置的只读 |
|
6 |
scenario控制的只读 |
|
7 |
当前用户因读写权限被控制的只读 |
|
8 |
当前用户无权限 |
|
9 |
会计日历只读 |
|
10 |
科目,期间做度量的只读 |
|
11 |
cube列既不是维度,度量,但作为主键时只读 |
两个用户同时开表填报数据,其中一人做了流程提交,另一个人仍然可编辑。
先胜云财务模型中,数据的查询和保存权限可以不完全一致。前面所有对于权限的配置仅指的是查询数据时的权限。对于数据保存的权限,财务模型提供了三种权鉴模式:
-
宽松模式:财务模型默认为宽松模式,此模式下只在数据查询时控制权限,数据保存时不控制。
-
严格模式:保存的数据中只要存在无权限的数据,则这一批数据均不保存。此策略在遇到无权限数据时会视为保存失败,并进行报错提醒。
-
普通模式:过滤掉无权限的数据,仅保存其中有写入权限的数据。此策略在遇到无权限数据时会静默处理,并视为保存成功。
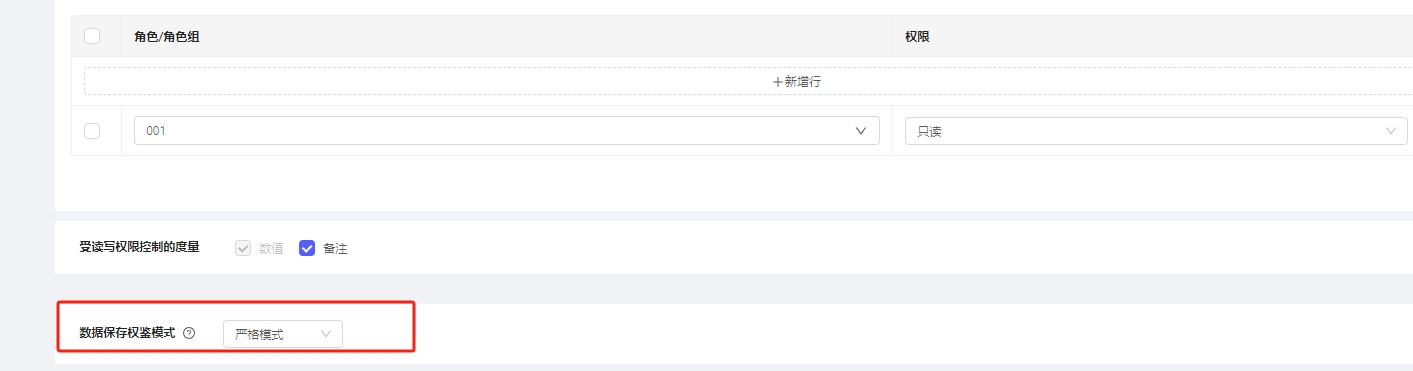
电子表格侧效果:

如上图电子表格,开表时一月份有数据,此时录入了二月数据,点击保存,三种策略效果如下:
严格模式: 在编辑过程中权限发生了变化,开表时可写,保存时只读,此时将提示单元格无编辑权限。

普通模式: 在编辑过程中权限发生了变化,开表时可写,保存时只读,此时将提示保存成功并刷新表单,但是这期间录入的无权限数据不会保存。

宽松模式: 在编辑过程中权限发生了变化,开表时可写,保存时只读,此时将提示保存成功并刷新表单,并且这期间录入的无权限数据仍然会保存。
其他
电子表格2.0支持的Excel公式
|
类型 |
涵义 |
公式示例 |
是否支持 |
常用函数 |
备注 |
|---|---|---|---|---|---|
|
数学 |
求和 |
=SUM(A1:A3) |
√ |
√ | |
|
算术平均值 |
=AVERAGE(A1:A5) |
√ |
√ | ||
|
算术平均值 |
=AVERAGEA(A1:A3) |
√ | |||
|
绝对值 |
=ABS(A1) |
√ |
√ | ||
|
取偶数 |
=EVEN(123) |
√ |
√ | ||
|
e的n次方 |
=EXP(12) |
√ | |||
|
阶乘 |
=FACT(3) |
√ | |||
|
整数 |
=INT(A1) |
√ |
√ | ||
|
最小公倍数 |
=LCM(1,2,3) |
√ | |||
|
自然对数 |
=LN(100) |
√ | |||
|
对数 |
=LOG(100,2) |
√ | |||
|
以10为底的对数 |
=LOG10(100) |
√ | |||
|
余数 |
=MOD(34,4) |
√ | |||
|
舍入到n的最近倍数 |
=MROUND(5.678,4) |
√ | |||
|
π |
=PI() |
√ | |||
|
乘幂 |
=POWER(2,7) |
√ |
√ | ||
|
乘积 |
=PRODUCT(12,26,39) |
√ | |||
|
随机数 |
=RAND()*1000 |
√ |
√ | ||
|
随机数 |
=RANDBETWEEN(1000,9999) |
√ |
√ | ||
|
四舍五入 |
=ROUND(21.5,-1) |
√ |
√ | ||
|
向下舍入数字 |
=ROUNDDOWN(31415.92654,-2) |
√ |
√ | ||
|
向上舍入数字 |
=ROUNDUP(31415.92654,-2) |
√ |
√ | ||
|
幂级数的和 |
=SERIESSUM(12,3,2,6) |
√ | |||
|
判断正负号 |
=SIGN(56.1) |
√ | |||
|
平方根 |
=SQRT(81) |
√ |
√ | ||
|
pi的平方根 |
=SQRTPI(1) |
√ | |||
|
包含数字的单元格个数 |
=COUNT(A1:A7) |
√ |
√ | ||
|
非空单元格个数 |
=COUNTA(A1:A7) |
√ |
√ | ||
|
空单元格个数 |
=COUNTBLANK(A1:A7) |
√ | |||
|
满足条件的单元格个数 |
=COUNTIF(A1:A6,10) |
√ |
√ | ||
|
分类汇总 |
=SUBTOTAL(9,A1:A6) |
√ |
√ | ||
|
分类汇总不含隐藏 |
=SUBTOTAL(109,B36:B39) |
! | |||
|
满足条件求和 |
=SUMIF(A1:A5,10,A1:A5) |
√ |
√ | ||
|
满足多个条件求和 |
=SUMIFS(A2:A7,I2:I7,I2) |
√ |
√ | ||
|
数组乘积的和 |
=SUMPRODUCT(A2:A3,A4:A5) |
√ |
√ | ||
|
平方和 |
=SUMSQ(A1:A3) |
√ | |||
|
统计 |
数组的峰值 |
=KURT(A1:A7) |
√ |
尾差 | |
|
第n个最大值 |
=LARGE(A1:A6,2) |
√ | |||
|
最大值 |
=MAX(A1:A7) |
√ |
√ | ||
|
最大值 |
=MAXA(A1:A5) |
√ | |||
|
中值 |
=MEDIAN(A1:A5) |
√ | |||
|
最小值 |
=MIN(A1:A7) |
√ |
√ | ||
|
最小值 |
=MINA(A1:A7) |
√ | |||
|
第n个最小值 |
=SMALL(A1:A5,3) |
√ | |||
|
按最高值排名 |
=RANK_EQ(A2,1:6,0) |
! |
excel是Rank.EQ | ||
|
按最平均值排名 |
=RANK_AVG(A2,1:6,0) |
! |
excel是Rank.AVG | ||
|
数据偏差的平方和 |
=DEVSQ(A1:A5) |
√ | |||
|
相关系数 |
=CORREL(A1:A3,A4:A6) |
√ |
尾差 | ||
|
平均绝对偏差 |
=AVEDEV(A1:A5) |
√ | |||
|
正态分布概率值 |
=STANDARDIZE(62,60,10) |
√ | |||
|
样本标准差 |
=STDEV(A1:A5) |
× |
用STDEVA | ||
|
样本标准差 |
=STDEVA(A1:A5) |
√ | |||
|
样本总体标准差 |
=STDEVP(A1:A5) |
√ | |||
|
样本总体标准差 |
=STDEV.P(A1:A5) |
× |
用STDEVP | ||
|
样本方差 |
=VAR(A1:A5) |
× |
用VARA | ||
|
样本方差 |
=VARA(A1:A5) |
√ | |||
|
样本总体方差 |
=VARP(A1:A5) |
× | |||
|
样本总体方差 |
=VAR_P(A1:A5) |
√ |
Excel是VAR.P | ||
|
样本总体方差 |
=VARPA(A1:A5) |
√ | |||
|
FISHER变换值 |
=FISHER(0.55) |
√ | |||
|
FISHER逆变换值 |
=FISHERINV(0.765) |
√ | |||
|
字符串 |
双字节转换为单字节 |
=ASC(apple) |
× | ||
|
单字节转换为双字节字符 |
=WIDECHAR(“apple”) |
× | |||
|
字符集 |
=CHAR(56) |
√ | |||
|
删除非打印字节 |
=CLEAN(CHAR(7)&”text”&CHAR(7)) |
√ | |||
|
返回第一个字符的数字代码 |
=CODE(“Alphabet”) |
√ | |||
|
检测文本 |
=T(“123ancde”) |
√ | |||
|
数据格式 |
=TEXT(“123456.78”,”#,##0.00”) |
√ |
√ | ||
|
删除空格 |
=TRIM(A1) |
√ | |||
|
拼接字符串 |
=CONCATENATE(A1,A2) |
√ | |||
|
拼接字符串 |
=A1&A2 |
√ | |||
|
转换为货币格式 |
=RMB(1586.567,2) |
√ | |||
|
比较字符串是否相同 |
=EXACT(A1,A2) |
√ | |||
|
小写 |
=LOWER(“ABcefDFF”) |
√ |
√ | ||
|
首字母大写 |
=PROPER(“ABcefDFF”) |
√ | |||
|
大写 |
=UPPER(“apple”) |
√ |
√ | ||
|
字符串长度 |
=LEN(A1) |
√ |
√ | ||
|
从左返回n长度字符串 |
=LEFT(A1,2) |
√ |
√ | ||
|
从中间数,返回字符串 |
=MID(A1,3,2) |
√ |
√ | ||
|
从右返回n长度字符串 |
=RIGHT(A1,2) |
√ |
√ | ||
|
查找起始位置 |
=FIND(“件”,”软件好”,1) |
√ |
√ | ||
|
查找起始位置 |
=FINDB(“件”,”软件好”,1) |
√ | |||
|
按指定的小数位数进行取整 |
=FIXED(A1,2,1) |
√ | |||
|
替换 |
=REPLACE(A1,3,3,A2) |
√ |
√ | ||
|
重复 |
=REPT(“软件报”,2) |
√ | |||
|
查找 |
=SEARCH(“3”,A1) |
√ |
√ | ||
|
查找(基于字节) |
=SEARCHB(“3”,A1) |
× | |||
|
替换 |
=SUBSTITUTE(A1,”3”,A2,1) |
√ | |||
|
逻辑 |
与 |
=AND(A1<B4,A2<B4) |
√ |
√ | |
|
非 |
=NOT(A1’=A2) |
√ |
√ | ||
|
或 |
=OR(A1+A2>A2,A1’=A2) |
√ |
√ | ||
|
真 |
=TRUE() |
√ | |||
|
假 |
=FALSE() |
√ | |||
|
判断 |
=IF(A1>’=85,”A”,IF(A1>’=70,”B”,IF(A1>’=60,”C”,IF(A1<60,”D”)))) |
√ |
√ | ||
|
是否错误 |
=IFERROR(A1,0) |
√ |
√ | ||
|
是否错误值 #N/A |
=IFNA(A1,0) |
× |
用ISNA替代 | ||
|
是否空 |
=ISBLANK(D98) |
√ | |||
|
是否错误值 #N/A |
=ISNA(A99) |
√ | |||
|
是否非文本 |
=ISNONTEXT(D100) |
√ | |||
|
是否数字 |
=ISNUMBER(D101) |
√ |
√ | ||
|
是否错误 |
=ISERROR(D102) |
√ |
√ | ||
|
转换为数值 |
=N(A1) |
√ |
√ | ||
|
将可识别的日期、时间或数字字符串转换为数值 |
=VALUE(“1,000”) |
√ |
√ | ||
|
大于 |
=1>-2 |
√ |
√ | ||
|
不等于 |
=1<>-2 |
√ |
√ | ||
|
是否空 |
=D105=”” |
√ |
√ | ||
|
查找 |
单元格坐标 |
=ADDRESS(1,4,4,1) |
√ | ||
|
对单元格或单元格区域的引用 |
=AREAS(A1:A5) |
× | |||
|
列号 |
=COLUMN(A3) |
√ |
√ | ||
|
列数量 |
=COLUMNS(B1:C4) |
√ | |||
|
行号 |
=ROW(A6) |
√ |
√ | ||
|
行数量 |
=ROWS(A1:A9) |
√ | |||
|
索引 |
=INDEX(A3:A5,1,1) |
√ |
√ | ||
|
返回引用的单元格 |
=INDIRECT(“A3”) |
√ |
√ | ||
|
偏移 |
=SUM(OFFSET(A1:A2,2,0,2,1)) |
√ |
√ | ||
|
查找 |
=LOOKUP(10,A1:A4) |
√ |
√ | ||
|
横向查找 |
=VLOOKUP(10,A1:A4,1,0) |
√ |
√ | ||
|
纵向查找 |
=HLOOKUP(“公式”,A1:F2,2,0) |
√ |
√ | ||
|
匹配 |
=MATCH(10,A1:A5,0) |
√ |
√ | ||
|
时间 |
日期 |
=DATE(2001,1,1) |
√ |
√ | |
|
日期序列 |
=DATEVALUE(“2001/3/5”) |
√ |
√ | ||
|
年 |
=YEAR(“2000/8/6”) |
√ |
√ | ||
|
月 |
=MONTH(“2001/02/24”) |
√ |
√ | ||
|
日 |
=DAY(“2001/1/27”) |
√ |
√ | ||
|
小时 |
=HOUR(“3:30:30 PM”) |
√ | |||
|
分钟 |
=MINUTE(“15:30:00”) |
√ | |||
|
秒 |
=SECOND(“3:30:26 PM”) |
√ | |||
|
星期几 |
=WEEKDAY(“2001/8/28”,2) |
√ |
√ | ||
|
日期差 |
=DAYS(“1998/2/1”,”2001/2-1”) |
√ | |||
|
按360天计算的日期差 |
=DAYS360(“1998/2/1”,”2001/2/1”) |
√ | |||
|
两个日期之间的天数、月数或年数 |
=DATEDIF(“1998/2/1”,”2001/2/1”,”D”) |
√ | |||
|
增加n月之后的日期序列 |
=EDATE(“2001/3/5”,2) |
√ | |||
|
某月的最后一天 |
=EOMONTH(“2001/01/01”,2) |
√ | |||
|
=NETWORKDAYS(“2020-01-01”,”2020-12-31”,1) |
√ | ||||
|
时间 |
=TIME(12,10,30) |
√ | |||
|
时间值 |
=TIMEVALUE(“3:30 AM”) |
√ | |||
|
此刻时间 |
=NOW() |
√ |
√ | ||
|
此刻日期 |
=TODAY() |
√ | |||
|
工作日 |
=WORKDAY(“2020-01-01”,23,1) |
√ |
√ |
电子表格1.0 和 电子表格2.0的区别
|
项目 |
电子表格2.0 |
电子表格1.0 |
|---|---|---|
|
业务控件 |
支持动态表(相当于原透视表)、DF公式(相当于原静态表)、浮动行表(相当于原清单表)、筛选器、数据源、按钮、计算脚本 |
无控件概念,sheet类型分为动态表、静态表、清单表 |
|
多区域特性 |
☆同一个sheet可以混搭多种控件,动态表/浮动行表+假表头+Excel公式,丰富编表手段 |
一个sheet只能一种类型报表 |
|
底层表格控件 |
☆开源代码,改为自用代码 |
SpreadJS,葡萄城产品,授权使用 |
|
筛选器特性 |
筛选器作为独立控件 |
筛选器非独立控件,是动态表、静态表、清单表的一部分 |
|
动态表特性 |
基本财务模型透视 |
基本财务模型透视 |
|
DF公式特性 |
按单元格配置财务模型取数 |
按单元格配置财务模型取数 |
|
浮动行表特性 |
☆拆分数据源和展现层控件,一个数据源可以编制多张报表 |
可使用sql查询条件:where sort order join |
|
展现层权限 |
☆Sheet锁定/隐藏 |
无 |
|
跳转配置 |
☆跳转+传参到其他元素 |
需自定义JS开发 |
|
类Excel功能(不区分控件,通用功能) |
☆条件格式 |
需自定义JS开发 |
|
计算脚本 |
Python |
Python |
|
批量下载 |
☆集成到UX,支持批量下载 |
需自定义JS开发 |
|
即席分析 |
☆线上即席分析 |
无 |
注:☆为新增功能
回到顶部
咨询热线
400-821-9199
